This request seems a bit unusual, so we need to confirm that you’re human. Please press and hold the button until it turns completely green. Thank you for your cooperation!
SAN JOSE, Calif. — October 22, 2025 — QuantumScape Corporation (NYSE: QS), a global leader in next-generation solid-state lithium-metal battery technology, today announced that it has begun shipping B1 samples of its QSE-5 cell. The company reached this milestone during the third quarter of 2025, achieving one of the company’s key goals for the year.
These samples are the most advanced QS cells to date and feature separators produced using the company’s groundbreaking Cobra process. By combining the high-performance QSE-5 design with more efficient production processes, these cells represent a major step toward high-volume commercial production of QS technology for electric vehicles and other applications.
Cobra-based QSE-5 cells are featured in QS’s first vehicle program with the VW Group, the Ducati V21L motorcycle. The Ducati program is designed as a real-world demonstration of the no-compromise performance profile of QS solid-state battery technology.
This cell shipment milestone reflects QS’s commitment to executing on its roadmap and advancing next-generation battery technology. In a further step toward bringing QS technology to scale and achieving automotive-grade reliability, the company is installing a highly automated cell production pilot line, the Eagle Line, at its headquarters in San Jose, California.
“We are proud to announce the start of deliveries of these QSE-5 samples,” said Dr. Luca Fasoli, Chief Operating Officer of QS. “We are working together with our partners to bring our groundbreaking solid-state lithium-metal battery technology to market as quickly as possible. This announcement is another critical step toward achieving our goal of revolutionizing energy storage.”
###
About QuantumScape Corporation
QuantumScape is on a mission to revolutionize energy storage to enable a sustainable future. The company’s next-generation solid-state lithium-metal battery technology is designed to enable greater energy density, faster charging and enhanced safety to support the transition away from legacy energy sources toward a lower carbon future. For more information, visit www.quantumscape.com.
Forward-Looking Statements
Certain information in this press release may be considered “forward-looking statements,” within the meaning of Section 27A of the Securities Act of 1933, as amended, and Section 21E of the Securities Exchange Act of 1934, as amended, including, without limitation, statements regarding the development, commercialization, and high-volume scale-up of QS’s battery technology, the anticipated benefits from successful installation and operation of production equipment for the Eagle Line, including battery cell reliability and increased production automation, the performance of QS’s technology and its applications, the achievement of technical milestones and goals, and the potential impacts of QS’s technology for electric vehicles and other applications, among others. These forward-looking statements are based on management’s current expectations, assumptions, hopes, beliefs, intentions and strategies regarding future events and are based on currently available information as to the outcome and timing of future events. Because forward-looking statements are inherently subject to risks and uncertainties, some of which cannot be predicted or quantified, you should not rely upon forward-looking statements as predictions of future events. The events and circumstances reflected in the forward-looking statements may not be achieved or occur and actual results could differ materially from those projected in the forward-looking statements due to various risks, including the successful development and commercialization of our solid-state battery technology, achieving technical and financial milestones, building out of high-volume processes and otherwise scaling production, achieving the performance, quality, consistency, reliability, safety, cost and throughput required for commercial production and sale, changes in economic and financial conditions, market demand for EVs, retaining key personnel, competition, regulatory changes, broader economic conditions, and other factors, including those discussed in the section titled “Risk Factors” in our Annual Report and Quarterly Reports and other documents filed with the Securities and Exchange Commission from time to time. Except as otherwise required by applicable law, the company disclaims any duty to update any forward-looking statements.
Long Beach, Calif. October 22, 2025 – Rocket Lab Corporation (Nasdaq: RKLB) (“Rocket Lab” or “the Company”), a global leader in launch services and space systems, today announced the clearance of their Systems Integration Review (SIR) and completion of their Photon spacecraft for Eta Space and NASA’s LOXSAT mission. LOXSAT is an on-orbit technology demonstration of a cryogenic fluid management system, that will inform the design of Cryo-Dock, a full-scale cryogenic propellant depot in low Earth orbit to be operational in 2030.
The SIR, completed in September, marked a key milestone for the program, allowing the team to proceed with payload integration. Rocket Lab will now move the mission into environmental testing – the next phase before its launch on Electron in early 2026.
Rocket Lab was selected in 2020 by Eta Space to provide both the spacecraft and its Electron launch vehicle for the LOXSAT mission, joining a growing list of spacecraft-plus-launch mission solutions supported by the Company, including the CAPSTONE lunar mission for NASA and the upcoming VICTUS HAZE mission for the U.S. Space Force. Rocket Lab’s end-to-end capabilities simplify mission execution and minimize cost and schedule risks, providing customers with a single, responsive space solutions partner for a wide range of mission objectives.
“We’re proud to be both the spacecraft and launch provider for LOXSAT and for the opportunity to show Rocket Lab’s true end-to-end space systems capabilities,” said Brad Clevenger, Vice President of Space Systems. “With LOXSAT, we’re supporting a critical technology demonstration that will enable key steps toward making orbital propellant depots a reality. The ability to refuel in space is fundamental to unlocking reusable and sustainable exploration beyond Earth’s orbit. With the spacecraft build and payload integration complete, our team is focused on environmental testing ahead of its launch on Electron.”
“We are excited to reach this milestone”, said Bill Notardonato, CEO of Eta Space. “We chose Rocket Lab as a launch provider based on their proven Electron rocket and the chance to have a dedicated launch to our exact orbit on our schedule. But their spacecraft experience and payload hosting services have proven to be just as valuable as launch services for our project success.”
Despite being one of the most efficient and energetic propellants for spacecraft, cryogenic propellants can vaporize as temperature rises, causing critical loss on orbit. LOXSAT will test the ability to store liquid oxygen (LOX) in a zero-loss configuration, with the goal of creating a larger scale model in the future that could serve as a commercial cryogenic propellant depot in space. This would enable reuse and refueling of spacecraft on orbit.
The basis of the spacecraft is the Company’s Photon platform, which gained flight heritage in 2022 with NASA’s CAPSTONE mission to the Moon. LOXSAT was designed and built using Rocket Lab’s vertically integrated components and systems, including star trackers, propulsion systems, reaction wheels, solar panels, flight software, radios, composite structures, tanks, separation systems, and more. The spacecraft was produced and will undergo environmental testing at the Company’s Spacecraft Production Complex and headquarters in Long Beach, California, and will ultimately be launched from Rocket Lab Launch Complex 1 in New Zealand.
The LOXSAT mission is sponsored by NASA’s Tipping Point program that aims to advance technologies that could support human space exploration in the future.
###
Rocket Lab Media Contact Lindsay McLaurin media@rocketlabusa.com
+ About Rocket Lab
Rocket Lab is a leading space company that provides launch services, spacecraft, payloads, and satellite components serving commercial, government, and national security markets. Rocket Lab’s Electron rocket is the world’s most frequently launched orbital small rocket; its HASTE rocket provides hypersonic test launch capability for the U.S. government and allied nations; and its Neutron launch vehicle in development will unlock medium launch for constellation deployment, national security and exploration missions. Rocket Lab’s spacecraft and satellite components have enabled more than 1,700 missions spanning commercial, defense and national security missions including GPS, constellations, and exploration missions to the Moon, Mars, and Venus. Rocket Lab is a publicly listed company on the Nasdaq stock exchange (RKLB). Learn more at www.rocketlabcorp.com.
+ About Eta Space Eta Space is a technology development company founded in 2019 by former NASA personnel. Named after the Greek letter η — symbolizing efficiency — Eta Space develops advanced cryogenic systems for space exploration and the future hydrogen energy economy. From the lunar surface to local airports, Eta Space is Fueling Future Exploration with cutting-edge solutions that push the boundaries of efficiency and innovation. Learn more at etaspace.com.
+ Forward Looking Statements
This press release contains forward-looking statements within the meaning of the Private Securities Litigation Reform Act of 1995. We intend such forward-looking statements to be covered by the safe harbor provisions for forward looking statements contained in Section 27A of the Securities Act of 1933, as amended (the “Securities Act”) and Section 21E of the Securities Exchange Act of 1934, as amended (the “Exchange Act”). All statements contained in this press release other than statements of historical fact, including, without limitation, statements regarding our launch and space systems operations, launch schedule and window, safe and repeatable access to space, Neutron development, operational expansion and business strategy are forward-looking statements. The words “believe,” “may,” “will,” “estimate,” “potential,” “continue,” “anticipate,” “intend,” “expect,” “strategy,” “future,” “could,” “would,” “project,” “plan,” “target,” and similar expressions are intended to identify forward-looking statements, though not all forward-looking statements use these words or expressions. These statements are neither promises nor guarantees, but involve known and unknown risks, uncertainties and other important factors that may cause our actual results, performance or achievements to be materially different from any future results, performance or achievements expressed or implied by the forward-looking statements, including but not limited to the factors, risks and uncertainties included in our Annual Report on Form 10-K for the fiscal year ended December 31, 2024, as such factors may be updated from time to time in our other filings with the Securities and Exchange Commission (the “SEC”), accessible on the SEC’s website at www.sec.gov and the Investor Relations section of our website at www.rocketlabcorp.com, which could cause our actual results to differ materially from those indicated by the forward-looking statements made in this press release. Any such forward-looking statements represent management’s estimates as of the date of this press release. While we may elect to update such forward-looking statements at some point in the future, we disclaim any obligation to do so, even if subsequent events cause our views to change.
This request seems a bit unusual, so we need to confirm that you’re human. Please press and hold the button until it turns completely green. Thank you for your cooperation!
Baker McKenzie advised ResInvest Group on the acquisition of Onyx Power Group from Riverstone Holdings LLC. The closing of the transaction is subject to customary approvals. Onyx Power Group is a European energy supply company and an expert in the safe and weather-independent provision of electricity and heat. Onyx Power Group has six power plants in Germany and the Netherlands with a total net capacity of 1.65 GW. The portfolio includes some of the most modern thermal power plants in Europe, which combine high efficiency with low emissions. The most important locations include Wilhelmshaven, Rotterdam, Zolling and Farge near Bremen.
“With our experienced, international team, we were able to support our client in further expanding its position in the European energy market”, commented Holger Engelkamp, Corporate/M&A Partner in Berlin. “The transaction also gives our client the opportunity to tackle important transformation projects for the German energy market”, adds Dr. Claire Dietz-Polte, energy law partner in Berlin, who led the transaction together with Holger Engelkamp and heads the German energy and infrastructure practice with him.
ResInvest Group is an international trading and investment company that supplies essential commodities for the global markets. The company has extensive experience in the energy sector and in the operation of conventional power plants in Europe. As a strategic investor, ResInvest Group strengthens Onyx Power’s strategy and the upcoming transformation in the context of the energy transition.
The Energy and Infrastructure team, which is part of Baker McKenzie’s corporate/M&A practice, regularly advises on domestic and international transactions. Most recently, the energy and infrastructure team advised the American company Sunoco on the acquisition of the tank terminal operator Tanquid, the Dutch battery storage investor Return on the purchase of four large-scale battery storage sites in Germany from BESSMART, the battery storage developer J+P Batterien on the entry of the Dutch battery storage investor Return and Terra One Climate Solutions on the conclusion of a framework agreement with S4 Energy. Baker McKenzie’s Corporate/M&A practice also advised AURELIUS on the acquisition of Landis+Gyr’s EMEA business; Knorr-Bremse on the acquisition of duagon Group; Cheyne Capital on the refinancing of Kaffee Partner; JD.com on the acquisition of Ceconomy; VINCI Energies on the acquisition of R + S Group and the acquisition of Zimmer & Hälbig Group; Bristol Myers Squibb on the transfer of Juno Therapeutics to TQ Therapeutics; Georg Fischer on the acquisition of VAG Group; AURELIUS on the acquisition of Teijin Automotive Technologies; Centric Software on the acquisition of Contentserv Group; Fagron Group on the acquisition of Euro OTC & Audor Pharma GmbH; Berlin Packaging, a portfolio company of Oak Hill Capital Partners and Canada Pension Plan Investment Board, on the acquisition of RIXIUS AG; and Instalco on the investment in FABRI AG.
Legaladviser to ResInvest:
Baker McKenzie
Lead:
M&A/Energy: Holger Engelkamp (partner, Berlin)
Projects/Energy: Dr. Claire Dietz-Polte (partner, Berlin)
Team:
Corporate/M&A: Ben Boi Beetz (senior associate)
Projects/Energy/Regulatory: Dr. Katharina Weiner (partner, Düsseldorf), Dr. Janet Butler, Dr. Maximilian Voll (both Counsel, Berlin), Nico Ruepp (associate, Berlin), Stefanie Zenzen (associate, Düsseldorf)
Employment / Pensions: Dr. Matthias Köhler (partner, Berlin), Dr. Verena Böhm (counsel, Frankfurt), Isabell Guntermann (associate, Berlin)
Financing: Kathrin Marchant (partner), Esther Kapern (associate, both Frankfurt)
IT/Data Protection: Florian Tannen (partner), Daniel Wulle (senior associate), Clarissa Rach (associate, all Munich), Anela Winzig (associate, Frankfurt)Antitrust/FDI: Dr. Anika Schürmann (partner), Dr. Florian Kotman (counsel, both Düsseldorf), Anahita Thoms (partner), Alexander Ehrle (senior associate, both Berlin)
The Netherlands: Mohammed Almarini (partner), Laila Kouchi (legal director), Anne van den Dorpel (associate), Anna van Bracht (partner), Lois Knijpinga (associate, Amsterdam)
Belgium: Roel Meers (partner), Arnaud Flamand (associate, both Brussels) as well as other lawyers in the Netherlands and Belgium.
About Baker McKenzie
Complex business challenges require an integrated response across different markets, sectors, and areas of law. Baker McKenzie’s client solutions provide seamless advice, underpinned by deep practice and sector expertise, as well as first-rate local market knowledge from more than 70 offices globally. Baker McKenzie works alongside clients to deliver solutions for a connected world.
Artificial intelligence (AI) is increasingly being integrated into health care, offering a wide array of benefits [-]. Current AI applications encompass patients’ diagnosis, treatment, data mining, and more to enhance patient care and quality of life. Recent breakthroughs in AI and machine learning have led to the building of reliable and safe AI systems capable of handling the complexity of health care support in disciplines such as cardiology, radiology and oncology, health information management, patient care, and workforce development. AI fast tracks results in emergency rooms, trauma units, supply chain systems, and radiology and pathology units, for example. The impact is to minimize deficiencies in human resources, provide considerable benefits for patient safety and quality of care, alleviate clinician burnout, and decrease health care costs over time.
These gains offer great transformative potential, enabling acceleration of processes in diverse areas of health care [-]. Furthermore, AI is democratizing access to expert support by providing timely and accurate disease diagnoses, better clinical management, quicker drug discovery, improved disease prevention, big data management, and enhanced health protection [,]. In addition, 23% of health care executives in the United States believe that AI and machine learning are very effective at improving clinical outcomes [].
The potential of AI to optimize resource use and boost productivity underscores its critical role in health care management and patient care. Building on this promising start necessitates striking a balance between technical advancements and management of ethical considerations. Responsible deployment of AI applications by the health care sector can lead to automated services, effective care delivery, and improved patient outcomes. This transformation requires policy support through strong governance, and for ethical concerns and regulatory issues to be addressed.
