
Scientists at Indiana University have achieved a breakthrough in understanding the universe thanks to a collaboration between two major international experiments studying neutrinos, which are ubiquitous, tiny particles that stream…
Blog
-

OnePlus 15 Goes on Sale in China, and Its Global Launch Appears Imminent
The OnePlus 15 is now available to purchase in China, and it’s likely that a global model that would arrive in the US and the UK will be announced soon.
The Chinese edition of the phone comes in three colors: the previously announced Sand Storm…
Continue Reading
-

A home genome project: How a city learning cohort can create AI systems for optimizing housing supply
Executive summary
Cities in the U.S. and globally face a severe, system-wide housing shortfall—exacerbated by siloed, proprietary, and fragile data practices that impede coordinated action. Recent advances in artificial intelligence (AI) promise to increase the speed and effectiveness of data integration and decisionmaking for optimizing housing supply. But unlocking the value of these tools requires a common infrastructure of (i) shared computational assets (data, protocols, models) required to develop AI systems and (ii) institutional capabilities to deploy these systems to unlock housing supply. This memo develops a policy and implementation proposal for a “Home Genome Project” (Home GP): a cohort of cities building open standards, shared datasets and models, and an institutional playbook for operationalizing these assets using AI. Beginning with an initial pilot cohort of four to six cities, a Home GP-type initiative could help 50 partner cities identify and develop additional housing supply relative to business-as-usual projections by 2030. The open data infrastructure and AI tools developed through this approach could help cities better understand the on-the-ground impacts of policy decisions, while also providing a constructive way to track progress and stay accountable to longer-term housing supply goals.
1. Introduction
More than 150 U.S. communities now participate in the Built for Zero initiative, a data‑intensive model that has helped several localities achieve “functional zero” chronic or veteran homelessness and dozens more to achieve significant, sustainable reductions. For instance, Rockford, Illinois, became the first U.S. community to end both veteran and chronic homelessness by establishing a unified command center that used real-time, person-specific data to identify individuals experiencing homelessness and strategically target resources to achieve functional zero. The work has revealed an important formula: pairing real‑time, person‑level data integrated across agencies with nimble, cross‑functional teams can drive progress on seemingly intractable social problems.
Homelessness is typically downstream of shortages of housing supply. In the U.S. alone, there is an estimated 7.1 million‑unit shortage of homes for extremely low-income renters. But no equivalent playbook, standardized taxonomy, or shared data infrastructure exists to holistically address housing supply at the city or regional level. Developers, school districts, transit agencies, financing authorities, and planning departments each steward partial information and property assets that could translate into expanded housing supply.
Without shared accountability for meeting community housing needs, chronic coordination failure results. Homelessness is one stark result. Individuals and families shuttle between services, attempting to qualify for housing and income assistance while competing for limited housing options. Meanwhile, opportunities to increase housing supply—through repurposing idle land, preserving at-risk units, streamlining development approvals, or other strategies—go unrealized because critical information remains fragmented across agencies or never collected at all.
When attempting to integrate city-level housing data, most cities confront an unsatisfying choice: license an expensive proprietary suite, outsource a one-off dashboard to consultants, or manually assemble spreadsheets in-house. Some jurisdictions run dual systems—an official internal view and a vendor dashboard—further fragmenting workflows and complicating institutional learning. Among the commercial vendors trying to fill the information void are those offering proprietary suites with parcel visualization, market analytics, scenario modeling features, and/or regulatory particulars. Many are built on public data but packaged behind paywalls that limit transparency, interoperability, and reuse. Several also only cover a handful or a finite number of geographies.
Without open interfaces, common data standards, or accessible tools, even well-staffed departments struggle to maintain the continuous data integration that drives real outcomes. The manual processes that have enabled breakthrough successes require dedicated teams and sustained funding that most cities cannot maintain through personnel changes and budget cycles. Equally important, fragmented or proprietary data ecosystems can persist because existing arrangements benefit from the opacity—whether by limiting public scrutiny of how housing assets are managed or, as recent cases against rent-setting platforms illustrate, by enabling landlords and data vendors to leverage nonpublic information in ways that reinforce market power and reduce competition. What emerges is a patchwork of partial views—each typically anchored in narrow mandates and reinforced by opaque systems that resist integration.
