Domain-specific analysis
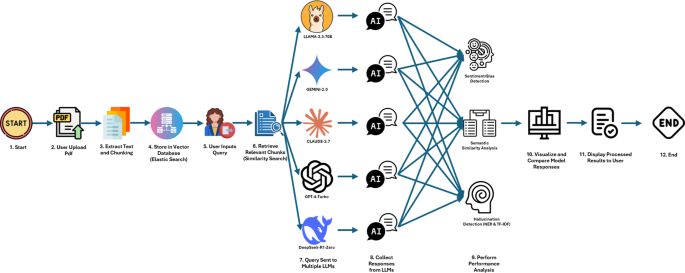
The analysis of a sample query according to Figure 2, “What are the three main strategies incorporated into the Energy Management Scheme (EMS) proposed in EMS: An Energy Management Scheme for Green IoT Environments, and how does each address energy challenges in heterogeneous IoT nodes?”39 reveals that Llama, Gemini, and Claude achieve high semantic similarity, with Llama and Gemini closely leading at a score of 0.92. Sentiment analysis across all models shows predominantly neutral outputs, with minimal emotional bias. In terms of factual consistency, Claude and Llama achieve the highest TF-IDF similarity scores, indicating strong alignment with the source material, whereas DeepSeek records the lowest, suggesting a higher rate of hallucination. Interestingly, DeepSeek performs best in NER-based factual accuracy, though Llama, Claude, and OpenAI also show strong results. Overall, Llama and Claude exhibit the best combined performance in terms of both semantic relevance and factual grounding. We compare the performance of each LLM within each of the five domains. Performance varies significantly between models, highlighting the importance of domain-specific LLM deployment strategies.
This figure presents a multi-metric comparison of LLM performance for a IOT domain query. The top-left heatmap shows semantic similarity between model outputs, while the top-right bar chart illustrates sentiment distribution across responses. The bottom-left graph displays TF-IDF similarity with source content (for hallucination detection), and the bottom-right compares hallucination scores using both TF-IDF and NER methods.
Agriculture
When evaluating all queries within the agriculture domain, aggregated results confirm that Llama and Claude lead in semantic similarity (0.857), with OpenAI following closely at 0.853, reflecting strong alignment with the reference answers as shown in Figure 3 and Table 1. Sentiment scores remain mostly neutral between models, and Gemini displays the highest neutral sentiment (0.910). Regarding the factual accuracy, Llama outperforms other models, achieving the highest TF-IDF similarity (0.453) and the NER-based entity recognition score (0.294), suggesting excellent factual grounding. In contrast, DeepSeek records the lowest TF-IDF (0.289), and OpenAI records the lowest NER scores (0.156), indicating a higher tendency to hallucination. Gemini maintains steady performance across all metrics, balancing semantic understanding with factual reliability. Overall, Llama consistently outperforms others, with OpenAI showing strong semantic similarity but only moderate factual accuracy, while DeepSeek lags on most evaluation criteria. The final rankings within the agriculture domain place Llama firmly in the top position, ranking first in both min-max and z-score normalization methods as presented in Table 2. Gemini secures the second position with a balanced and strong performance in all metrics. Claude and OpenAI show moderate results, with some variation depending on the evaluation metric. DeepSeek consistently ranks last, underperforming in semantic similarity, factual grounding, and hallucination detection. The strong performance of Llama in semantic similarity, TF-IDF and NER score alignment underscores its ability to handle agricultural queries with precision and factual robustness.