The current use of AI complements and boosts human resources and has a far-reaching impact in health management, health care worker training, and health services. Its full adoption will enhance leadership and management experiences in the delivery of care while supporting current functions and future innovations in the health care sector [,]. To ensure that health care workers are adequately equipped, skilled, and trained to use AI proficiently in health management and clinical practice, health care managers, educators, and providers must play a more proactive role in the ongoing digital revolution to ensure its effective and regular use [-]. Furthermore, health care leaders should actively promote the translation of innovation and research findings into health care management and delivery practices [,]. This will help revolutionize health care management, improve resource use, advance precision medicine, institutionalize operational efficiency, automate processes, and maximize predictive analytics [].
Understanding AI adoption, progression, characteristics of early adopters, barriers to adoption, the extent to which and why individuals support AI adoption, and the role played by different levels of health management or leadership will inform future AI-related programs and policies. This will enable the global health care sector to adopt new management or leadership styles and organizational structures to harness the potential of AI effectively []. This study aimed to garner viewpoints from across the world on AI adoption in health care, its usefulness in patient care and health management or leadership, and the characteristics of early AI adopters.
Methods
Study Design
We conducted a worldwide cross-sectional survey using a self-administered questionnaire developed with the Qualtrics electronic data collection tool, targeting senior health care professionals for their opinions on the use of AI in the health care sector. The questionnaire included sections on AI adoption, deployment, use, benefits and barriers to AI adoption, as well as basic, anonymized demographic information of the participants (). We piloted and reviewed the questionnaire to ensure completeness, accuracy, acceptability, cultural sensitivity, and relevance. The questionnaire and subsequent data analysis complied with the protocol and checklist outlined in CHERRIES (Checklist for Reporting Results of Internet E-Surveys) [] ().
The study population comprised health care executives, health care leaders, and service providers drawn from the 6 inhabited continents of the world (North and South America, Asia, Africa, Australia or Oceania, and Europe). We used a population prevalence of 23% and a confidence level of 95% to arrive at a sample size of 273 [,].
Health care executives and providers were identified through a convenience sampling technique of professional associations or organizations, social media platforms, and professional networks. The survey was sent to over 500 health care professionals, using their personalized email addresses. We also used professional networks to distribute the questionnaire, and anyone who received the questionnaire link could participate in the study. Participants were informed in the invitation email of the nature of the study, the length of time necessary to complete the questionnaire (less than 10 minutes), and the identity of the principal investigator (OOO). Participants were also informed that fully anonymized information would be collected and stored for 6 months behind a firewall and that no personal, traceable, or identifiable data would be collected. A link was provided in the email to the questionnaire, which required a “1-time only” password to prevent multiple completions of the questionnaire by individual participants.
Participation was voluntary with no incentives offered, and data collection occurred over a 7-week period from October 1 to November 19, 2024. The questionnaire was formatted over 16 pages with 1 to 2 questions per page and hosted on the Qualtrics website for the duration of the study. Participants were able to check for completeness and could review their answers using a “back button.” If participants were unsure or unwilling to disclose their responses, options including “not sure,” “not applicable,” or “prefer not to say” were available. According to the Qualtrics assessment, the study had a 99% completion rate for those persons who received the email, accessed the link, and started to complete the questionnaire.
After closure of the survey, data analysis was performed on anonymized, submitted questionnaires using SPSS (version 27; IBM Corp) and Microsoft Excel. Data were uploaded automatically by Qualtrics, rather than being uploaded manually for analysis. Descriptive and comparative analyses were conducted including frequencies, percentages, and chi-squares. A P value of <.05 was considered significant. To maintain participants’ anonymity, data were aggregated prior to analysis. Results are presented in tables, charts, and as narrative formats for clarity and comprehension.
Ethical Considerations
Ethics approval was received from the California State University, Dominguez Hills Institutional Review Board (IRB) following an IRB approval application (CSUDH IRB-FY2024-66). An information sheet was provided before completion of the questionnaire, informing participants of the survey duration (up to 10 minutes), how the data were to be used, and that participation was optional and asking whether each participant was willing to proceed on that basis. Informed consents were obtained from participants before access to the questionnaire was given. Before completing the study, participants consented to their responses being used in an anonymized, aggregated fashion for medical research purposes and for subsequent secondary data analysis only. Only anonymized data were collected with no traceable information to the individual participants. The data were kept behind an institutional firewall at California State University, Dominguez Hills. Prior parental informed consent was requested in the event that a participant was under the age of consent. However, there was no participant younger than 18 years of age included in the study. No compensation was given for participating in this study.
Results
Overview
A total of 506 health care leaders and service providers participated in the survey. Most participants were drawn from Africa, North America, and Europe. The sex distribution was nearly equal, with the male population accounting for 47.8% (181/379) and the female population for 49.1% (186/379) of respondents. The rest were nonbinary or third sex (2/379, 0.5%), others (1/379, 0.3%), and those who preferred not to disclose their sex (9/379, 2.4%). Most participants (265/376, 70.5%) were between the ages of 30 and 59 years. Regarding level of education, 87.3% (331/379) were university graduates, with 71.5% (271/379) holding an advanced degree—a master’s degree (146/379, 38.5%) or a doctorate (125/379, 33%)—as their highest qualification.
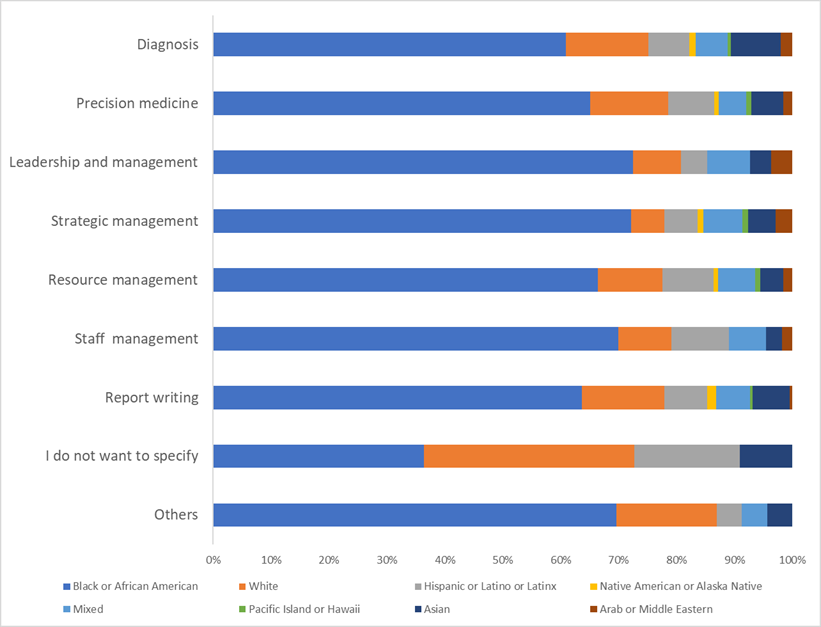
In terms of professional experience, respondents were evenly distributed, with similar proportions having less than 10 years and 25 years or more. Approximately half (195/377, 51.7%) were affiliated with federal, state, or college or university systems, and 44.7% (226/506) worked in the health care services, while 28.3% (143/506) were affiliated with the educational sector. Over half (200/373, 53.6%) of the respondents were identified as Black or African American people. Geographically, the majority were based in Africa (159/373, 42.6%), North America (130/373, 34.9%), or Europe (49/373, 13.1%), as outlined in . Black or African American constituted the largest population of respondents (200/373, 53.6%), followed by White (55/373, 14.7%).
To the question “Do you think AI has any role or usefulness in health care practice and management?” 92.3% (467/506) responded Yes. Of these, 58.7% (254/433) were of the view that AI is very (179/433, 41.3%) or extremely (75/433, 17.3%) important. In the near future, 79.8% (375/470) were of the view that AI will be very (199/470, 42.3%) or extremely (176/470, 37.4%) useful ().
A total of 95.6% (173/181) of male participants, 91.9% (171/186) of female participants, 95.6% (154/159) of those from Africa, 93.9% (46/49) of those from Europe, 87.7% (114/130) of those from North America, 95.5% (191/200) of those who identified as Black or African American, 92.7% (51/55) of White, and 86.7% (26/30) of Hispanic or Latino participants stated that AI was useful for health management and patient care. There was a significant difference in the responses of male participants versus female participants (P<.001), organizational affiliations (P=.01), and continent of residence or operation (P=.03; -). Similarly, 87.8% (173/181) of male, 75.3% (140/186) of female, African (147/159, 92.5%), Black or African American (178/200, 89%), European (38/49, 77.6%), Hispanic or Latino (19/30, 63.3%), North American (87/130, 66.9%), and White (40/55, 72.7%) participants were of the view that AI is very or extremely useful in health; however, only sex (P=.01) and the continent of residence or operation (P=.001) showed a significant difference.
Table 1. Demographic characteristics of respondents.
Description
Values, n (%)
Sexat birth (n=379)
Male
181 (47.8)
Female
186 (49.1)
Nonbinary or third sex
2 (0.5)
Others
1 (0.3)
Prefer not to say
9 (2.4)
Age in completed years (n=376)
<20
4 (1.1)
20-29
45 (12)
30-39
89 (23.7)
40-49
104 (27.7)
50-59
72 (19.1)
>60
62 (16.5)
Highest educational qualification (n=379)
High school diploma or General Educational Development
26 (6.9)
Bachelors
60 (15.8)
Masters
146 (38.5)
Doctorate
125 (33)
Other
17 (4.5)
Prefer not to specify
5 (1.3)
Length of experience in health care (years; n=372)
<5
85 (22.8)
5-9
54 (14.5)
10-14
61 (16.4)
15-19
40 (10.8)
20-24
50 (13.4)
>25
82 (22)
Affiliation (n=377)
Federal or state government facility or institution
100 (26.5)
County or local government facility or institution
24 (6.4)
College or university
95 (25.2)
Nonprofit or public charity
56 (14.9)
Private facility or institution
67 (17.8)
Other
35 (9.3)
Professional track (select all that apply)a (n=506)
Health care services
226 (44.7)
Health education
143 (28.3)
Health informatics
45 (8.9)
Health technology
32 (6.3)
Health administration or management
120 (23.7)
Other
67 (13.2)
Race or ethnicity (n=373)
Arab or Middle-Eastern
6 (1.6)
Asian (East and South)
25 (6.7)
Black or African American
200 (53.6)
Hispanic or Latino or Latinx
30 (8)
Native American or Alaskan Native
3 (0.8)
Pacific Islander or Hawaiian
1 (0.3)
White
55 (14.7)
Mixed
17 (4.6)
Other
19 (5.1)
Prefer not to say
17 (4.6)
Location or residence (n=373)
Africa
159 (42.6)
Europe
49 (13.1)
Asia
19 (5.1)
North America
130 (34.9)
South America
8 (2.1)
Australia or Oceania
8 (2.1)
aParticipants were able to select multiple options.
Table 2. Artificial intelligence (AI) relevance, use, and adoption in organizations.
Description
Yes, n (%)
Do you think AI has any role or usefulness in health care practice and management? (n=506)
Yes
467 (92.3)
No
13 (2.6)
Neither
26 (5.1)
If yes, how useful do you think AI is now in health care management and practice? (n=433)
Not useful
9 (2.1)
Slightly useful
61 (14.1)
Moderately useful
109 (25.2)
Very useful
179 (41.3)
Extremely useful
75 (17.3)
In the future, how useful do you think AI will be in health care management and practice? (n=470)
Not useful
4 (0.9)
Slightly useful
20 (4.3)
Moderately useful
71 (15.1)
Very useful
199 (42.3)
Extremely useful
176 (37.4)
Have you had any formal exposure or training in AI? (n=470)
Yes
142 (30.2)
No
302 (64.3)
Not sure
26 (5.5)
If yes, what kind of training or exposure did you have? (Select all that apply)a (n=142)
Basic orientation
89 (62.7)
Training in AI use in patient care (diagnosis, treatment, laboratory services, etc)
24 (16.9)
Training in AI use in management and leadership
43 (30.3)
Training in technical aspects of AI
43 (30.3)
Other forms of AI training
33 (23.2)
Has your institution or organization adopted or begun the process of AI adoption, adaptation, and use? (n=457)
Yes, we have adopted AI
60 (13.1)
Yes, we will adopt AI
36 (7.9)
Yes, we are beginning to think about adopting AI
107 (23.4)
No, we have not started adopting AI
180 (39.4)
Do not know
74 (16.2)
Has your organization trained anyone on AI use? (n=445)
Yes
93 (20.9)
No
197 (44.3)
Do not know or not sure
155 (34.8)
If staff have been trained, who benefited from the training? (n=210)
Executive leadership or top level
33 (15.7)
Management staff or mid-level
47 (22.4)
Operational staff
58 (27.6)
IT staff
44 (21)
Other
24 (11.4)
Prefer not to say
4 (1.9)
aParticipants were able to select multiple options.
Table 3. Artificial intelligence (AI) adoption and institutional capacity development by ethnicity and race.
Description
Race or ethnicity
Chi-square (df)
P value
Black or African American (200/373, 53.6%); yes, n (%)
White (55/373, 14.7%); yes, n (%)
Hispanic or Latinx (30/373, 8%); yes, n (%)
AI has a role in health care practice and management
191 (95.5)
51 (92.7)
26 (86.7)
21.8 (20)
.35
AI will be very to extremely useful in health care management and practice
178 (89)
40 (72.7)
19 (63.3)
52.3 (40)
.09
Have had formal exposure or training in AI
69 (34.5)
15 (27.3)
6 (20)
37.6 (20)
.01
The organization has adopted AI
17 (8.5)
12 (21.8)
4 (13.3)
40.6 (40)
.45
The organization has trained someone on AI use
32 (16)
14 (25.5)
4 (13.3)
13.3 (20)
.87
The participant will support AI adoption and embedding
168 (84)
39 (70.9)
17 (56.7)
35.5 (20)
.01
Table 4. Artificial intelligence (AI) adoption and institutional capacity development by geographical location.
Description
Continent
Chi-square (df)
P value
Africa (159/373, 42.6%); yes, n (%)
Europe (49/373, 13.1%); yes, n (%)
North America (130/373, 34.9%); yes, n (%)
AI has a role in health care practice and management
154 (96.9)
46 (93.9)
114 (87.7)
20.1 (10)
.03
AI will be very to extremely useful in health care management and practice
147 (92.5)
38 (77.6)
87 (66.9)
44.5 (20)
.001
Have had formal exposure or training in AI
46 (28.9)
15 (30.6)
43 (33.1)
13.4 (10)
.20
The organization has adopted AI
12 (7.5)
12 (24.5)
21 (16.2)
41.6 (20)
.003
The organization has trained someone on AI use
21 (13.2)
12 (24.5)
30 (23.1)
27.8 (10)
.002
The participant will support AI adoption and embedding
145 (91.2)
41 (83.7)
76 (58.5)
53.6 (10)
<.001
Table 5. Artificial intelligence (AI) adoption and institutional capacity development by biological sex.