While many cities have prototyped tools and surfaced effective approaches to optimizing their housing assets despite these challenges, sustaining and scaling them across contexts requires more than heroic individual efforts. The path forward to unlocking hidden housing supply at scale lies in durable data pipelines, cross-functional teams with clear shared goals, and shared data and playbooks that reduce the transaction costs of doing this important work city-by-city.
AI’s potential as an accelerant
Recent breakthroughs in generative AI, computer vision, and geospatial analytics—many of which have only been commercialized since 2023—drastically lower the cost and increase the speed of data integration and analytics. For housing data, early pilots show that machine-learning models can rapidly reconcile parcel IDs across assessor, permit, and utility records; detect latent development sites—such as vacant lots, single-story strip malls, or underutilized garages—by triangulating land-use data with computer-vision analysis of aerial imagery; and forecast supply impacts of zoning tweaks or financing incentives across thousands of parcels.
However, lessons from Built for Zero and elsewhere would suggest that new forms of technical automation must be paired with common infrastructure and institutional capabilities to drive measurable outcomes. For instance, meta-analyses of cross-agency Integrated Data Systems (IDS) in the U.S. are associated with better targeting and continuous program improvement when paired with governance, standards, and security protocols.
Early experiments applying machine learning (ML) to housing data (discussed in the next section) suggest that computation alone does not eliminate complexity. Legal nuance, inconsistent document formats, and context-specific exceptions routinely defeat even state-of-the-art data integration and machine learning techniques, requiring manual verification and domain expertise. Even when AI delivers efficiency gains, those improvements alone do not build housing. Without clear protocols, shared taxonomies, and durable governance that elevates domain expertise and supports capacity building, even efficient AI tools risk automating the wrong tasks—or failing when local conditions shift.
The core challenge of optimizing housing supply is not simply an absence of tools, but the absence of a common and underlying infrastructure, taxonomy, institutional capacity, and incentives for transparent data sharing needed to support computational tools.
The case for a city-level “Home Genome Project”
Against this backdrop, a coalition of city housing leaders, community-development practitioners, technologists, and funders gathered in “Room 11”—a 17 Rooms flagship working group aligned with Sustainable Development Goal 11 for sustainable cities and communities—to explore how to harness AI tools to increase housing supply. In a rapid sequence of virtual meetings, the group identified data gaps, transaction costs, and governance hurdles that stall housing production and allocation and identified the key technical and institutional ingredients required to harness AI’s potential value for local decisionmakers.
Drawing on these insights, this memo suggests standardizing and integrating city-level public data and capabilities should be a primary focus for leveraging AI’s potential value. A concerted international movement, starting with a learning network of cities, could generate the necessary shared inputs required to develop AI systems (a shared data model, data standards and datasets, and machine learning models) and the playbooks for the infrastructure, human capacities, and institutions needed to operationalize AI systems for optimizing city-level housing supply.
As discussed in Room 11 meetings, the siloed status quo resembles biomedical research before the step-change advances in data sharing and management initiated through the Human Genome Project. By mandating 24-hour public release of DNA sequences across participating laboratories, the HGP’s Bermuda Principles ignited a wave of global discovery that later underpinned AI-driven feats like CRISPR and AlphaFold. When researchers openly shared SARS-CoV-2 genomic sequences in early 2020, it enabled parallel vaccine development that would have been impossible under traditional closed models.
Housing needs an analogous shift—a “Home Genome Project” (Home GP)—defined by shared data standards, open pipelines, and reciprocal learning norms that convert local experiments into a global commons of actionable knowledge. A de-siloed approach to housing data infrastructure and shared learnings could also provide a more structured brokering mechanism for connecting front-line teams with the resources, expertise, and partnerships they need to scale their solutions.
Whereas DNA data is inherently structured and universally interpretable, housing data reflects diverse, locally determined rules and contexts, making integration and standardization far more complex. Achieving a Home GP will require careful, collaborative design of data models and standards from the outset, ensuring consistent definitions, quality inputs, and governance frameworks that can sustain large-scale, cross-jurisdictional use.