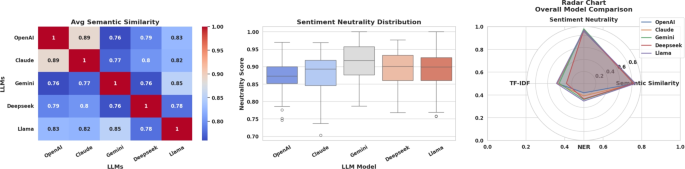
This figure provides an aggregated overview of model-level performance. The left heatmap shows average semantic similarity between outputs of different LLMs, indicating alignment in understanding. The center box plot illustrates the distribution of sentiment neutrality scores, highlighting how balanced or biased the models’ responses are. The right radar chart summarizes overall performance across key metrics semantic similarity, sentiment neutrality, TF-IDF, and NER accuracy enabling quick visual comparison of the models’ strengths and weaknesses.
Biology
When aggregating results across all queries in the biology domain as displayed in Figure 4 and Table 1, Llama again leads with the highest semantic similarity score (0.822), slightly ahead of OpenAI (0.814), and Gemini and Claude trail closely at 0.791. Sentiment analysis consistently shows high neutrality scores for all models, confirming scientific responses’ expected neutrality. Claude achieves the best TF-IDF similarity (0.361) and NER-based factual accuracy (0.245), reflecting excellent alignment with the source material. Llama also performs consistently well in both semantic and factual evaluations, while DeepSeek remains at the lower end.
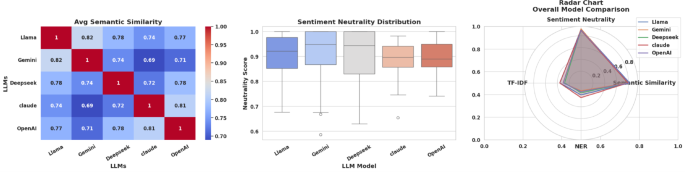
This figure offers a comparative analysis of LLM performance. The left heatmap presents average semantic similarity scores across models, indicating how closely aligned their outputs are. The center box plot shows the distribution of sentiment neutrality scores, revealing the consistency of objective responses. The right radar chart summarizes performance across four key metrics semantic similarity, sentiment neutrality, TF-IDF, and NER accuracy providing a holistic view of each model’s strengths and trade-offs.
Overall, Llama and Claude proved to be the most reliable models for biology-related queries. According to Table 2, the final rankings for the biology domain place Llama at the top, securing first place in both min-max and z-score normalization evaluations. Claude follows closely behind, demonstrating strong, balanced performance across all metrics. OpenAI and Gemini fight between to secure ranks third and fourth, maintaining moderate and steady results. Meanwhile, DeepSeek consistently occupies the lower ranks in antecedent similarity, sentiment neutrality, and hallucination detection, indicating less reliable output. In conclusion, Llama and Claude emerge as the most trustworthy models for addressing biology-focused queries with both semantic accuracy and factual rigor.
Economics
Referring to Table 1 and Figure 5, the broader evaluation across economics-related queries reveals that Llama leads with a semantic similarity score of 0.761, trailed by Gemini at 0.728, while Claude registers the lowest score of 0.701. Sentiment analysis continues to show uniformly neutral outputs, as expected for technical and policy-focused content. In factual consistency metrics, Llama once again leads, achieving the highest TF-IDF similarity (0.426) and NER accuracy (0.205), reflecting strong grounding in the source material and reliable entity recognition. DeepSeek consistently underperforms across both factual verification metrics, indicating higher rates of hallucination and lower adherence to original content. Overall, Llama demonstrates the most balanced performance across both semantic and factual dimensions for economics-related queries.
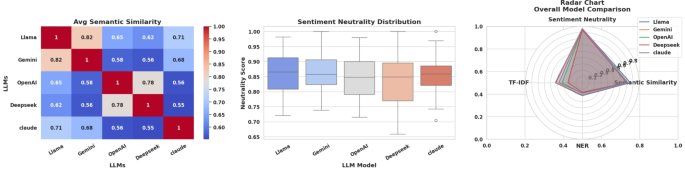
This figure provides a comparative performance overview of multiple LLMs. The left heatmap illustrates the average semantic similarity between models, revealing how closely their responses align. The middle box plot displays the distribution of sentiment neutrality scores, highlighting each model’s consistency in generating unbiased content. The right radar chart integrates key metrics semantic similarity, sentiment neutrality, TF-IDF, and NER accuracy into a single visual, offering an at-a-glance comparison of overall model performance.