Description
Sex
Chi-square (df)
P value
Male (181/379, 47.8%); yes, n (%)
Female (186/379, 49.1%); yes, n (%)
Other (12/379, 3.2%); yes, n (%)
AI has a role in health care practice and management
173 (95.6)
171 (91.9)
7 (58.3)
36.4 (8)
<.001
AI will be very to extremely useful in health care management and practice
159 (87.8)
140 (75.3)
4 (33.3)
31.7 (16)
.01
Have had formal exposure or training in AI
55 (30.4)
56 (30.1)
3 (25)
3.0 (8)
.94
The organization has adopted AI
24 (13.3)
22 (11.8)
3 (25)
26.1 (16)
.05
The organization has trained someone on AI use
38 (21)
31 (16.7)
3 (25)
9.0 (8)
.34
The participant will support AI adoption and embedding
163 (90.1)
123 (66.1)
4 (33.3)
71.3 (8)
<.001
Table 6. Comparison of key indications with chi-square analysis.
Description
Sex at birth
Age
Education
Experience
Affiliation
Race or ethnicity
Continent
Chi-square (df)
P value
Chi-square (df)
P value
Chi-square (df)
P value
Chi-square (df)
P value
Chi-square (df)
P value
Chi-square (df)
P value
Chi-square (df)
P value
AIa has a role in health care practice and management
36.4 (8)
<.001
12.1 (10)
.28
3.2 (10)
.98
14.4 (10)
.16
22.5 (10)
.01
21.8 (20)
.35
20.1 (10)
.03
AI will be very to extremely useful in health care management and practice
31.7 (16)
.01
24.9 (20)
.21
28.7 (20)
.09
18.1 (20)
.58
30.6 (20)
.06
52.3 (40)
.09
44.5 (20)
.001
Have had formal exposure or training in AI
3.0 (8)
.94
30.4 (10)
<.001
19.8 (10)
.03
43.0 (10)
<.001
11.0 (10)
.36
37.6 (20)
.01
13.4 (10)
.20
The institution has adopted AI
26.1 (16)
.05
35.7 (20)
.01
61.4 (20)
<.001
28.1 (20)
.11
41.8 (20)
<.001
40.6 (40)
.45
41.6 (20)
.003
The organization has trained someone in AI use
9.0 (8)
.34
11.9 (10)
.29
29.7 (10)
<.001
29.1 (10)
.001
43.1 (10)
<.001
13.3 (20)
.87
27.8 (10)
.002
The participant will support AI adoption and embedding
71.3 (8)
<.001
52.2 (10)
<.001
22.1 (10)
.01
27.4 (10)
.002
16.1 (10)
.20
35.5 (20)
.02
53.6 (10)
<.001
aAI: artificial intelligence.
On training and exposure to AI, the study revealed that 30.2% (142/470) of the respondents have had formal exposure or training to AI, the majority (89/142, 62.7%) had a basic orientation, 13.1% (60/457) of institutions or organizations have adopted AI in any form, and 20.9% (93/445) have trained management, operational, and IT staff on AI use. Approximately equal percentages of male (55/181, 30.4%) and female (56/186, 30.1%) participants have been exposed to AI technology. However, more people were exposed to AI in North America (43/130, 33.1%) and Europe (15/49, 30.6%) than in Africa (46/159, 28.9%), but this difference was not statistically significant (P=.20). In addition, more Black or African American (69/200, 34.5%) and White (15/55, 27.3%) participants were exposed to AI than Hispanic or Latino (6/30, 20%) participants, and this was statistically significant (P=.01). Furthermore, more male participants reported that their organizations had trained people in AI (38/181, 21% vs31/186, 16.7%), but this difference was not significant (P=.03). European (12/49, 24.5%) and North American (30/130, 23.1%) participants reported more training than African participants (21/159, 13.2%), and this difference was statistically significant (P=.002). However, reported training across racial or ethnic groups was not statistically significant (P=.87).
Among all respondents, 76.5% (300/392) will support AI adoption and embedding in their organization. AI adoption is led mainly by top executive leadership. However, other levels of leadership play significant roles, as shown in .
A total of 38.6% (102/264) of respondents did not know who was or is leading the artificial intelligence adoption process in their organization. More organizations with male respondents have adopted AI (24/181, 13.3% vs 22/186, 11.8%), female respondents (P=.05). Of note, 24.5% (12/49) of European, 16.2% (21/130) of North American, but only 7.5% (12/159) of African organizations have adopted AI (P=.003; and ). The continent of residence or operation had the highest levels of significance in all parameters except formal exposure to AI (α=.20; ).
Figure 1. Artificial intelligence adoption proponents in health care organizations.
The Use of AI
AI is used mostly in diagnosis (247/506, 48.8%), report writing (230/506, 45.5%), and patient care (205/506, 40.5%). Other areas of high use are in precision medicine (160/506, 31.6%), resource management (156/506, 30.8%), staff management, and leadership and management (137/506, 27.1% each; ).
Similarly, in the coming years, it was predicted that AI will still be most relevant in diagnosis (120/407, 29.5%), patient care (75/407, 18.4%), precision medicine (65/407, 16%), and report writing (58/407, 14.3%). Respondents also identified other uses of AI. These include (among several others) marketing, counseling, emergency preparedness and response, customer services, real-time data management, drug discovery and development, modeling and predictive analytics, a tool for triage at the first point of contact, accurate billing and fraud detection, across-board process sequencing, advancing science and policy, monitoring air quality within the health care system, data management (eg, data access, analysis, processing, and report development), assessment (preanalytical, analytical, and postanalytical stages in health care), research (such as cancer research and treatment), environmental sanitation (such as cleaning toilets and emptying bedpans), customer services (such as customer complaints and solutions and generating referral codes), supply chain management, outreach programs, disease surveillance (including mapping, prediction, and preventive medical interventions), documentation, health care education (including staff training), communication and information management (including referrals, collaboration, and electronic health records), report writing (including minutes of meetings), insurance discoveries, data to inform decisions in most domains, health care advocacy, streamlining and standardizing systems (including processes, charting, referrals, and billing), schedule management (for employees and clients), claims and billing, disease surveillance and epidemic early warning, strategy development and leadership and management in global health, staff management (including hiring, training, and evaluation), prediction and management of pandemics and other emergency situations, procurement and purchasing tenders, strategic management, surveys, and community outreach.
AI use in patient care also includes deployment in surgeries (including robotic surgical equipment), preventive health care, patient follow-up or tracking, virtual health, remote patient monitoring, clinical decision support, patient engagement, detecting adverse events in inpatient and outpatient care, care coordination, chart making, blood and blood products delivery in rural and underserved communities, fast diagnosis and prompt treatment including gene therapy and infection control measures, patient reminders to adhere to their medication and appointment schedules, registration and recording, and prescription management.
In this regard, some respondents commented, “Virtually all aspects with no exception,” “Every aspect including management,” “Every aspect of health care,” “Everywhere,” “In all areas of health care,” and “In all areas of health care delivery and improvement.”
Figure 2. Uses of artificial intelligence in the health care industry. Participants were able to select multiple options.
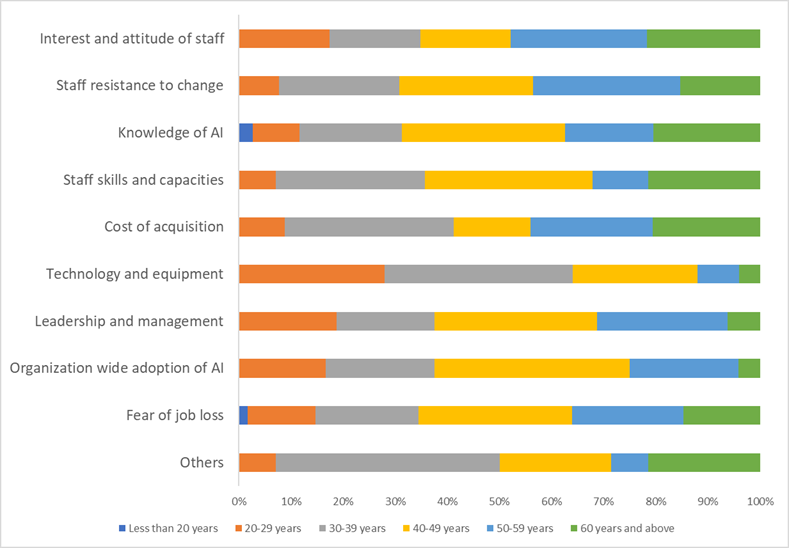
Barriers to AI Use
Knowledge of AI (121/402, 30.1%), fear of job loss (64/402, 15.9%), and staff resistance to change (39/402, 9.7%) were the top barriers identified by respondents against AI adoption (). Other barriers are the cost of acquisition and inadequate staff skills ().
Figure 3. Barriers to AI adoption as identified by respondents. Participants were able to select multiple options. AI: artificial intelligence.
Apart from the itemized barriers, respondents further identified other barriers including poor access to relevant training, hallucination and possible AI inaccuracy, unreliable results, annoying responses in patient care or calls, clinical errors, confidentiality issues, inequitable, patient preference (such as patients not wanting computers or “bots” to talk to them), quality and trustworthiness of AI, grant writing, validity of results, and religious beliefs. Some respondents said, “All options are important barriers.”
Although three-quarters of people were ready to support AI adoption (300/392, 76.5%), 23.5% (92/392) will either not support AI adoption (13/392, 3.3%) or not be sure (79/392, 20.2%). Participants who were unwilling to support AI adoption listed security reasons, lack of in-depth understanding of how AI works, privacy issues, cost, fear of job loss, inaccuracy of results, uncarted future, fear of change, lack of human emotions with AI, fear of AI displacing humanity in patient care, distrust of AI, ignorance of AI and use in health care, patient safety, inferiority to human care, privacy risks, and cost of adoption among all others as their top reasons. A respondent said, “Until it becomes enforced, there will be no need for it.”
Discussion
Principal Findings
The adoption, promotion, impact, and deployment of AI in health leadership and management are a multifaceted process that encompasses various dimensions of health care delivery. The results presented here demonstrate the high importance of AI across all segments, but the adoption of AI and training of workers in AI is low and should be improved upon. A significant proportion of respondents were of the view that AI is already very useful in health care management and patient care and that its value will increase in the future.
Among our survey respondents, exposure to or training in AI was very low (142/470, 30.2%), the majority of which has been basic orientation (89/142, 62.7%). This indicates a serious gap in AI-related professional development that needs to be filled. Given this finding, it is not surprising that participants highlighted the knowledge (and, where relevant, skills) gap as the top barrier to adoption of AI. It is axiomatic, therefore, that if the health care sector wants to improve AI adoption, health care workers and managers must be trained in AI use to a level appropriate for their role.
Similarly, only 13.1% (60/457) of all institutions participating in this survey have adopted AI to date, while 7.9% (36/457) are considering its implementation soon. However, a further 23.4% (107/457) disclosed that they are starting to think about adopting AI. This is not unexpected, as AI is still new, and many people (including some participants) are unaware of its usefulness, skeptical of its precision, and uninformed about its range of applications. Adoption is also low due to key barriers such as fear of job loss, staff resistance to change, and cost, perceived or real, of adoption.
Comparison to Prior Work
Herein, 20.9% (93/445) of respondents said that their organization had trained someone in the use of AI. This 1 in 5 participation rate compares to the 11.4% reported in a recently published survey on AI chatbot use by medical researchers published in 2024 []. The almost doubling may be due to a combination of many factors, among others including the time difference—a year between the 2 studies, greater awareness, increased adoption, and a reflection that chatbots capture only a small proportion of AI uses in health care. Moreover, in the 2024 study, 69.7% of surveyed individuals expressed interest in further training, whereas 79.5% of participants in our survey would support AI adoption in their organization [].
The drive to adopt AI in the health care sector is primarily led by top leadership and management, followed by technical staff. Very few participating organizations (8/264, 3%) outsourced this process. Therefore, promoting AI technologies was influenced by both top-down and bottom-up approaches. However, more than 38% (102/264) of respondents did not know who was leading the AI movement in their organization. Such a lack of awareness calls for better communication between managers and operational or field staff. If not addressed, it may result in change implementation failure, as it is widely recognized that poor communication is the most common cause of change failure in change implementation [].
The integration of AI technologies in health care has the potential to transform health systems, improve patient outcomes, and enhance operational efficiencies [-]. Our study confirms previous reports, showing that AI is useful across several domains of health management and patient care. These include diagnosis and patient care, data management and review, staff and resource management, research and pipeline analysis, and report writing, a portfolio that is predicted to expand in the coming years. AI was most relevant to in-patient care, diagnosis, precision medicine, and report writing, corroborating previous findings [,].
Among our survey respondents, more Black or African American (drawn from Africa, Europe, and North America) respondents were trained or exposed to AI (69/200, 34.5%) compared to White (15/55, 27.3%) and Hispanic or Latino (6/30, 20%) respondents, and this difference is significant (P=.01). However, geographically, fewer participants from Africa (46/159, 28.9%) have had formal training or exposure to AI compared to participants from Europe and North America; fewer organizations in Africa (12/159, 13.2%) have trained their staff in AI compared to organizations in North America (30/130, 23.1%) and Europe (12/49, 24.5%). Furthermore, AI adoption is lowest in Africa (12/159, 7.5%) but highest in Europe (12/49, 24%). This finding is not surprising, as historically, Africa has faced challenges in adopting new technologies due to infrastructure deficits, unhealthy policies, government instabilities, limited access to technology and education, and economic constraints [-]. Efforts must be made this early to ensure that African health care is not left behind in this AI revolution. In light of traditional development barriers, this may appear an aspirational goal. However, our data show a positive mindset toward embracing AI technology in health care, suggesting that it can be readily implemented. This is because Africa has a higher proportion of participants who believe in the usefulness of AI in health management and patient care currently (154/159, 96.9%) and in the future (147/159, 92.5%) and who are willing to support AI adoption (145/159, 91.2%) when compared to Europe (46/49, 93.9%; 38/49, 77.6%; and 41/49, 83.7%; respectively) and North America (114/130, 87.7%; 87/130, 66.9%; and 76/130, 58.5%; respectively). While further studies are needed to identify why AI adoption support is so low in North America, efforts should be made across all continents to enhance and accelerate AI adoption and to boost uptake and the quality and quantity of staff training programs.
Fewer female participants who completed the survey consider that AI has a role to play in health care management and patient practices (171/186, 91.9%) as against male participants (173/181, 95.6%). Moreover, a significantly lower proportion of female participants are willing to support AI adoption (123/186, 66.1%) compared to male participants (163/181, 90.1%; P<.005). We plan to conduct a qualitative study to determine the root cause of this difference. In the meantime, priority should be given to improve female participants’ awareness of the existence of AI and its usefulness, primarily by raising exposure rates of female participants to AI in schools, universities, hospitals, clinics, and community health facilities. We should also involve female participants in simulation exercises involving AI to improve their AI savvy and use. These practices may improve their acceptance and readiness to support AI adoption in health care management and patient care.