By coupling open data standards and city-contributed datasets and ML models with peer-to-peer capacity building, Home GP could help catalyze collaboration, learning, and innovations for increasing housing supply above baseline in 50 partner cities by 2030. Like the Human Genome Project, Home GP would be designed to treat data as critical infrastructure and collaboration as a force multiplier for AI system development. While the start-up phase of Home GP would likely focus on larger cities, the development of the approach would enable integration of data from communities of every size and type—including towns, villages, and counties with unincorporated areas.
2. Home GP foundations: A cross-section of city-level approaches and progress
Room 11 discussions unearthed a rich cross-section of city-level experimentation across three key barriers to housing supply. Several cities in the U.S. and globally are making noteworthy inroads. Teams are integrating data and prototyping digital tools to help map existing land assets, simulate the effects of policy interventions on development, and detect and forecast vacancies.
Different cities possess different raw ingredients—data, models, talent, or political capital—to influence decisionmaking for optimizing housing supply. Cities with massive metropolitan areas like Atlanta are developing bespoke solutions, while data and resourcing constraints faced by smaller cities like Santa Fe (U.S.) are developing more nimble and leaner solutions.
Mapping existing land assets and development proposals: Atlanta (U.S.) has merged tax-assessor records with other agency spreadsheets into the city’s first live map of every publicly owned parcel; its new Urban Development Corporation can now identify and package land deals across departments instead of hunting for records one by one. London (U.K.) leverages its tight regulatory framework to systematically collect and standardize data from multiple organizations, capturing information on roughly 120,000 development proposals annually. This regulatory process creates opportunities for comprehensive data gathering that feeds into what functions as a digital twin of the planning system. The Greater London Authority’s planning data map has been accessed 23.4 million times in the past year and serves as the evidence base for public-sector planning across the region. Boston’s (U.S.) citywide land audit surfaced a substantial inventory of underutilized public parcels.
These approaches point toward a “digital twin” approach that gives cities real-time insight into how their built environment is changing—helping planners do long-range scenario planning with more accurate, up-to-date information. A tool like this can also strengthen accountability—by transparently tracking new development, cities can measure progress against housing goals (similar to California’s Regional Housing Needs Allocation process) and hold themselves responsible for delivering results.
Simulating the effects of policy interventions: Denver (U.S.) is coupling parcel-level displacement-risk models with zoning-and-feasibility simulators so that staff can test how ordinances (like parking minimums or inclusive housing regulations) could impact housing developments before policies reach decisionmakers. Charlotte (U.S.) is moving to automate updates to its Housing Location Tool (an Esri workbook that scores parcel-level properties on development potential based on four dimensions: proximity, access, change, and diversity) and to allow the process to proactively score all parcels and recommend areas for development.
Vacancy detection: Water-scarce Santa Fe (U.S.) is beginning to mine 15-minute water meter readings to flag homes that sit idle for months and explore incentives for releasing those units for rental use—an information loop that turns a utility dataset into a housing-supply radar.
Together this range of efforts shows that cities possess different raw ingredients to accelerate the development of new housing supply. What is missing is the infrastructure to convert these opportunities and one-off accomplishments into standardized, repeatable, and shareable playbooks. Just as the Human Genome Project transformed genomics by creating structured vocabularies for machine readability and cross-jurisdictional collaboration, a similar infrastructure and lexicon for describing and cataloging assets such as parcels, vacancies, and zoning types could unlock the innovation and progress needed to meet the country’s urgent housing needs.
Diagnosing the decision problem in city housing markets
Room 11 meetings surfaced several incentive, capacity, and governance barriers that need to be overcome to secure more housing.
1. Demand-driven solutions for surviving the “dashboard valley of death”
The allure of technology‐driven reform is hardly new. Over the past decade, several public funders and technology companies have supported housing dashboards as potentially scalable solutions to generating real-time insights for local decisionmakers. But most, particularly those built top-down, have achieved only limited uptake owing to the fragility of public data and capacity ecosystems underneath them. Where cities have developed their own tools—like Charlotte’s Housing Locational Tool—the data pipelines often rely on manual, once-a-year updates. This so-called “dashboard valley of death,” a key challenge discussed in Room 11, suggests the need for an alternative strategy to technology development, one where front-line agencies are equipped with common infrastructure and capabilities to self-generate tailored solutions to locally defined problems.
