Qaasid News
Download Our App
Latest News
Why Vera cofounder Yaniv Bernstein was surprised when he said he was giving up AI
April 2, 2026
FBR moves to tax social media earnings, seeks expert input
April 2, 2026
IMF flags Pakistan over further extension of petroleum subsidies – samaa tv
April 2, 2026
Stock market today: Live updates
April 2, 2026
Petroleum subsidy will adjust with global prices, govt tells IMF – samaa tv
April 2, 2026
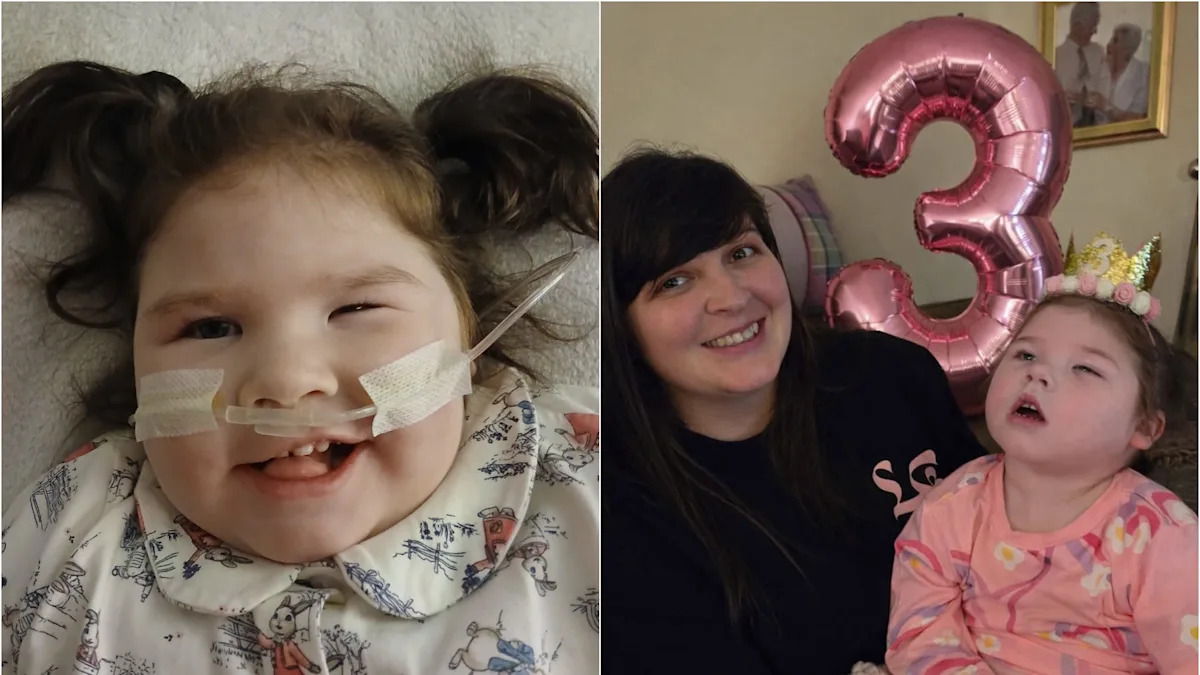
‘Our daughter has a rare one-in-100,000 condition and nearly died twice – celebrating her third birthday was monumental’
April 2, 2026
Physicists just solved a strange fusion mystery that stumped experts
April 2, 2026
TV tonight: globetrotting smash-hit Race Across the World returns | Television
April 2, 2026
LA28 Announces Verified Multi-Platform Ticket Resale Program Opening in 2027
April 2, 2026
Reconstructing a bike crash from Google Street View
April 2, 2026