Key barriers to AI adoption as identified by our survey respondents are poor knowledge of AI (121/402, 30.1%), people’s fear of job loss (64/402, 15.9%), and staff resistance to change. Other leading barriers were the cost of acquisition and inadequate staff skills. Similar factor that hinders AI adoption were identified in previous studies [-]. When poor knowledge of AI and inadequate staff skills are combined, we have a disproportionately high ignorance-mediated barrier. All top barriers apart from the cost of acquisition are human resource–mediated, showing that appropriate communication, tailored training, and on-the-job exposure to AI can significantly reduce them. These barriers can further be reduced or removed through adequate explanation to patients and their families to gain social acceptance and build trust of AI technologies. Staff education and improved health literacy will most likely increase the willingness of health care workers to support AI adoption, acquisition, and installation.
This study achieved a notably high completion and participation rate compared with similar surveys, which often report substantially lower levels of engagement. This outcome was not unexpected, as we strategically leveraged the extensive professional and community networks of our research partners located in Africa (n=3), North America (n=3), South America (n=1), and Europe (n=2). In addition, the authors maximized their personal and professional connections to enhance outreach, while multiple reminders to the target population further improved response rates.
A particularly striking finding was that Black or African American participants demonstrated both a higher response rate and a more positive attitude toward AI adoption and use. Whether this reflects genuine readiness or aspirational enthusiasm remains an open question that warrants further investigation. Although several African nations, notably Rwanda, Nigeria, and Ghana [-], have demonstrated notable leadership in AI adoption relative to their regional peers, additional qualitative inquiry is needed to better contextualize and interpret this finding.
Taken together, the results underscore the importance of conducting more detailed qualitative studies to explore the underlying drivers of the variations observed in this research. A deeper, country-level analysis of AI adoption processes, rates, and patterns of use will provide a richer and more nuanced understanding of the current global landscape of AI adoption.
Limitations
This study is subject to the typical limitations of a cross-sectional online survey, including selection bias, as participation was limited to individuals within the authors’ personal and professional networks. Additionally, the authors are unaware of the total number of individuals who received the questionnaire, making it impossible to calculate an accurate response rate. Furthermore, some email systems may block messages from unknown senders or redirect them to spam or junk folders, which could have further reduced participation.
To mitigate these limitations in future research, a more purposeful study design should be used—one in which participants are deliberately selected and actively encouraged to respond, thereby improving the likelihood of obtaining unbiased and representative results.
Future Directions
Health care workers are aware of the AI revolution and recognize its usefulness in health care management and patient care. However, their knowledge, support, and adoption are each still low. Hence, there is a need to train more health care workers on not just the basic concepts of AI, but on AI use, algorithms, coding, and other technical issues. Universities, colleges, and institutions of higher education have a critical role in AI training and should be equipped and empowered to do this. In addition, a significant percentage of respondents were ignorant of those who were leading the AI adoption process—a pointer to communication failure or breakdown. Therefore, executive health care management should communicate better with their team to prevent innovation adoption failures. To effectively navigate the path forward toward realizing the potential of GenAI in health care, we recommend training health care leaders and workers in various aspects of AI management and use, provision of AI resources and infrastructure, and standardized oversight and guidelines []. This will play a significant role in building the health infrastructures required to achieve the United Nations Sustainable Development Goal 3 of “good health and well-being” [].
In addition, we suggest that organizations and health care managers in Africa should deliberately and proactively invest in AI adoption and staff training, in order not to be left behind. Having health care workers who are favorable to AI adoption is a strength that African leaders can exploit right now. Individuals should be made to understand that AI works best when guided by skilled personnel and thus will not be replacing people. Although some jobs may be lost, AI will create new jobs and further opportunities that will balance the scale. To advance AI adoption, embedding, and use, governments should emulate Vietnamese leadership that has “identified AI as a key technology to boost its economy” and is taking deliberate and proactive steps to build partnerships, train engineers, pilot new products, support startups, and create an enabling environment for AI development to thrive [,]. As opined by one of the subject matter experts, “… successful AI implementation requires a combination of technical expertise, financial sustainability, and socio-political commitment. Each of these factors is crucial to fostering an environment conducive to AI adoption. All of these criteria are now met (in the private sector), but this cannot be said of the public system that is antiquated and overstretched by comparison” []. Yet, unlike the Vietnamese government, training in AI should go beyond engineers who develop the tools to include health care providers who adopt and use the tools to manage and care for patients. Funding public health institutions to adopt and embed AI will go beyond paying for the acquisition of AI and training of appropriate health care workers to expanding institutional infrastructure and mitigating staff resistance to change powered by fear of job loss and inadequate knowledge of AI functionalities and benefits.
In addition, various ethical concerns around data ownership, privacy, and use and the overall governance of AI need to be addressed by developing, adopting, and implementing organization-wide AI policies. As the said author also said, “data privacy, and the overall governance of AI technologies in healthcare, … are critical for building public trust and ensuring the safe deployment of AI systems.” To achieve a seamless adoption of AI across the global health system, health care workers must be permitted unhindered oversight to alleviate inherent fear that may otherwise result in overt and covert resistance, which will thereby foster acceptance among patients [].
Finally, to effectively navigate the path forward toward realizing the potential of GenAI in health care, we recommend training health care leaders and workers in various aspects of AI management and use, provision of AI resources and infrastructure, and standardized oversight and guidelines []. This will play a significant role in building the health infrastructures required to achieve the United Nations Sustainable Development Goal 3 of “good health and well-being” [].
Conclusions
This study reveals that AI adoption is a global phenomenon, with uptake increasing in all continents, including low- and middle-income countries. Our study documents the present adoption rates and some perceived factors that are facilitating or hindering AI adoption. In addition, health care workers believe that AI is useful and will be more relevant in the future. However, despite several advances in AI technology, deployment and adoption are still lower in some regions of the world. A significant number of participants are ready to support AI adoption and embedding in their organization, as they believe that AI will be very to extremely useful in health care management and practice.
The authors are grateful to the following individuals for useful discussion or feedback during preparation of this manuscript: Professor Anupama Joshi and Ms Judith Aguirre of California State University, Dominguez Hills; Professor Elaine Holmes of Murdoch University, Perth, Western Australia; Professor Paiboon Sithithaworn of Khon Kaen University, Khon Kaen, Thailand; Professor Cathryn Edwards of the University of Lincoln Medical School, Lincoln, United Kingdom; and Professor Marsha Y Morgan of University College London, London, United Kingdom. OOO was supported by California State University, Dominguez Hills and Centre for Family Health Initiative for institutional funding support. SDT-R was supported by the Wellcome Trust Institutional Strategic Support Fund awarded to Imperial College London.
Data are available on request from the author (OOO).
OOO, SDT-R, and AWT-R conceived the paper and designed the methodology used. All authors distributed questionnaires, collated and interpreted data, and contributed significantly to writing the manuscript. SDT-R, OOO, and AWT-R revised it critically for important intellectual content. All authors approved the final version and agreed to its submission. All authors agree to be accountable for the content of the work. The authors confirm that this paper does not need institutional approval to be published.
None declared.
Edited by A Coristine; submitted 02.Jan.2025; peer-reviewed by JCL Chow, A Hidki; comments to author 14.Apr.2025; revised version received 15.Jul.2025; accepted 28.Sep.2025; published 22.Oct.2025.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work, first published in the Journal of Medical Internet Research (ISSN 1438-8871), is properly cited. The complete bibliographic information, a link to the original publication on https://www.jmir.org/, as well as this copyright and license information must be included.
It is legally and ethically mandatory to provide patients with adequate information during a preoperative surgical consent consultation. Preoperative education serves not only as a vital communication tool between physician and patient but also holds forensic importance. Time constraints in surgical practice often limit the amount of time surgeons can dedicate to patients to inform them about the surgical procedure, risks, and postoperative care during the informed consent procedure. This can leave patients feeling underinformed and anxious about their upcoming surgery. With increasing constraints on medical staff resources and growing individual workloads, there is also an increasing interest in boosting efficiency, particularly using artificial intelligence (AI) [,].
Recent technological advancements have led to the development of large language model-based tools such as the AI chatbot ChatGPT, which demonstrate improved text analysis and generation capabilities that have the potential to greatly enhance patient education and outcomes [-]. Patients can ask specific questions regarding their planned surgical procedure and perioperative management and get in return answers relevant to their questions with a possibly high level of accuracy. The potential of AI, especially AI chatbots powered by generative pretrained transformers (GPTs) [,], is increasingly recognized for its ability to transform patient engagement []. However, the use of those tools also carries potential risks. Notably, the tools can produce inaccurate, misleading, and potentially harmful responses, often referred to as hallucinations []. Such hallucinations are expected to decrease with more advanced versions like GPT-4o []. Particularly promising is the use of methods such as retrieval-augmented generation (RAG), where the AI chatbot is provided with a database containing additional, subject-specific information, though the effects of such an approach on responses to patients’ questions have not yet been examined. Recent findings confirm that GPT-4 and GPT-4o exhibit exceptional accuracy and efficiency in language and reasoning capabilities [-]. However, they also emphasize the importance of developing more comprehensive benchmarks and robust evaluation frameworks, incorporating qualitative assessments, human judgment, and detailed error analysis [,]. This study, therefore, also aims at investigating prompt-based assessment in the informed consent procedure.
Given its high degree of standardization and the development of robust postoperative care protocols in recent years, hip arthroplasty serves as an exemplary model for exploring the integration of AI into clinical procedures and patient education frameworks [-]. Total hip arthroplasty (THA) is a procedure where a damaged or worn-out hip joint is replaced with an artificial joint, particularly for patients with hip osteoarthritis. This operation, widely regarded as the “operation of the century,” is noted for its profound impact on pain reduction and the enhancement of patients’ quality of life []. Before the operation, patients usually have questions concerning the procedure and the physical rehabilitation process [,].
The process of information delivery is highly important and represents a central pillar of patient education and the reduction of fear and anxiety [,]. Preoperative anxiety is a common experience among patients, often stemming from inadequate information about the surgical process. Therefore, patient education is of critical importance prior to surgery. Evidence supports that better-prepared patients—those who receive thorough preoperative education and physical conditioning—exhibit improved postoperative outcomes, including accelerated recovery and reduced complications. Therefore, enhanced patient education is an important component of surgical care [].
This is the first study to investigate surgical informed consent consultation using AI chatbots prior to THA. Here, we analyzed ChatGPT’s responses to patients’ posed questions preceding THA to assess its potential in preoperative patient education. Beyond the immediate benefits of patient education, the study explores the quality of the responses and potential hallucinations outputted by ChatGPT and systematically scrutinizes the system’s current ability to deliver adequate responses. This study also examines patients’ attitudes toward the use of an AI chatbot in a preoperative setting, along with potential cofactors influencing these attitudes. Assessing patient satisfaction with AI-driven consultations offers valuable insights into the acceptance and effectiveness of AI in patient interactions. The findings can inform the design of improved systems and the development of guidelines and protocols for integrating AI into patient care, particularly in sensitive areas like surgical informed consent.
Research questions:
What are patients’ preferences regarding the use of an AI chatbot in conjunction with a physician in surgical informed consent, in comparison to a physician only?
How does patient satisfaction compare across informed consent procedures involving only a physician, a physician and ChatGPT, or a physician and RAG-integrated ChatGPT?
How does the integration of RAG with ChatGPT improve the quality of responses to patients’ questions compared with the native ChatGPT model?
How do patient sociodemographic characteristics and general attitude toward AI influence patients’ preference toward using an AI chatbot in surgical informed consent?
Methods
ChatGPT
In this study, we used the OpenAI ChatGPT version 4o (May 13, 2024). To ensure consistency, all questions were presented to ChatGPT in a single, continuous chat session (per patient). The questions were asked by patients during their preoperative surgical consultation before THA in our clinical practice. For the purposes of the study, all patient queries were transcribed verbatim by the doctor into the ChatGPT interface.
In our study, we have used ChatGPT in two ways: (1) without any customization (native) and (2) with customization via RAG, described further below. The second approach allowed ChatGPT to access and incorporate subject-specific knowledge and thus potentially enhance the relevancy and accuracy of its responses. The performance and output accuracy of the 2 systems were compared as described below.
No patient-specific data was entered. The study was conducted in Germany, with all interactions and materials presented exclusively in German.
Recruitment
Patients scheduled for elective, primary THA were recruited from the orthopedic outpatient clinic or on the day of the information session. The study was conducted from May to July 2024. The consent consultations were conducted by 2 physicians who were pretrained based on the prepared frequently asked questions (FAQ) documentation.
Inclusion Criteria:
Age: Participants older than 18 years.
Diagnosis: Diagnosed with primary hip arthritis.
Treatment History: Currently indicated for primary hip arthroplasty.
Language: Able to read, understand, and complete study-related questionnaires in German.
Exclusion Criteria:
Cognitive impairment: Any cognitive impairment or psychiatric condition that would hinder the participant’s ability to provide informed consent and comply with study procedures.
Prior operation: History of primary or revision arthroplasty on the contralateral side.
The participants were provided with detailed written information about the aim of the study, the study procedure, the inclusion and exclusion criteria, and the informed consent about their participation in the study. The participants had the opportunity to ask questions about any aspect of the information provided, the questionnaires, and the study procedure.
Study Arms
Each patient was assigned to one of the following study arms:
Control group (human only): A physician conducting an informed consent consultation in a traditional face-to-face setting.
Intervention group I (native ChatGPT): ChatGPT was used in the questions and answers (Q&A) session in the presence of a physician.
Intervention group II (ChatGPT+RAG): ChatGPT+RAG was used in the Q&A session in the presence of a physician.
From the total population of 36 patients, the first 12 patients were assigned to the Control Group. The next 12 patients were included in the native ChatGPT group, and the final 12 patients were allocated to the ChatGPT+RAG group. All 36 patients enrolled in the study completed the full informed consent procedure and associated assessments, with no dropouts or exclusions.
In the RAG group, an extensive internal document containing all the information about the surgical procedure and the perioperative management at our hospital was compiled and integrated into ChatGPT via the RAG approach. This integration was achieved through the GPT app Keymate.AI (Keymate AI, Inc), which adds the information from the document into the model’s context window, effectively functioning as short-term memory. In the intervention group I, we added the following prompt text: “Please provide responses only in German and in the style of a medical doctor” (Bitte antworte nur in deutscher Sprache und im Stil einer Ärztin oder eines Arztes). In the intervention group II, we added a prompt text prior to each question posed to the AI chatbot: “Please provide responses only in German and in the style of a medical doctor. Please draw only on our internal FAQ document when responding” (Bitte antworte nur in deutscher Sprache und im Stil einer Ärztin oder eines Arztes. Bitte nutze zur Beantwortung ausschließlich die Informationen, die in unserem internen FAQ-Dokument enthalten sind). This setup is supposed to ensure that the AI chatbot responds preferably to the specific clinical information provided.
Data Collection Methods
Patient Sociodemographic Questionnaire and Class-Index
We collected the following patients’ characteristics: age, gender, and highest level of education.