Table 2 confirms Llama’s dominance in the economics domain, where it ranks first using both min-max normalization and z-score normalization methods. Gemini claims second place with strong performance across most metrics, while Claude lands in third with stable but moderate results. OpenAI and DeepSeek occupy the lower positions across all evaluation measures. Llama’s consistent strength in semantic similarity, TF-IDF-based alignment, and NER factual accuracy firmly establishes it as the most dependable model for addressing complex economic research queries.
IOT
When analyzing all IoT domain queries collectively, Llama emerges as the leading model, achieving the highest semantic similarity (0.837), TF-IDF similarity (0.444), and NER accuracy (0.501), as highlighted in Table 1 and Figure 6. OpenAI and Claude also perform well, with OpenAI ranking second in semantic similarity (0.832) and Gemini ranking second in TF-IDF similarity (0.432), while Claude demonstrates notable strength, particularly in NER accuracy (0.395). Gemini shows moderate performance, achieving a semantic similarity score of 0.822 and NER accuracy of 0.368, indicating solid, though not leading, results. DeepSeek consistently underperforms, especially in TF-IDF similarity (0.210), highlighting greater lexical hallucination. Sentiment neutrality remains low across all models, consistent with expectations for technical IoT-focused content. Overall, Llama stands out as the most reliable and factually consistent model for IoT queries, with Gemini and Claude providing strong secondary support. As illustrated in Table 2, the final rankings in the IoT domain reaffirm Llama’s position at the top, securing first place based on both min-max and z-score normalization due to its consistently strong performance across semantic similarity, factual grounding, and bias neutrality. Gemini claims second place, thanks to solid semantic alignment and moderate factual reliability. Claude ranks third, performing well in NER-based evaluations but slightly trailing in semantic similarity compared to the leaders. OpenAI and DeepSeek occupy the lower ranks, showing weaker results across most metrics. In summary, Llama proves to be the most capable and balanced model for handling IoT-related queries among all the evaluated LLMs.
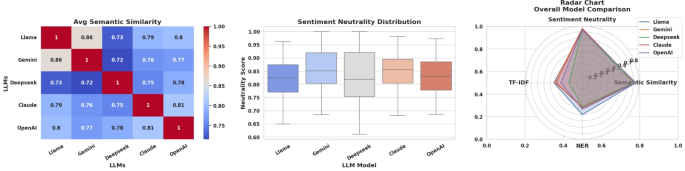
This figure presents a comparative analysis of LLMs using multiple evaluation metrics. The left heatmap shows the average semantic similarity scores across models, reflecting how closely their responses align in meaning. The middle box plot displays sentiment neutrality distributions, indicating each model’s ability to generate unbiased and objective content. The right radar chart offers an integrated view of model performance across four key metrics: semantic similarity, sentiment neutrality, TF-IDF similarity, and NER-based accuracy, facilitating holistic model comparison.
Medical
The broader evaluation of all medical domain queries is illustrated in Figure 7 and Table 1. Llama maintains the highest overall semantic similarity score (0.841), followed closely by Gemini (0.831). Claude records the lowest semantic similarity (0.775) among the evaluated models. Sentiment analysis continues to show uniformly neutral outputs, as expected for technical and policy-focused content. In factual consistency metrics, Llama once again leads, achieving the highest TF-IDF similarity (0.411), reflecting strong grounding in the source material. Overall, Llama demonstrates the most balanced performance across both semantic and factual dimensions for medical-related queries.