In this vein, a new generation of tools demonstrates that success is possible when technology serves clearly defined user needs. The Terner Housing Policy Simulator, developed by UC Berkeley’s Terner Center, for example, models housing supply impacts at the parcel level across 25-30 jurisdictions. By combining zoning analysis with economic feasibility modeling—running multiple pro-formas to assess development probability under different scenarios—the tool provides actionable intelligence that cities like Denver are using to evaluate parking minimum reforms and inclusionary housing policies. Similarly, initiatives like the National Zoning Atlas have achieved traction by tackling a foundational data challenge: digitizing and standardizing the country’s fragmented zoning codes, having already mapped over 50% of U.S. land area, including major metros like Houston and San Diego.
2. Fragmented ownership and authority
Basic facts about land are often missing. In many local jurisdictions, no single office can confirm which public entity owns which parcel, let alone coordinate how those assets are deployed for housing. In Atlanta, a dedicated central team eventually stitched together assessor files, handwritten ledgers, and transit-authority spreadsheets to build the city’s first unified public-land map. Armed with this new data—and inspired by Copenhagen’s municipal land corporation—the city established an Urban Development Corporation in 2024 to broker multi-agency approvals and unlock dormant parcels for housing. The exercise surfaced more than 40 developable acres that had been hiding in plain sight. Fifty new development projects are underway.
3. Capacity bottlenecks
Most local housing departments operate with lean staffing and tight budgets; larger cities may command more resources, but must navigate correspondingly larger and more complex operating environments. Smaller communities may not have data or geospatial departments, or may even have difficulties accessing or understanding their own regulations, including zoning. Either way, the personnel and financial headroom required to sustain continuous data collection, community engagement, and policy iteration remain in short supply. Denver’s team, for example, is forced to guess how inclusionary-housing tweaks will land on developers’ pro-formas—an impossible task without automated modeling support.
What AI can—and cannot—do for housing supply
In theory, AI systems can be leveraged to assist in data integration processes by reconciling parcel tables, flagging underused land, and running zoning simulations in minutes rather than months. Successful implementation of these functions could, in turn, help free up local teams to focus on higher-impact activities that move from identifying potential supply to building supply—such as creating new agencies like Atlanta’s Urban Development Corporation, reviewing property records that automated systems cannot interpret, and engaging communities in housing production efforts.
In practice, however, there are many constraints when attempting to use ML to integrate data and automate inference. As learned in Room 11 conversations, the National Zoning Atlas’ two-year collaboration with Cornell Tech, backed by NSF funding, found that even leading ML models could not reliably parse zoning codes. Despite processing thousands of pages of text, researchers concluded that legal nuance, inconsistent formatting, and local exceptions rendered zoning documents effectively unreadable by AI alone. Atlanta’s experience mapping public land similarly revealed that property ownership records required manual verification—automated systems failed to detect transactions between public agencies that did not trigger tax records. In Charlotte, displacement monitoring still depends on human review to distinguish qualified transactions from multi-parcel or otherwise unqualified sales that the model can’t classify automatically. Collectively, these examples demonstrate that civic data often embeds ambiguity and context-specific nuance that resist full automation.
A strategy for supporting cities to leverage AI for housing supply
Room 11 conversations validated the hypothesis that developing more standardized city-level data infrastructures and institutional capabilities will help unlock more opportunities for AI systems to be used to optimize housing supply. Local staff with context and domain expertise are needed to design the inputs and ground-truth the outputs of AI systems, while interpreting and using those inputs in real-world negotiations with developers, residents, and finance authorities. In short, algorithms can deliver speed; local knowledge and policy judgment can turn speed into supply.
To harness this potential, Home GP’s proposed learning cohorts could be designed to convert isolated pilots into shared public infrastructure. In the same way that the Human Genome Project transformed biomedical research through open datasets, protocols, and collaborative standards that supported downstream AI-enabled technologies like CRISPR, Home GP could create the data commons and institutional capacities cities need to support AI systems for optimizing housing supply.
This approach builds three core functions:
- “Vertical ladders” that help each city climb from basic data auditing and management to increasingly sophisticated tools and competencies in its chosen domain. For example, following its first public land use dataset, Atlanta was able to add more and more sophisticated layers of data (e.g., zoning and market data), which in turn enabled more sophisticated inference informing project development.