Patients’ Preferences and Satisfaction Questionnaire
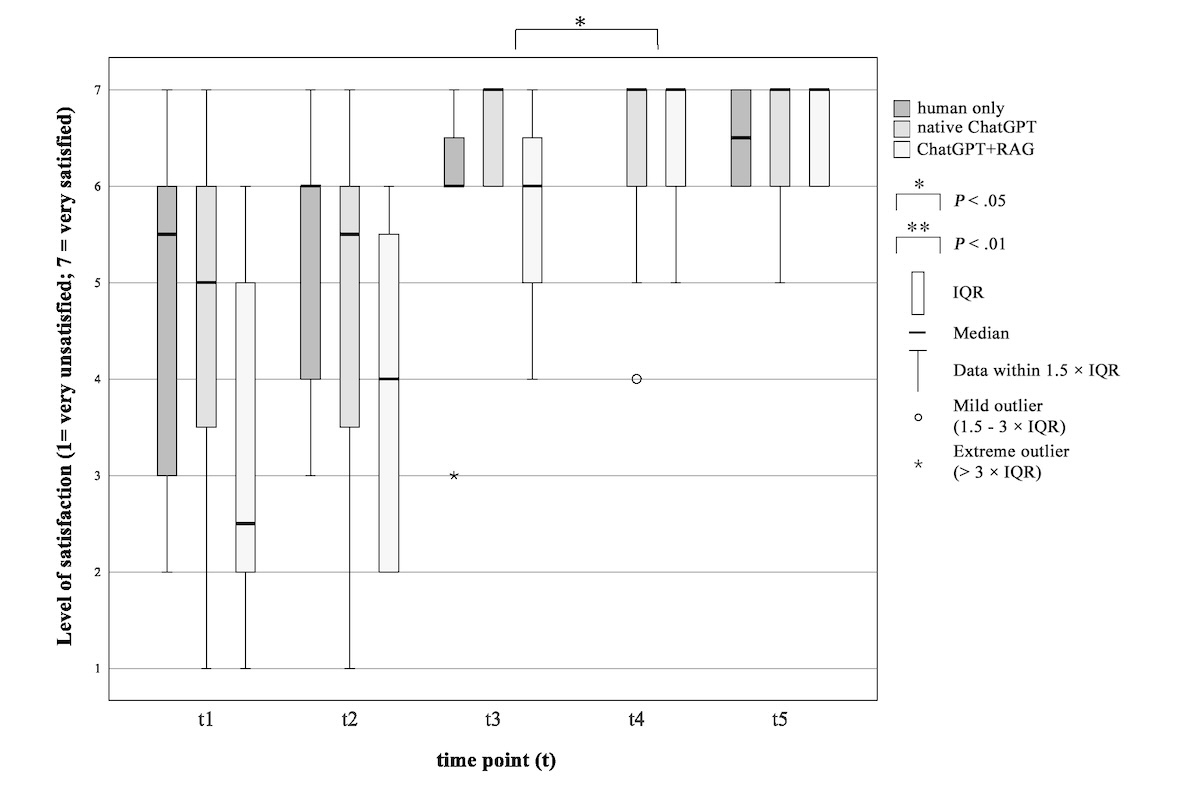
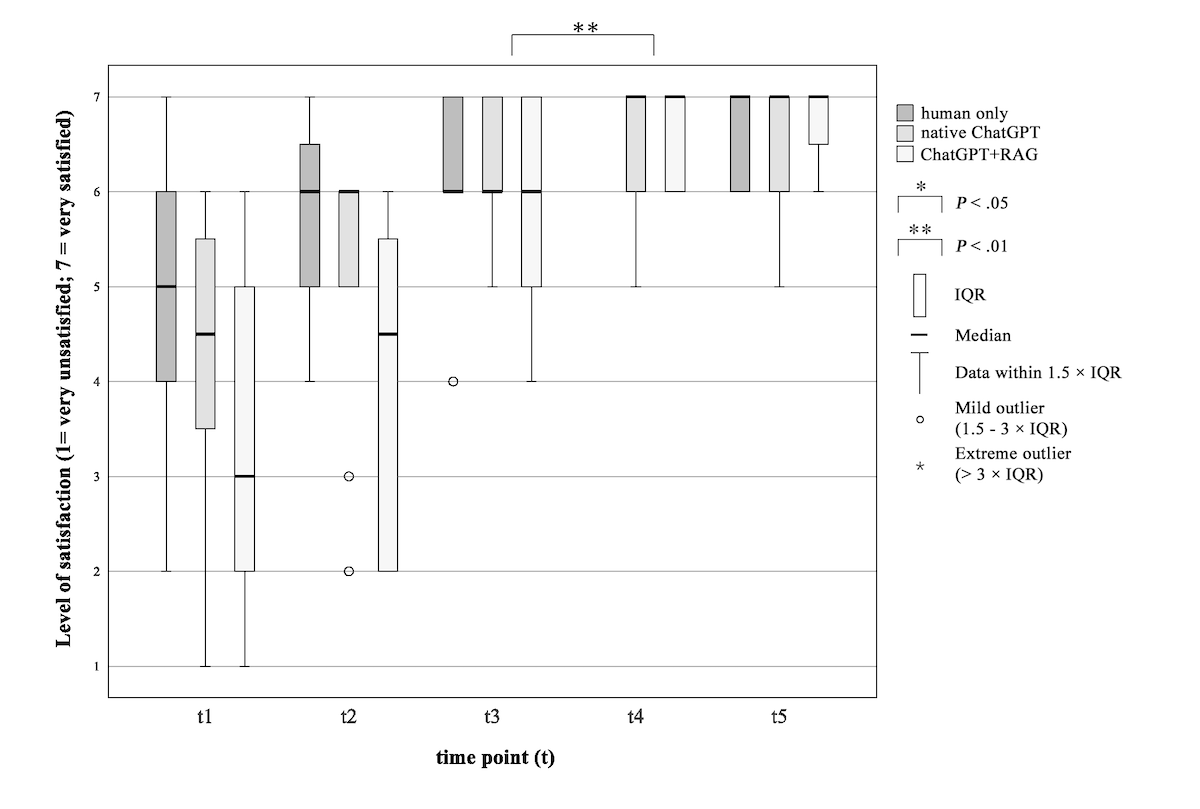
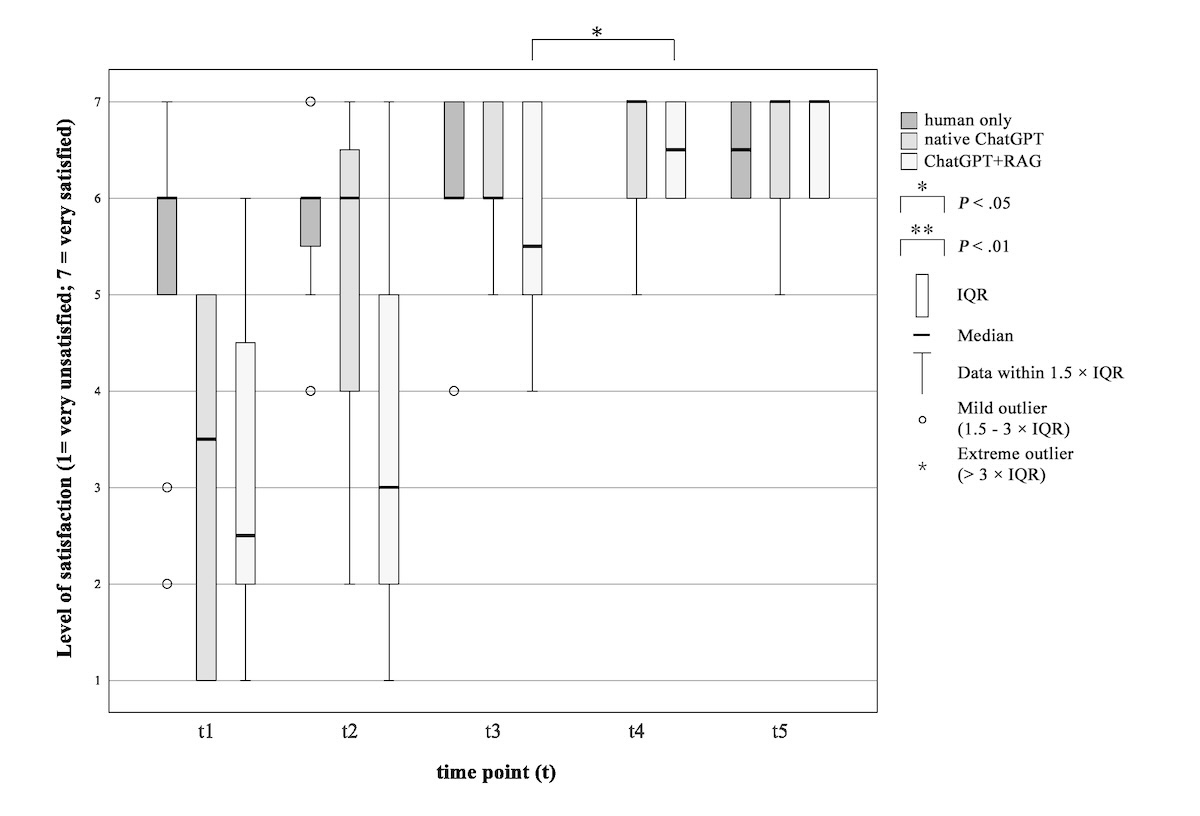
Data were collected using a self-constructed questionnaire that included 5 questions on a 7-point Likert scale regarding the preference of a physician in the informed consent procedure, the level of satisfaction with informedness, the procedure of information transfer, the quantity of information, as well as the preference for having a physician even with less information. Patients could also express their need for more information (yes/no).
Health Literacy Test for Total Hip Arthroplasty
To ensure that patients were capable of giving informed consent and could, in principle, understand the outputs of the AI chatbots, patients’ health literacy was measured with a questionnaire consisting of 9 multiple-choice questions. This questionnaire was adapted from a questionnaire for total knee arthroplasty [], but with knee information and questions replaced by those for hip arthroplasty.
The General Attitudes Towards Artificial Intelligence Scale
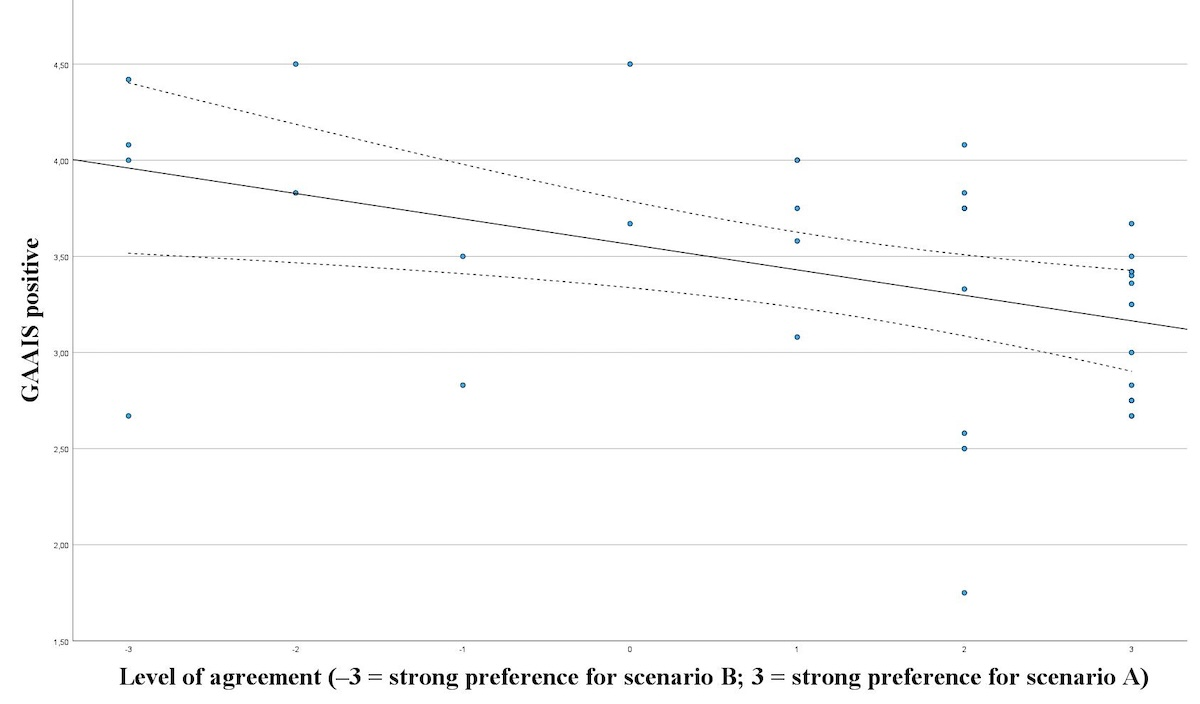
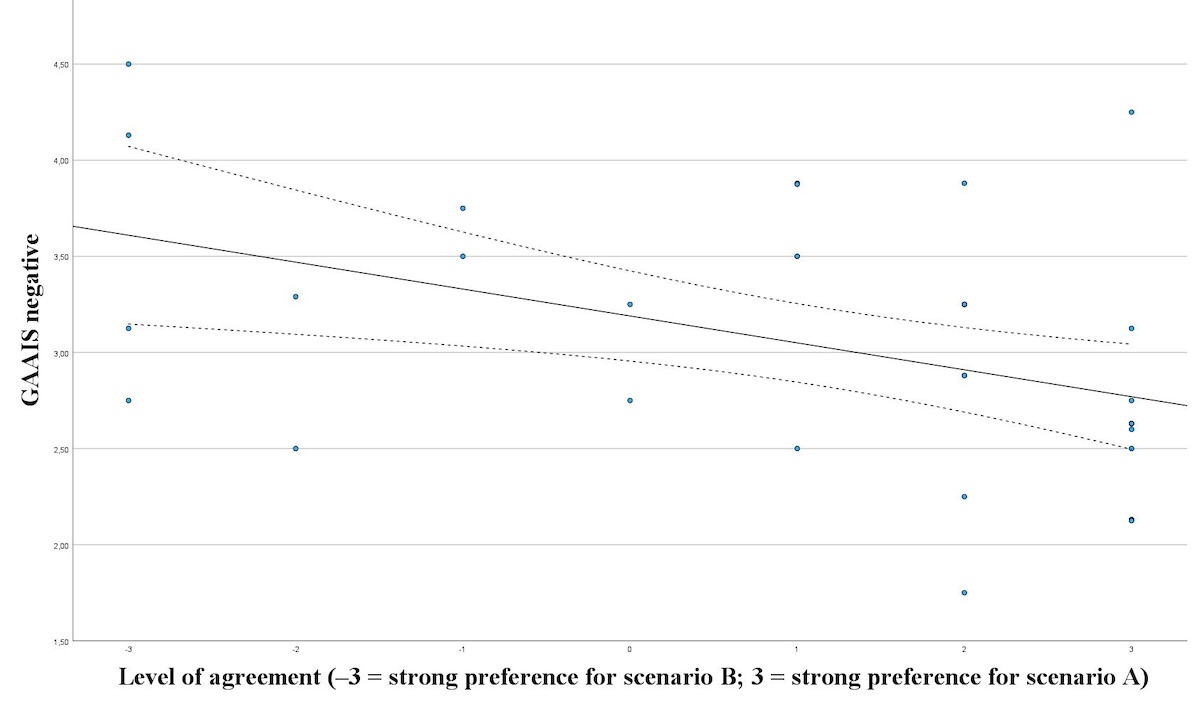
The General Attitudes towards Artificial Intelligence Scale (GAAIS) introduced by Schepman and Rodway [] was evaluated to assess patients’ attitudes toward AI. This 20-question scale is divided into a positive (12 questions) and a negative (8 questions) subscale. Both subscales capture emotions in line with their value. The 5-item scale ranges from 1 to 5. The mean of the positive questions constitutes the overall score for the positive subscale, while the same approach is applied to calculate the overall score for the negative subscale. The higher the score, the more positive the attitude toward AI. An overall scale mean was not recommended.
State-Trait Anxiety Inventory
To assess the actual state of anxiety (influenced by the current situation) and trait anxiety (the general anxiety of the patient), the Spielberger State-Trait Anxiety Inventory [] was administered, specifically Grimm’s abbreviated, validated version [].
Output Evaluation of AI Chatbot Responses
To assess the quality of the AI chatbot responses, we conducted a detailed evaluation of the questions asked by patients during their interactions with the AI chatbot and the model’s responses.
First, ChatGPT’s output was evaluated based on Magruder et al [] for relevance, accuracy, clarity, completeness, and evidence-based. Each criterion ranges from 1 to 5, with 5 being the best answer. We did not rate consistency between questions since every question was posed only once to the AI chatbot. For the accuracy criterion, we compared the responses with the official guideline on indication criteria for total hip arthritis of the “German Society for Orthopedics and Trauma” [], the FAQs of the German Arthroplasty Association [], and our internal standard operating procedures. To evaluate the length of ChatGPT’s output, we introduced an additional criterion that holds the balance between succinctness and informativeness. This criterion focused on whether the response was appropriately concise while fully addressing the question without unnecessary elaboration. Scores ranged from 1 (overly brief or excessively long, missing necessary information, or including redundant content) to 5 (ideal length, providing a complete and focused answer that matched the question).
Second, we evaluated the level to which the AI chatbot produced so-called hallucinations, that is, “content that is either nonsensical or unfaithful to the provided source content” [,]. ChatGPT’s output was classified as fully correct, partly hallucinated, and fully hallucinated. In addition, we annotated the level of hallucination using 3 degrees, following Rawte [] and adapted for the evaluation of AI chatbot outputs in the medical field. The degrees are mild, moderate, and alarming, with mild indicating minor hallucination that is superficial in terms of its impact, moderate indicating a level of hallucination that introduces facts that are either fictitious or tangential to the topic at hand and which could cause the patient to become confused or feel insecure, and alarming indicating added information pieces that bear a radical dissemblance from the topic fed via the prompt or which could lead to serious harm to the patient.
We have added all questionnaires used for data collection as (study questionnaires).
Procedure
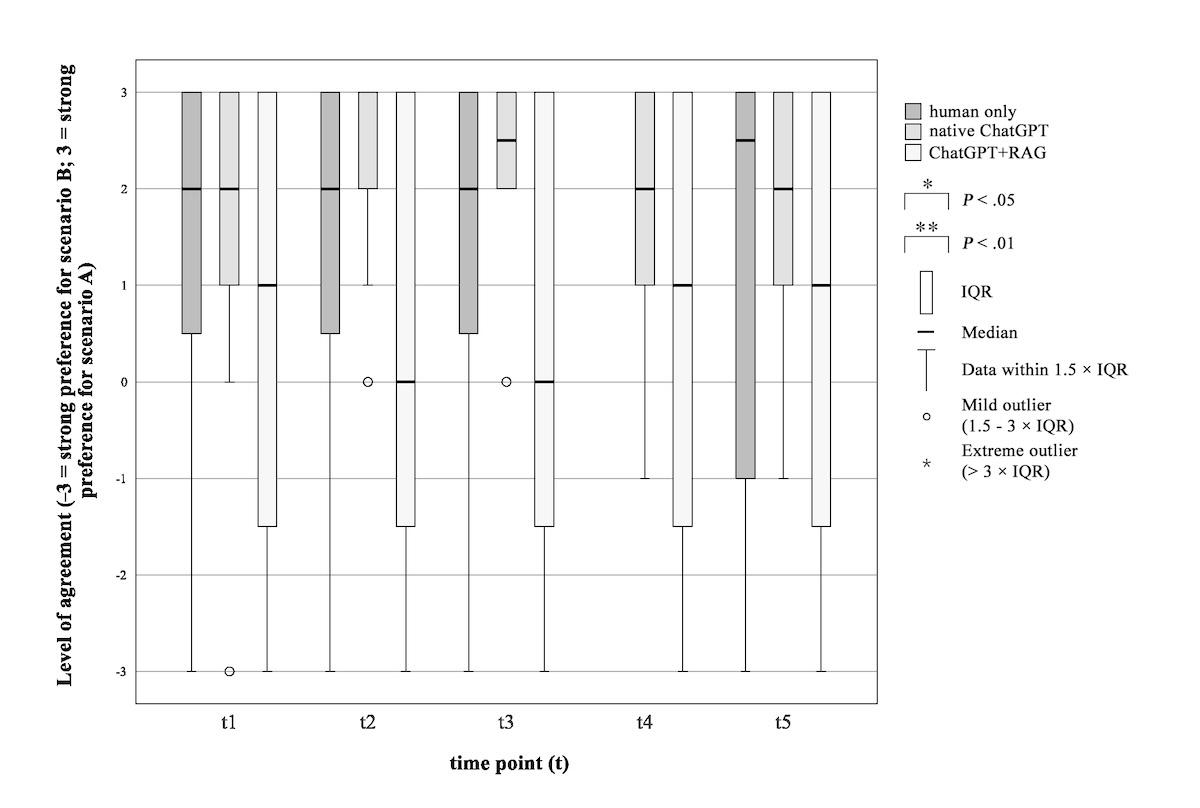
The study procedure and timing of data collection were identical for the control group and the 2 intervention groups up to time point 3, as follows (summarized in below).
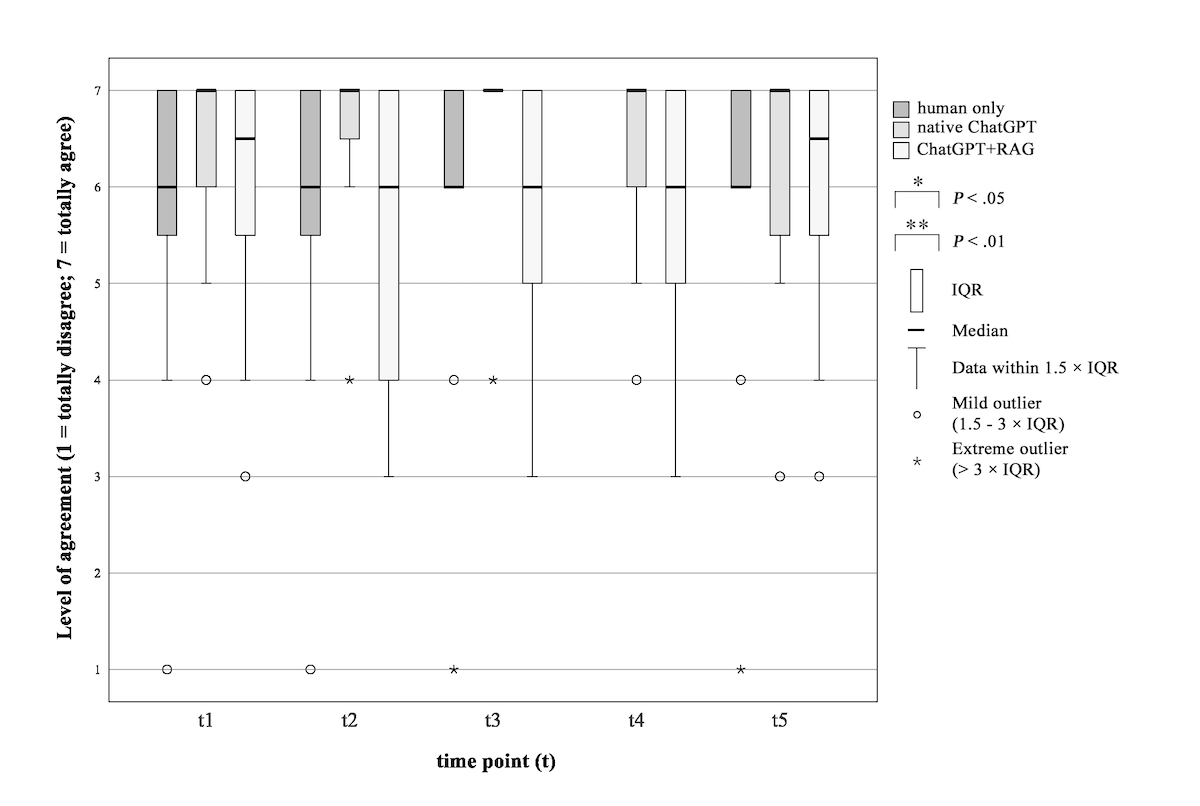
Figure 1. Study procedure and time points of data collection. GAAIS: General Attitudes towards Artificial Intelligence Scale; HLT: health literacy test; PPSQ: patients’ preferences and satisfaction questionnaire; Q&A: questions and answers; SDQ: sociodemographic questionnaire; STAI: State-Trait Anxiety Inventory.
Baseline data collection (time point 1): Initial data were collected prior to the informed consent procedure.
Information sheet (time point 2): After the patient had read the provided informed consent form.
Physician explanation (time point 3): After the physician explained the operation, associated risks, and possible complications, using the information consent form as a reference. At this point in time, no questions were answered.
From time point 4 onward, the procedures diverged as follows.
Control group (time point 4): After patients asked questions in a conventional face-to-face setting, the physician answered without AI chatbot assistance.
Intervention groups I and II (time point 4): After patients’ questions were entered by the physician into the AI chatbot interface, and responses were read out word-for-word in German.
All hallucinated or incorrect responses were identified by the experienced physicians who were present throughout the informed consent consultations. These were explicitly addressed and corrected during the final stage of the session (time point 5), prior to concluding the informed consent process, thereby ensuring patient safety and upholding the integrity of the consultation. In other words, the final data collection step for the Control Group was time point 4, whereas the Intervention Groups had a fifth data collection step, time point 5.
This structured process ensured that all patients, regardless of their group, received clear and sufficient answers to their questions during the informed consent procedure. All Q&A of each information session were documented. All admission examinations were conducted in a standardized setting by the same orthopedic resident and were supervised by a senior orthopedic surgeon. In the following , the course of the survey, the times of data collection, and the method are shown.
The Patients’ Preferences and Satisfaction Questionnaire (PPSQ) was completed 5 times (4 times in the human-only group) during the informed consent procedure. The GAAIS was completed at the beginning and the end of the informed consent procedure to evaluate if a change in the overall inclination toward AI has occurred during the process. The sociodemographic questionnaire, State-Trait Anxiety Inventory, and Health Literacy Test (HLT) were completed prior to the informed consent procedure.
Statistical Methods
Sample Size Assumptions
In our exploratory pilot study, which was designed to generate initial insights and hypotheses for future, larger-scale investigations, a sample size of 12 participants per group (one control group and 2 intervention groups) was chosen based on the recommendations by Julious [].
Data Analysis
Statistical analyses were performed using SPSS Statistics (version 29; IBM Corp).
The Shapiro-Wilk test was applied to assess the normality of the data distribution for continuous variables. The test revealed that none of the collected data were normally distributed (P<.05). As a result, a nonparametric statistical test was used for all analyses.
A Friedman test was conducted to analyze differences in patients’ preferences and satisfaction levels (PPSQ) across the 5 time points: at the beginning of informed consent, after reading the information sheet, after consulting the physician, after using ChatGPT, and at the end of the informed consent process. For multiple pairwise comparisons following the Friedman test, a Bonferroni correction was applied.
The Wilcoxon signed-rank test was applied to evaluate dependent pairwise differences between satisfaction levels before and after the use of an AI chatbot. The same test measured differences between the GAAIS pre- and postinformed consent.
Spearman-Rho was used to analyze the correlation between GAAIS, State, Trait, and PPSQs.
The Mann-Whitney U test was used to compare independent differences between groups in the sociodemographic factors, the number of questions asked by participants, the number of questions including hallucinations, and the quality of the outputs of native ChatGPT and ChatGPT+RAG.
The Kruskal-Wallis test was used to analyze the effects of the highest educational attainment on the outcomes of the patients’ preferences and satisfaction levels (PPSQ; ie, across the 7 independent variables).
Patient questions were categorized into 5 predefined groups: operation, postoperative, complication, rehabilitation, and daily life. For the analysis, patient questions from the 2 intervention groups, the native and the ChatGPT+RAG group, were distributed across these categories. The number of questions within each category was counted for both groups. The Fisher-Freeman-Halton test was used to establish significance in differences in the categorical data. Cramer V was used for the calculation of effect size for Fisher-Freeman-Halton test; Friedmans effect size was calculated via Kendall ω, r was used for effect size of Mann-Whitney U test, and Wilcoxon signed-rank test after the following formula:
To assess interrater reliability between the investigators in assessing the AI-generated responses, Cohen κ coefficient was calculated. κ Statistic values were interpreted using the Landis and Koch criteria with values of 0.00 to 0.20 indicating slight agreement, 0.21 to 0.40 indicating fair agreement, 0.41 to 0.60 indicating moderate agreement, 0.61 to 0.80 indicating substantial agreement, and values of more than 0.80 indicating almost perfect agreement [].
Ethical Considerations
Approval for this prospective study was granted by the institutional review board of Charité – Universitätsmedizin Berlin (application number EA1/152/24). Informed consent was obtained from all participants prior to their inclusion in the study. No waiver of consent was requested or applied. All data collected for this study were pseudonymized prior to analysis. No personally identifiable information was included in the data. Participants did not receive any financial or material compensation for their involvement in the study. No images or supplementary materials used in this manuscript contain identifiable information of individual participants. Therefore, no additional image consent documentation was required or submitted.
Results
Demographic Data
provides an overview of the sociodemographic characteristics of the study participants.
Table 1. Demographic characteristics of the included study participants.
Total
Control group
Native ChatGPT
ChatGPT +RAGa
Patients, n
36
12
12
12
Sex, n
Male
23
5
10
8
Female
13
7
2
4
Age (years)
Mean (SD)
63.2 (8.84)
65.7 (8.40)
58.3 (9.49)
65.5 (8.75)
Minimum
37
48
37
48
Maximum
83
83
77
76
Education, n (%)
Vocational training
20 (55)
6 (50)
8 (67)
6 (50)
University degree
16 (45)
6 (50)
4 (33)
6 (50)
aRAG: retrieval-augmented generation.
Patients’ Preferences and Satisfaction Levels (PPSQ)
Need for a Human Doctor in the Informed Consent Consultation
Average results ranging between 5.50 and 6.65. Although slight shifts in patients’ expressed need were observed during the time points of the study procedure (), these changes were not statistically significant. Difference of preference during time points (t) in the 3 groups: human only (P=.85, χ23=0.818, ω=0.227); native ChatGPT (P=.28, χ24=5.127, ω=0.107); ChatGPT+RAG (P=.048, χ24=9.6, ω=0.200), with pairwise comparisons showing no differences across all groups.