- “Horizontal branches” for peer exchange: The city that perfects a vacancy-detection model can lend that module as a template for others to adapt while borrowing, say, a permitting-analytics script in return.
- Cross-sector brokerage that connects city teams with technical experts, funders, and peer cities—facilitating the partnerships and resource flows essential for turning pilots into sustainable programs. This brokering function, exemplified by organizations like Community Solutions in the homelessness space, has proven critical for scaling local innovations.
The initial phase of Home GP would develop two pillars of support architecture: (1) shared computational tools (data definitions and standards, datasets, and ML models) that can support context-calibrated AI applications for data integration, pattern recognition, and forecasting housing supply; and (2) an institutional readiness playbook that helps any jurisdiction develop institutional capacities for data integration and AI system deployment.
- Shared computational tools: Initial Home GP efforts to develop shared resources might include data integration standards and tools, integrated city-level datasets (land use, zoning, market data), and historical time series data (on either actual as-built conditions or policies) that can be federated and used to train ML predictive models and develop applications. Innovative approaches to inference developed in specific contexts (e.g., Santa Fe’s water use proxy data for vacancies) could be made available for adaptation to other relevant contexts.
- Institutional readiness playbook: Room 11 discussions identified at least five institutional enabling conditions for harnessing the potential value of AI tools for which playbooks could be developed through a community-of-practice model:
a. Impact-focused mandate. A concrete, numeric, and time-bound housing supply target shared across city-level stakeholders and tied to public reporting—e.g., “add 20 percent versus baseline affordable units by 2030.”
b. Empowered cross-functional teams. Land bank, planning, IT, community liaison—everyone who touches parcels or permits at one table. As in Denver, Atlanta, and Santa Fe, often these mission-driven, cross-functional teams sit within the mayor’s office.
c. Minimum viable data foundations. A clean parcel table, zoning layer, and permitting feed that update on a regular cadence.
d. Technical literacy and readiness. Analysts, organizers, and dealmakers who can translate model outputs into negotiations with developers and residents.
e. Equity guardrails. Bias audits, open-source code, and transparent processes that protect against unintended harm. Denver has already begun developing internal equity review processes as part of its housing data modernization efforts, while Charlotte is focusing on transparent use of displacement data to monitor outcomes.
While cities serve as the natural starting point for this work, the long-term sustainability of these systems may require thinking beyond municipal boundaries. London’s success in collecting standardized data from roughly 120,000 development proposals annually stems from national legislation—the Town and Country Planning Act—that creates regulatory leverage for data collection. This demonstrates how state and federal policy frameworks can enable the data standardization that cities need. Similarly, Metropolitan Planning Organizations (MPOs) could coordinate cross-jurisdictional housing strategies, while state agencies might maintain regional databases and technical infrastructure at scale. The institutional readiness playbook should therefore anticipate how governance structures can evolve from city-led experiments to more distributed models that leverage policy frameworks and regional coordination.
3. Next steps and open considerations
Home GP—hosted initially by a working group of Room 11 organizations—could convene four to six U.S. cities as a proof-of-concept cohort over 12 months. The ultimate goal is to produce open dataset layers released under permissive licenses, reusable AI modules (e.g., for vacancy detection, land-assemblage scoring), and implementation playbooks covering procurement language, governance, and community engagement. A “story bank” could document use cases that demonstrate what cities can achieve with better data.
Cities would select an appropriate peer-learning format, for example, rotating as lead developer and fast follower can ensure that expertise diffuses rather than concentrates; while a parallel pilot approach might allow cities to adapt quickly to local conditions.
Critically, the working group would also consider the technical and institutional architecture requirements for data and model standardization. The National Zoning Atlas discovered that standardizing data across jurisdictions was among its consultants’ most technically complex projects. Building an integrated and scalable national or international infrastructure may require specialized partners and/or a unified platform with capabilities no single organization currently possesses.
To reach this proof-of-concept stage, a prior planning phase would likely be needed to develop a detailed implementation roadmap, including governance structure, data sharing protocols, and potential funding models. This phase could convene municipal Chief Technical Officers, or equivalent, and housing leaders from those cities—bringing together those with technical expertise, housing expertise, and local commitment to investment in housing innovation capacity.
4. Conclusion: Choosing to build together
Local leaders already possess many important raw ingredients—granular parcel data, courageous front-line teams, and a new generation of AI tools—to close information gaps that have long stymied housing production. The key need is for civic leaders, government partners, philanthropy, and investors to knit those ingredients into a durable, shared infrastructure— analogous to scientific open-data protocols. By treating data pipelines and AI models as shared public infrastructure—and by learning in public through a cohort architecture that amplifies shared competencies and brings relevant stakeholders together—cities can unlock the transformative potential of AI to close housing supply gaps and make homelessness rare and brief. The goal—50 cities each identifying and unlocking more homes than the currently projected new supply by 2030—is ambitious yet reachable.
The Brookings Institution is committed to quality, independence, and impact.
We are supported by a diverse array of funders. In line with our values and policies, each Brookings publication represents the sole views of its author(s).Continue Reading
-

Imogen Poots to Receive Denver Film’s Excellence in Acting Award
Imogen Poots will be swimming her way to honors from the Denver Film Festival.
The star of Kristen Stewart’s feature directorial debut The Chronology of Water has been selected to receive an excellence in acting award…
Continue Reading
-
Liver transplants from MAiD donors show outcomes comparable to standard donations
Organ donation following medical assistance in dying (MAiD), also known as euthanasia, is a relatively new practice both in North America and worldwide. A first comparison of liver transplantation using organs donated after MAiD in…
Continue Reading
-

O’Brien Confident as Ireland Prepare for All Blacks Rematch in Chicago » allblacks.com
Ireland wing Tommy O’Brien said ahead of their Test in Chicago on Sunday (NZT) that while the All Blacks have their respect, they are no longer on a pedestal.
Since breaking their duck against the New Zealanders in their 2016…
Continue Reading
-

AI-powered search engines rely on “less popular” sources, researchers find
OK, but which one is better?
These differences don’t necessarily mean the AI-generated results are “worse,” of course. The researchers found that GPT-based searches were more likely to cite sources like corporate…
Continue Reading
-
UBC Study Unveils Why Honey Bees Dethrone Queens
It sounds like the plot of a medieval historical drama: A once-powerful monarch, weakened by illness, is overthrown by her previously loyal subjects. But in honey bee colonies, such high-stakes coups aren’t just fantasy — they’re a…
Continue Reading
-

Promoting Co-Benefit Actions for Positive Environmental and Social Impacts from Renewables – News
Speakers from financial institutions, NGOs, government, and industry highlighted how biodiversity protection, community engagement, and energy development can be mutually reinforcing when built into project design and policy frameworks.
Examples ranged from solar projects in France that integrate wetland restoration, eco-grazing, and citizen investment, to marine wind farms in the North Sea linked to long-term marine conservation funding. In Uzbekistan, solar developers are protecting tortoise habitats and partnering with local herders to manage grazing. In Qinghai Province, China, large-scale PV parks are reversing desertification while supporting ecological animal husbandry.
Industry actors like TotalEnergies are scaling agro-photovoltaic models that combine renewable energy generation with sustainable farming. Policymakers and financial institutions, including the European Bank for Reconstruction and Development (EBRD) and the International Renewable Energy Agency (IRENA), underscored the role of strong policy frameworks, financing incentives, and capacity building to scale these approaches globally.
Ecowende is developing the Netherlands’ most ecological offshore wind farm to date—powering 3% of national demand while enhancing North Sea biodiversity—through an innovative, research-driven and collaborative approach supported by IUCN’s Biodiversity Advisory Team, which provides independent review and recommendations on biodiversity goals and targets.