Figure 2. Comparison of patients’ preference for a human doctor during the surgical informed consent consultation procedure. “To what extent do you agree with the following statement: The involvement of a human doctor is essential in the surgical consent process.” RAG: retrieval-augmented generation.
Satisfaction With the Process of Information Delivery
A difference in satisfaction levels was observed between the ChatGPT+RAG group and the native ChatGPT group (). In the ChatGPT+RAG group, the patients were more satisfied with the process of information delivery after interacting with the AI chatbot (P=.014, Z=–2.460, r=0.710). Patients’ satisfaction with the process of information delivery in the native ChatGPT group does not differ after using an AI chatbot compared with after the physician explained the THA operation procedure (P=.28, Z=–1.089, r=0.314).
Figure 3. Patients’ satisfaction with the process of information delivery during the surgical informed consent consultation procedure. “How satisfied are you with the process of information delivery?” RAG: retrieval-augmented generation.
How Satisfied Are You With Your Perceived Level of Informedness?
A difference in satisfaction levels was observed between the ChatGPT+RAG group and the native ChatGPT group (). In the ChatGPT+RAG group, the patients were more satisfied with their level of informedness after interacting with the chatbot (P=.007, Z=–2.714, r=0.783). Patients’ satisfaction with the level of informedness in the native ChatGPT group does not differ after using the AI chatbot compared with after the physician explained the THA operation procedure (P=.06, Z=–1.890, r=0.546).
Figure 4. Patients’ satisfaction with the perceived level of informedness during the surgical informed consent consultation procedure. “How satisfied are you with your perceived level of informedness?” RAG: retrieval-augmented generation.
Satisfaction With the Amount of Information Received
A difference in satisfaction levels with the quantity of information received was observed between the ChatGPT+RAG group and the native ChatGPT group (). In the ChatGPT+RAG group, the patients were more satisfied with the level of information received after interacting with the AI chatbot (P=.02, Z=–2.310, r=0.667). Patients’ satisfaction levels in the native ChatGPT group do not differ after using the AI chatbot compared with after the physician explained the THA operation procedure (P=.32, Z=–1.000, r=0.289).
Figure 5. Patients’ satisfaction with the amount of information received during the surgical informed consent consultation procedure. “How satisfied are you with the amount of information received?” RAG: retrieval-augmented generation.
Preference for a Human Doctor Versus AI Chatbot
Results show that across all groups, participants preferred Scenario A (a human doctor with less accurate information) over Scenario B (an AI assistant alone with more accurate information). This preference was reflected in mean ratings ranging from 1.25 to 1.42 in the human-only group, 1.75 to 2.33 in the native ChatGPT group, and 0.58 to 0.83 in the ChatGPT+RAG group (). The preferred scenario did not change during the procedure of informed consent (human only: P=.75, χ23=1.200, ω=0.033; native ChatGPT: P=.78, χ24=1.775, ωs=0.037; ChatGPT+RAG: P=.68, χ23=1.500, ω=0.031).
Figure 6. Patients’ preference for a human doctor versus an artificial intelligence chatbot during the surgical informed consent consultation procedure. “You have two different information scenarios, A and B. Which scenario do you prefer? Scenario A: Use of AI such as ChatGPT with significantly better quality of information, but without human physician contact. Scenario B: Information provided by a human physician, despite the information being of lower quality compared with the AI.” RAG: retrieval-augmented generation.
State-Trait Anxiety Inventory
The mean state anxiety among participants was 39.0% (SD 17.6%), with values ranging from 0% to 65.7%. The mean trait anxiety among participants was 28.9% (SD 14.4%), with values ranging from 0% to 61.4%. There was no correlation between State, Trait, and the preference of a physician in the informed consent procedure (pstate=0.158; ptrait=0.302), the level of satisfaction of informedness (pstate=0.522; ptrait=0.605), the procedure of information transfer (pstate=0.856; ptrait=0.822), the quantity of information (pstate=0.566; ptrait=0.330) as well as the preference for having a physician even with less information (pstate=0.087; ptrait=0.172).
Sociodemographic Factors’ Impact on PPSQ Values
Regarding age, participants were divided into 2 groups (younger vs older; with 55% in the older group above the mean age of 63.16 years). A statistically significant difference was observed for satisfaction with the process of information delivery, with older participants reporting higher scores (U=99.00, Z=–1.991, P=.046, r=0.332). For all other items, no significant age-related differences were found: need for a human doctor in the informed consent consultation (U=140.00, Z=–0.703, P=.48), satisfaction level of informedness (U=133.50, Z=–0.864, P=.39), satisfaction with the amount of information (U=110.00, Z=–1.622, P=.11), and preference for a human doctor versus AI chatbot (U=147.50, Z=–0.411, P=.68).
For gender, a statistically significant difference was identified for satisfaction with the amount of information, with female participants reporting higher satisfaction than males (U=81.00, Z=–2.299, P=.02, r=0.383). No significant differences were found for need for a human doctor in the informed consent consultation (U=123.00, Z=–0.964, P=.34), satisfaction with the process of information delivery (U=98.50, Z=–1.722, P=.09), satisfaction level of informedness (U=100.50, Z=–1.652, P=.10), or preference for a human doctor versus AI chatbot (U=143.00, Z=–0.221, P=.83).
Analyses of educational level showed no statistically significant differences for any of the Likert items: need for a human doctor in the informed consent consultation (H=4.472, df=3, P=.22), satisfaction with the process of information delivery (H=2.538, df=3, P=.47), satisfaction level of informedness (H=1.018, df=3, P=.80), satisfaction with the amount of information (H=2.730, df=3, P=.44), and preference for a human doctor versus AI chatbot (H=5.823, df=3, P=.12).
Health Literacy Impact on PPSQ Values
The HLT had a mean of 7.92 (SD 1.1) right answered questions, with a range from 6 to 9 right answers. No significant effects were identified related to the patients’ HLT outcomes. Analyses of HLT showed no statistically significant differences for any of the PPSQs: need for a human doctor in the informed consent consultation (H=2.435, df=3, P=.49), satisfaction with the process of information delivery (H=0.882, df=3, P=.83), satisfaction level of informedness (H=2.476, df=3, P=.48), satisfaction with the amount of information (H=2.919, df=3, P=.40), and preference for a human doctor versus AI chatbot (H=4.207, df=3, P=.24) with the patient’s highest level of education.
The GAAIS
Patients’ attitude towards AI did not change after using the AI chatbot in the informed consent consultation, despite GAAIS being negative in the native ChatGPT group (P=.02, Z=–2251, r=0.650; and ).
Significant correlation was shown between GAAIS positive and preference of a physician in the informed consent procedure (P=.002; ρ=0.502; ) and between GAAIS negative and preference of a physician in the informed consent procedure (P=.002; ρ=0.500; ).
Table 2. Patients’ general attitude toward artificial intelligence before and after the surgical informed consent procedure.
GAAISa
Preinformed consent (t=1)
Postinformed consent (t=5)
Human only
Native ChatGPT
ChatGPT+RAGb
Human only
Native ChatGPT
ChatGPT +RAG
Positive subscale, mean (SD)
3.2 (0.7)
3.6 (0.6)
3.5 (0.6)
3.1 (0.9)
3.6 (0.6)
3.4 (0.6)
Negative subscale, mean (SD)
2.7 (0.6)
3.2 (0.7)
3.2 (0.7)
2.7 (0.6)
3.4 (0.7)
3.3 (0.7)
aGAAIS: General Attitudes towards Artificial Intelligence Scale.
bRAG: retrieval-augmented generation.
Table 3. P values for patients’ general attitude toward artificial intelligence pre versus postsurgical informed consent procedure.
GAAISa
Human only
Native ChatGPT
ChatGPT+RAGb
P value
Z
r
P value
Z
r
P value
Z
r
Pre versus post positive
.18
–1.334
0.385
>.99
0.000
0
.83
–0.210
0.061
Pre versus post negative
.87
–0.170
0.049
.02
–2251
0.650
.07
–1.841
0.531
aGAAIS: General Attitudes towards Artificial Intelligence Scale.
bRAG: retrieval-augmented generation.
Figure 7. Correlation between GAAIS positive and preference of a physician in the informed consent procedure. GAAIS: General Attitudes towards Artificial Intelligence Scale. Figure 8. Correlation between GAAIS negative and preference of a physician in the informed consent procedure. GAAIS: General Attitudes towards Artificial Intelligence Scale.
Patient Questions and AI Chatbot Responses
Examining the number of questions asked per group (), the control group stood out with fewer questions, totaling only 20, compared with the RAG group, which asked 52 questions (P=.002, U=20.50, Z=–3.042, r=0.621). The native ChatGPT group asked 39 questions, which were not statistically significant compared with the human-only group (P=.056, U=40.00, Z=–1.910, r=0.390). Additionally, no difference was observed between the RAG and native ChatGPT groups (P=0.22, U=51.00, Z=–1.228, r=0.251).
The average length of responses was measured for both intervention groups. In the native ChatGPT group, responses averaged 283.1 words and 2163.6 characters, while in the ChatGPT+RAG group, responses averaged 91.4 words and 689.8 characters (). This represents a ratio of 3.098 for word count (P<.001, U=81.00, Z=–7.483, r=0.784) and 3.136 for character count (P<.001, U=84.00, Z=–7.458, r=0.781), indicating that native ChatGPT-generated outputs are approximately 3 times longer than ChatGPT + RAG.
shows that in both the native ChatGPT and ChatGPT+RAG groups, most patient questions were focused on the operation itself, followed by questions related to postoperative management. Fewer questions were asked about rehabilitation, daily life, and complications. No differences were observed between the 2 groups in the distribution of question classifications (P=.35, V=0.226).
Table 4. Number of questions asked by patients in each group.
Human only (n=20)
Native ChatGPT (n=39)
ChatGPT+RAGa (n=52)
Mean
1.67
3.25
4.33
Min, n
1
1
1
Max, n
4
7
7
aRAG: retrieval-augmented generation.
Table 5. Length of ChatGPT responses for both intervention groups.
Native ChatGPT, mean (SD)
ChatGPT+RAGa, mean (SD)
Test for differences
P value
r
Words
283 (81.8)
91 (74.3)
<.001
0.784
Characters
2164 (463.2)
690 (558.1)
<.001
0.781
aRAG: retrieval-augmented generation.
Table 6. Percentage of patients’ questions per category in both intervention groups.
Category
Total (n=91), n (%)
Native ChatGPT (n=39), n (%)
ChatGPT+RAGa (n=52), n (%)
Operation
39 (43)
16 (41)
23 (44)
Postoperative
21 (23)
7 (18)
14 (27)
Rehabilitation
11 (12)
4 (10)
7 (13)
Daily life
12 (13)
6 (15)
6 (12)
Complication
8 (9)
6 (15)
2 (4)
aRAG: retrieval-augmented generation.
Evaluation of the ChatGPT Output Quality
Altogether, 91 questions were prompted, and the output was evaluated. shows the results of physicians’ evaluation of the ChatGPT outputs for every category (relevance, accuracy, clarity, completeness, evidence-based, and the length of the output). ChatGPT+RAG had better outcomes in every category compared with native ChatGPT (P<.001; relevance: r=0.504, U=2110.00, Z=–6.803; accuracy: r=0.365, U=2503.50, Z=–4.920; clarity: r=0.565, U=1722.00, Z=–7.629; completeness: r=0.479, U=1977.50, Z=–6.463; evidence-based: r=0.483, U=2082.00, Z=–6.517; length: r=0.726, U=1168.00, Z=–9.795). The minimum value for ChatGPT+RAG was 4.625, while its maximum value was 4.961. The minimum value for native ChatGPT was 3.346, while its maximum value was 4.115. Across all outputs, the κ is 0.761 (SE=0.032, z=22.705, P<.001), indicating a substantial level of agreement.
We observed significantly fewer hallucinations in the RAG group versus in the native ChatGPT group (5 out of 52 [10%] vs 15 out of 39, 38%; ). For 4 out of the 5 hallucinated responses in the ChatGPT+RAG group, no information was available in the FAQ documentation provided to ChatGPT via RAG from which the AI chatbot could draw.
ChatGPT+RAG has a significantly lower hallucination score compared with native ChatGPT (P=.002, U=729.00, Z=–3.168, r=0.332). The degree of severity shows no significant difference (P=.17, U=21.50, Z=–1.521, r=0.340).
– show examples of mild, moderate, and alarming hallucinations identified in our study.
Table 7. Surgeons’ evaluation of ChatGPT output in both intervention groups.
Native ChatGPT, mean (SD)
ChatGPT+RAGa, mean (SD)
Test for differences
P value
r
Relevance
4.115 (0.882)
4.856 (0.450)
<.001
0.504
Accuracy
3.910 (1.059)
4.625 (0.626)
<.001
0.365
Clarity
3.795 (1.036)
4.808 (0.484)
<.001
0.565
Completeness
3.667 (1.147)
4.644 (0.590)
<.001
0.479
Evidence-based
3.346 (1.356)
4.961 (0.583)
<.001
0.483
Length
3.346 (1.394)
4.962 (0.193)
<.001
0.726
aRAG: retrieval-augmented generation.
Table 8. Hallucinations in ChatGPT responses.
Total
Native ChatGPT
ChatGPT+RAGa
Questions asked, n (%)
91 (100)
39 (100)
52 (100)
Hallucinations, n (%)
Not hallucinated
71 (78)
24 (62)
47 (90)
Hallucinated
20 (22)
15 (38)
5 (10)
Thereof, n (%)
Partly hallucinated
15 (75)
12 (80)
3 (60)
Fully hallucinated
5 (25)
3 (20)
2 (40)
Level of severity, n (%)
Mild severity
8 (40)
7 (47)
1 (20)
Moderate severity
9 (45)
7 (47)
2 (40)
Alarming severity
3 (15)
1 (6)
2 (40)
aRAG: retrieval-augmented generation.
Textbox 1. Example of mild hallucination.
Patient question: “I am having a THA [total hip arthroplasty], how can I sleep after the operation?”
Excerpt from the answer: “1. supine position: This is the preferred sleeping position immediately after the operation. Place a pillow between your legs to keep the hip in a stable position and prevent the operated leg from rotating inwards or outwards…”
Explanation for categorization: Due to today’s prevailing minimally invasive surgical techniques, a cushion between the legs in supine position is no longer common or necessary.
Textbox 2. Example of moderate hallucination.
Patient question: “Which type of THA [total hip arthroplasty] does squeak?”
Excerpt from the answer: “…ceramic-on-polyethylene bearing: This combination may also occasionally squeak, although this is less common than with pure ceramic-on-ceramic dentures…”
Explanation for categorization: Under normal conditions, this bearing pair should not squeak. If this pair of bearings squeaks, the reason for the squeaking must be analyzed.
Textbox 3. Example of alarming hallucination.
Patient question: What do you do with a dislocated hip?
Excerpt from the answer: “After reduction, an X-ray or MRI [Magnetic Resonance Imaging] is performed to ensure that the hip is positioned correctly and to rule out any associated injuries such as fractures or damage to ligaments and soft tissue…”
Explanation for categorization: An X-ray must be performed before reduction to rule out fracture. No MRI is performed after the reduction, but a CT [Computed Tomography] scan may be performed in addition to the X-ray after reduction.
Discussion
Overview
The results of this study provide several insights into the potential use of AI chatbots like ChatGPT in health care, particularly in enhancing patient education during the surgical informed consent consultation procedure.
Answers to Research Questions
What Are Patients’ Preferences Regarding the Use of an AI Chatbot in Conjunction With a Physician in Surgical Informed Consent in Comparison to a Physician Only?
Study results showed a clear expressed need for a human doctor in the informed consent procedure. No shifts in patients’ expressed needs were observed during the study procedure. Results also show a preference for scenario A (a human doctor only with worse information-delivery) versus scenario B (an AI-assistant only, with better information-delivery). The preferred scenario (ie, scenario A) did not change during the procedure of informed consent. However, the preference strength in each group differed at t value of 1 from 0.83 in the ChatGPT+RAG group to 1.83 in the native ChatGPT group with 1 being a slight preference for scenario A and 2 being a moderate preference for scenario A. The data presented suggest that patients would prefer the presence of a physician during the informed consent procedure. However, their preference for a human-only scenario (scenario A) over an AI chatbot-only scenario (scenario B) was only slight to moderate. This finding proposes the potential and additional benefit of patients’ interaction with AI chatbots.
In our study, state and trait anxiety exhibited no explanatory power for patients’ attitudes toward the necessity of a human doctor in the informed consent consultation, as well as their preference for a human doctor over an AI chatbot. In contrast, the general attitude towards AI (GAAIS) showed significant correlation with their preference toward interaction with AI during informed consent. One would assume that patients experiencing higher levels of anxiety may perceive AI-driven informed consent as less reliable compared with direct human interaction, potentially due to a need for empathetic communication. While it may be due to a lack of power with 36 patients, further research is necessary.
Li et al [] explored the concerns surrounding the integration of AI into health care from both patient and physician perspectives. Key concerns are “algorithm aversion,” robophobia, loss of humanistic care, and interaction challenges. Patients are particularly concerned about trust, privacy, and AI’s ability to deal with rare conditions or individual circumstances. Physicians, on the other hand, are concerned about job security, legal liability, and the emotional toll of introducing AI technologies into their work environment. The authors emphasize the importance of fostering trust, improving AI-human interaction, and providing appropriate education and policy frameworks to mitigate these concerns.
Emotional states of patients, such as anxiety toward AI, should be specifically addressed when implementing AI systems in sensitive areas like informed consent.
Providing additional support, such as hybrid models combining AI with physician oversight, could help alleviate patient concerns and improve acceptance, particularly in patients with higher levels of anxiety.
How Does Patient Satisfaction Compare Across Informed Consent Procedures Involving Only a Physician, a Physician and ChatGPT, or a Physician and RAG-Integrated ChatGPT?
After the Q&A sessions, all groups are similarly satisfied with their respective level of informedness and the quantity of information they received. This means that the Q&A with the AI chatbot was able to satisfy the information needs of the patients similarly well compared with the physician answering questions. In the ChatGPT+RAG group, the AI-assistant was able to close the previously existing gaps in both the level of informedness and the quantity of information they received after the FAQ session.
In the ChatGPT+RAG group, the patients were more satisfied with the process of information delivery after the Q&A session compared with the human-only and native ChatGPT groups, which may be due to the quality of responses observed with that approach (discussed below). The physicians involved in the study also reported that the more concise responses in the ChatGPT+RAG group were seen as very positive by the patients.
The improved satisfaction in the RAG group may be attributed to the more context-specific and evidence-based responses generated by the RAG-enhanced system. These findings are consistent with prior research indicating that the RAG approach improves output quality, increases patient confidence, and understanding during medical consultations in patient-AI chatbot interaction [-]. By tailoring responses to individual questions and incorporating subject- and clinic-specific data, the RAG approach appears to address key patient concerns more effectively than the native ChatGPT model.
One of the most striking findings was that the control group, which did not interact with the AI chatbot, asked the fewest questions (n=20), whereas the ChatGPT group asked more (n=39), and the RAG group asked the most questions (n=52). The higher number of questions observed in the AI-supported groups may reflect differences in interaction dynamics rather than a lack of clarity, relevance, quality, or completeness in the responses, which were all rated as good to very good, particularly in the ChatGPT+RAG group (). Patients may have felt more comfortable, autonomous, or curious when interacting with the AI chatbot, especially in the ChatGPT+RAG group, where responses tended to be more concise and focused. This may have encouraged additional follow-up questions and deeper engagement with the content. A general indication of these results is therefore that patients in informed consent procedures can benefit from multimedia decision aids and tools such as ChatGPT that may help to encourage engagement and improve patient understanding [].
How Does the Integration of RAG With ChatGPT Improve the Quality of Responses to Patients’ Questions Compared With the Native ChatGPT Model?
The results clearly demonstrate the advantages of the RAG approach over native ChatGPT in all measured quality dimensions. Responses generated with ChatGPT+RAG consistently scored higher in relevance, accuracy, clarity, completeness, evidence-based, and length compared with those generated by the native ChatGPT model (). This demonstrates the effectiveness of incorporating domain-specific information into AI chatbot responses to ensure better alignment with patient needs.
ChatGPT+RAG responses were significantly more concise than native ChatGPT responses, which tended to be much longer and more detailed. While detailed responses may seem advantageous, overly long responses run the risk of overwhelming patients and diluting the focus on their specific questions. In contrast, the concise responses of ChatGPT+RAG were likely perceived as clearer and more directly relevant, contributing to the higher quality ratings observed.
The use of RAG significantly reduced hallucinations in our study. In 4 out of 5 cases in which the AI chatbot hallucinated in the ChatGPT+RAG group, hallucinations were due to missing information in the FAQ document provided as information to the AI chatbot. This might suggest that when properly designed and managed, AI chatbots can provide responses with very few hallucinations. Other studies confirmed the effectiveness of a RAG approach für medical AI chatbots [-,,]. The low error rate obtainable through RAG in conjunction with as complete as possible and guideline-compliant FAQ documentation, together with the high consistency of an AI chatbot, can therefore lead to very good results in combination with a human in medical education. Furthermore, the minimal hallucinations observed in the ChatGPT+RAG group provided valuable insights, enabling improvements to our internal FAQ documentation following the study.
While our study did not explicitly measure consistency across identical or similar prompts, we observed qualitative indications that ChatGPT combined with RAG exhibited higher consistency in its responses. For instance, in the native ChatGPT condition, answers to similar questions regarding the expected length of hospital stay varied, once stating “3-7 days” and another time “5-10 days.” In contrast, the RAG-enhanced version consistently responded with “4-7 days,” which aligns precisely with the information provided in the underlying FAQ documentation. This suggests that the integration of a structured reference source via RAG can improve both accuracy and consistency. However, due to the limited number of participants and the small number of semantically similar questions per group, we were not able to systematically evaluate consistency in this study.
The results show the value of the RAG approach optimizing AI chatbots for use case-specific and clinic-specific information, particularly in sensitive processes like surgical informed consent consultations, where correct, clear, and comprehensive communication is essential. However, it is important to continuously monitor these tools to ensure patient safety in all cases. Furthermore, more research is needed with different datasets provided to the AI chatbot via the RAG approach, different AI-language models, different RAG-architectures, different prompts, and with more patients.
How do Patient Sociodemographic Characteristics and General Attitude Toward AI Influence Patients’ Preference Toward Using an AI Chatbot in Surgical Informed Consent?
Our results show that age, gender, and education did not influence patients’ preference toward using an AI chatbot in surgical informed consent. There is no clear consensus as per today in the body of literature about the role of age in AI or technology acceptance. Witkowski et al [] found that age is associated with AI discomfort in health care. Miller et al [], who studied patients’ use and perception of an AI-based symptom assessment and advice technology in a British primary care waiting room, identified several age-related trends among respondents, with a directional trend for more young respondents (18- to 24-year-olds) to report that the tool provided helpful advice than older respondents (adults older than 70 years). Other studies show that older people are not per se “anti-tech” or “anti-AI.” Xiang et al [] found that receptivity to medical AI increases with age, reaching its highest levels among individuals aged 49 years and older. More research is required in different age groups and medical domains, for example, in arthroscopy, where patients are usually younger.
Patients’ general attitudes toward AI demonstrated weak explanatory power for patients’ preference regarding the necessity of a doctor in the informed consent process and their preference for a human doctor over an AI chatbot. However, further research is needed to better understand the impact of attitudes toward AI. The general attitude of patients toward AI could be considered in the design of processes and systems in the future. This is also against the background that AI and systems that integrate AI are developing rapidly, and their implementation in interaction with patients and doctors must therefore be continuously examined.
The results of the present study demonstrate that, although the analysis of native ChatGPT outputs shows significantly worse performance compared with ChatGPT+RAG, patients report high satisfaction with the process of information delivery, their perceived level of informedness, and the amount of information received across all 3 groups. This should be considered in the design of AI-driven patient interactions. Despite the suboptimal quality of native ChatGPT responses as evaluated by physicians, the RAG approach showed significantly better performance, including higher patient engagement and markedly fewer hallucinations, making it a more promising option for precise patient information delivery.
However, given that patients prefer the presence of a physician and that the RAG approach cannot eliminate hallucinations, we strongly recommend using RAG-based AI chatbots, but only in combination with a physician. Ensuring that patients are not left alone in the information process is crucial. RAG chatbots, meanwhile, offer a complementary solution for enhancing patient communication and reducing the time burden on physicians in daily practice. The additional time gained can help address issues related to patient education, literacy barriers, language differences, and limited doctor communication skills (eg, offering an easy-language mode).
Future Research Direction
The findings of this study suggest several potential directions for future research to better understand patient preferences and concerns regarding AI chatbots in health care, as well as to explore their possible applications in patient care. As we observed more questions in the AI-assisted groups, these tools may help enhance patient engagement. However, the underlying interaction dynamics as well as the number, type, and nature of follow-up questions should be explored in future research.
Since the RAG approach has proven to have a significantly higher engagement and quality compared with the native ChatGPT version, it might be advisable to prioritize further investigation and to expand the approach by incorporating patient-specific input. Further investigation is needed to assess AI chatbots that could provide patient-tailored information and guidance during preoperative and postoperative care.
From a technological perspective, further work is needed to examine how different implementations, such as variations in the RAG framework or AI-language models, and variations in the type and structure of information provided to and by the AI chatbot, affect the results. Future studies should also explore patient interactions using different interfaces (eg, keyboards or voice assistants) and mobile apps of AI chatbots, particularly outside formal informed consent procedures.
The potential for these tools to be perceived as reliable and trustworthy by patients requires careful evaluation while adhering to the principles of patient-centered care []. Patients may also have concerns regarding data privacy and the ability of AI systems to handle rare or complex conditions. While this pilot study did not explore these dimensions in depth, such concerns are central to the responsible use of AI in health care and should be addressed in future research. Future research should integrate qualitative methods, such as interviews or free-text survey responses, to complement structured evaluations and capture deeper insights into patient trust, expectations, and experiences with AI.
Finally, demographic factors such as age, cultural background, and other sociodemographic variables need to be studied in greater detail to understand how different patient groups perceive and interact with AI chatbots. While AI has the potential to make health care more accessible, it is essential to ensure that these tools address the diverse needs of patients and do not inadvertently create new barriers to care.
Limitations
In our study, we aimed at covering a wide range of questions regarding the new field of patient AI chatbot interaction in the surgical informed consent procedure. Yet, our study is not without limitations.
First, the relatively small sample size (N=36) limits the statistical power and generalizability of the findings. However, this sample size was deliberately chosen, as the exploratory pilot study aimed at hypothesis generation and feasibility testing. Future research should expand the sample size to enable more robust subgroup analyses. Second, the over-representation of middle-aged and older adults in our sample may limit the applicability of findings to younger patient populations. While we addressed age-related aspects through subgroup analysis using commonly applied age categories in health care and HCI literature, future studies should aim to recruit more age-diverse cohorts to better understand age differences in trust, comprehension, and preferences regarding AI-assisted consent formats. Third, a physician was present during all informed consent consultations across all study groups. This ensured ethical oversight and patient safety, particularly in the AI-assisted scenarios, but may have influenced patient behavior and interaction with the chatbot. Patients might have perceived the chatbot as being supervised or endorsed by the physician. Future studies should explore different formats and levels of physician involvement to better isolate the effects of AI guidance.
To address these limitations and build on our findings, future studies should involve larger and more demographically diverse samples, test a range of physician-AI interaction models, and include qualitative measures. Moreover, replication in varied clinical settings will be essential to assess the generalizability and practical utility of AI chatbots in surgical informed consent consultations and other medical communication contexts.
Conclusions
This study is the first to explore the feasibility, response quality, and patient acceptance of AI-supported surgical informed consent consultations. By comparing traditional physician-led consultations with those assisted by ChatGPT and ChatGPT+RAG, we found that patient satisfaction remained consistently high across all groups, suggesting that the use of AI support did not compromise the informed consent experience. The integration of RAG significantly enhanced the quality of AI-generated responses and reduced hallucination rates compared with native ChatGPT. Notably, participants in the ChatGPT+RAG group reported the highest satisfaction with information delivery and perceived informedness, alongside greater engagement as reflected in the number of questions asked.
Although most patients still preferred physician-led consultations, our findings are encouraging. They indicate that AI chatbots, particularly when enhanced with clinical-specific information via RAG, can deliver accurate, context-aware, and concise information while promoting patient participation. Given the small sample size, future studies are needed to confirm these findings in more diverse populations and to examine the role of AI chatbots in different and more autonomous patient-AI interactions and across different clinical contexts. However, as we embrace this opportunity, it is essential to remain cautious about challenges such as trust, data privacy, and the preservation of the human touch in patient care.
The authors thank Dr Moses El Kayali for assistance in identifying appropriate data collection instruments. This research received no external funding.
The datasets generated or analyzed during this study are not publicly available due to privacy concerns, but are available from the corresponding author on reasonable request. Sample dialogues are provided in the .
Stefanie Donner and Sascha Donner conceptualized the study and managed the project. Stefanie Donner and PK conducted the investigation. Stefanie Donner and Sascha Donner developed the methodology, curated the data, advised on the formal analysis, prepared the original draft of the manuscript, and contributed to visualization. PK performed the formal analysis and contributed to the visualization and the original draft of the manuscript. JD supported the development of the methodology of the study and advised on the original draft of the manuscript. AK and JB contributed to the formal analysis, visualization, and preliminary manuscript revision. CP supervised the project and managed the project. All authors reviewed and edited the manuscript and have read and agreed to the published version.
None declared.
Edited by A Coristine; submitted 07.Apr.2025; peer-reviewed by M Veliyathnadu Ebrahim, P S; comments to author 08.Jul.2025; revised version received 29.Jul.2025; accepted 28.Aug.2025; published 22.Oct.2025.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work, first published in the Journal of Medical Internet Research (ISSN 1438-8871), is properly cited. The complete bibliographic information, a link to the original publication on https://www.jmir.org/, as well as this copyright and license information must be included.