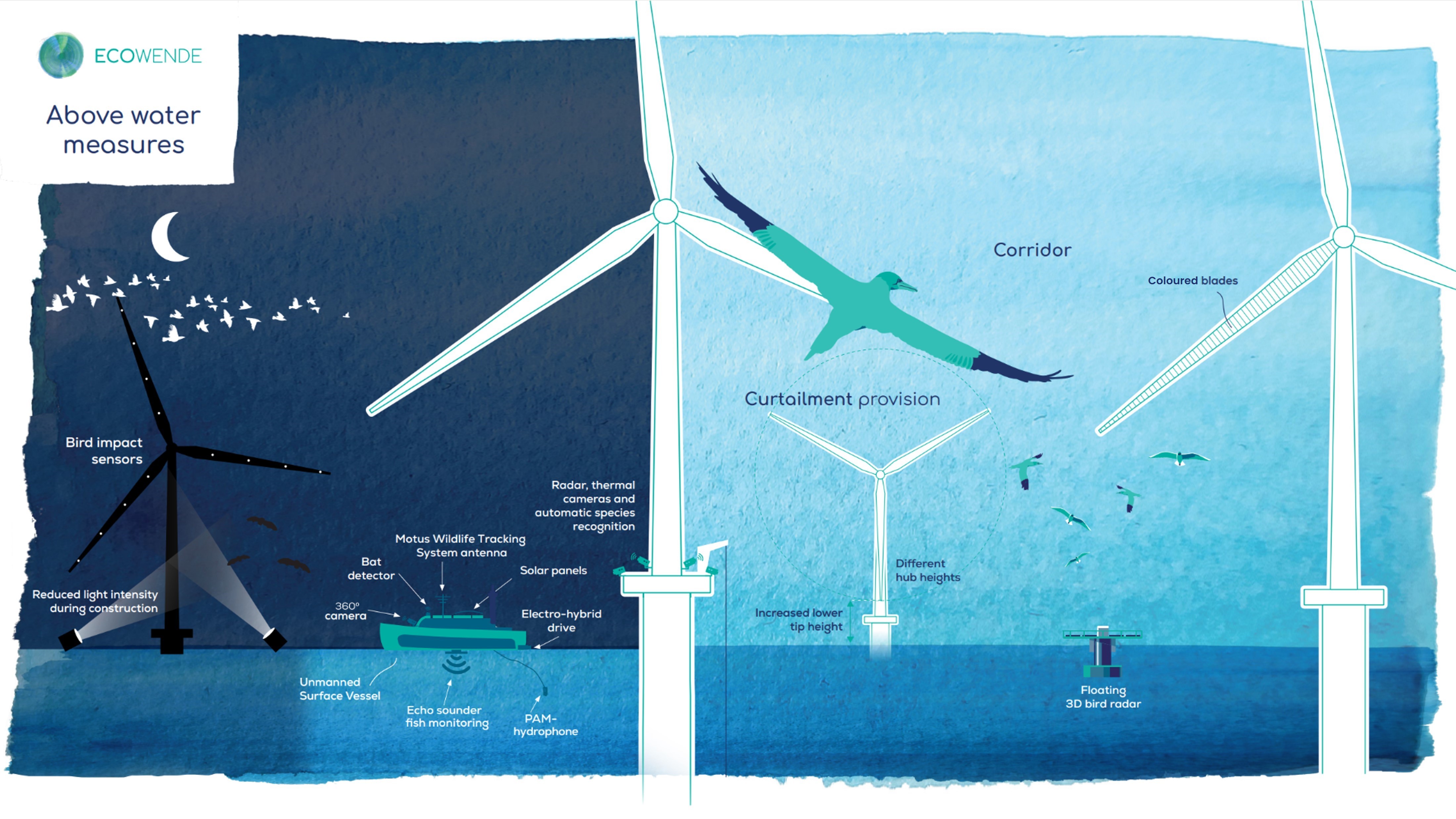
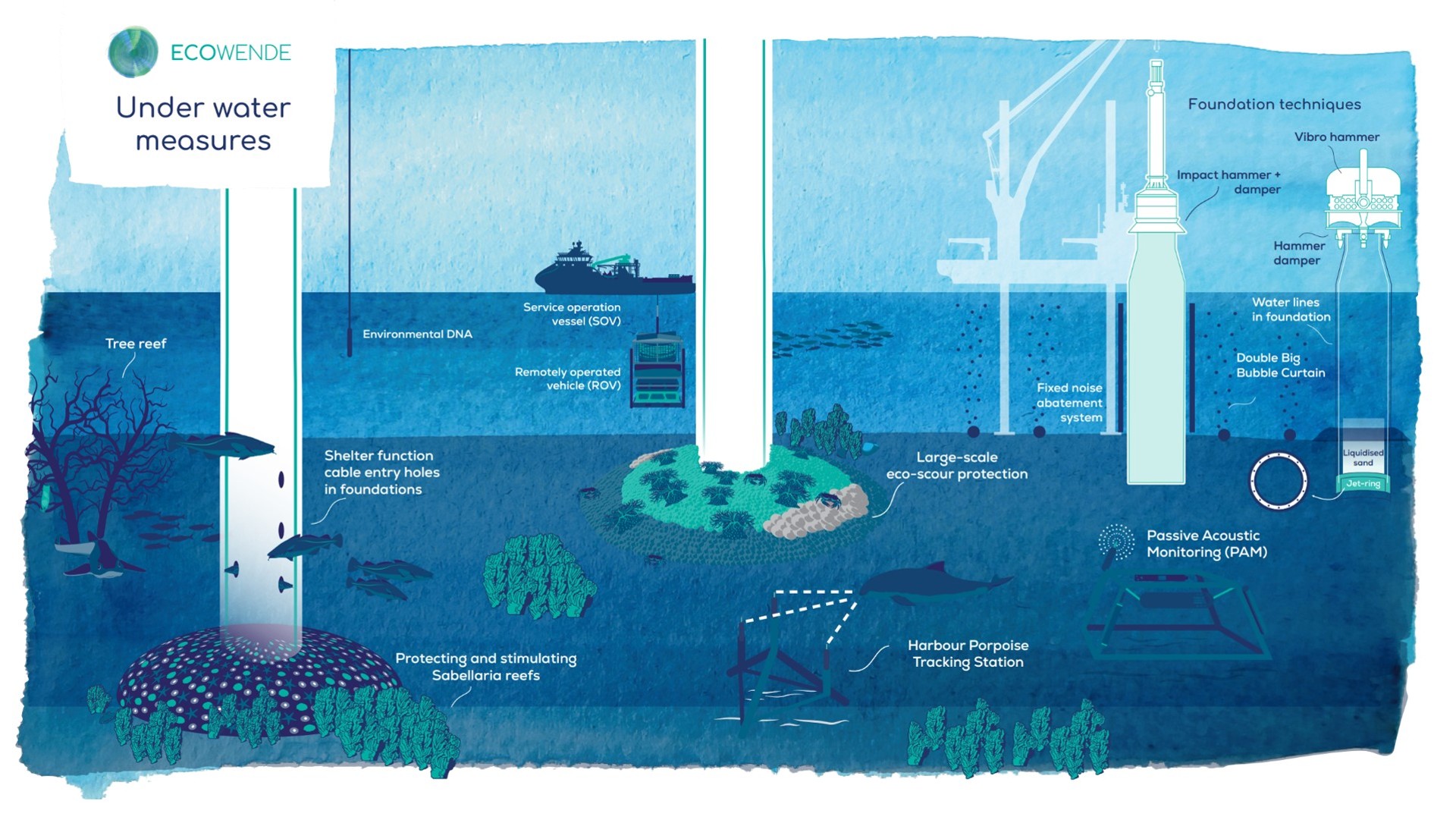
From regulatory tools to community partnerships, the session highlighted that the energy transition can—and must—deliver measurable gains for biodiversity and people.
The session was moderated by Qiulin Liu from IUCN and speakers included Adonai Herrera-Martínez from EBRD, Aonghais Cook from The Biodiversity Consultancy, Dr. Ma Hao from the Qinghai Provincial Development and Reform Commission, Jinlei Feng from IRENA, Karen Westley from Ipieca, Libby Sandbrook from Fauna & Flora, Sophie Depraz from Ipieca, Steven Dickinson from TotalEnergies, Yu Miao from SPIC Huanghe Hydropower Development Co., Ltd., and Zhang Jiali from the China Renewable Energy Engineering Institute (CREEI).
Continue Reading
-

Josh Hartnett To Star In Tommy Wirkola Film ‘All Day & All Night’
EXCLUSIVE: Josh Hartnett (Trap) will star in and produce the action-thriller All Day & All Night, written by Tommy Wirkola and John Niven and to be directed by Wirkola, the Norwegian filmmaker best known for the Violent Night and Dead Snow…
Continue Reading