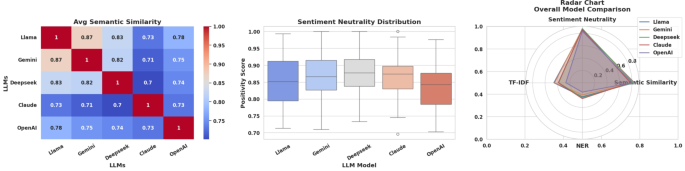
This figure compares LLM performance using three visualizations. The left heatmap illustrates the average semantic similarity between models, indicating the alignment of their outputs in terms of meaning. The middle box plot shows the distribution of sentiment positivity scores, capturing how positively each model responds. The right radar chart provides an integrated performance view across semantic similarity, sentiment neutrality, TF-IDF similarity, and NER accuracy, enabling a comprehensive comparison of model strengths.
Table 2 confirms Llama’s leadership in the final rankings for the medical domain, as it secures the top position under both min-max normalization and z-score normalization evaluation strategies. Deepseek claims second place with strong performance across most metrics, while Gemini lands in third with stable but moderate results. Claude and OpenAI occupy the lower positions across all evaluation measures. Llama’s consistent strength in semantic similarity, TF-IDF-based alignment, and NER factual accuracy firmly establishes it as the most dependable model for addressing complex medical research queries.
Overall comparison
The major insights and findings reveal that our comprehensive evaluation of five leading large language models (LLMs) across diverse domains – agriculture, biology, economics, IoT, and medical – uncovers distinct performance patterns and demonstrates significant variations in model capabilities across different specializations. This assessment, grounded in metrics like semantic similarity, sentiment neutrality, TF-IDF similarity (reflecting factual grounding), and NER-based accuracy (capturing entity recognition), offers a comprehensive, data-driven perspective on the capabilities and shortcomings of Llama, Gemini, Claude, OpenAI, and DeepSeek. Figure 8 illustrates the Semantic and NER Score heatmap across all domains. According to Figure 9 and Table 3 Llama emerges as the standout model, achieving the highest average final score of 1.629. Its dominance is fueled by leading scores in semantic similarity (0.786), TF-IDF alignment (0.878), and NER accuracy (0.416), highlighting its strength in producing contextually accurate, factually grounded, and entity-rich responses. Though its sentiment neutrality score (0.451) is moderate, this neutrality is well-suited for technical and scientific discourse. Trailing Llama, Claude, and Gemini earn final scores of 1.183 and 1.060, respectively. Claude demonstrates balanced strength across all evaluation metrics, particularly excelling in factual coherence. Gemini, while scoring slightly lower in NER score (0.270), compensates with strong sentiment and TF-IDF results.
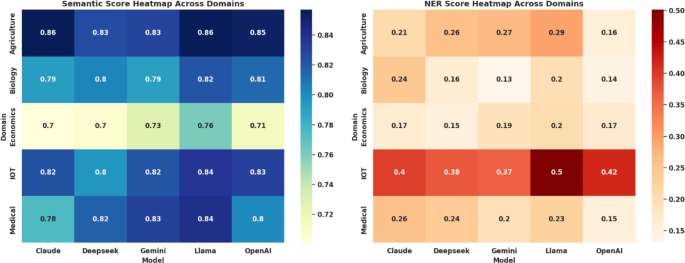
Comparative Heatmap of Semantic and Named Entity Recognition Scores Illustrating Domain-Specific Strengths of Five Language Models.
OpenAI and DeepSeek round out the rankings, with final scores of 1.023 and 0.686. Although both models show moderate performance in semantic similarity, they struggle in sentiment analysis, TF-IDF and NER-based metrics, indicating weaknesses in maintaining factual correctness and precise language, particularly critical in fields like healthcare and economics. A deeper domain-specific analysis, as detailed in Table 4, confirms Llama’s versatility, with the model leading in agriculture (0.716), biology (0.508), economics (0.531), IoT (0.957), and medical (0.671) domains. Semantic similarity heatmaps further illustrate Llama’s consistent excellence, particularly in agriculture (0.86), IoT (0.84), and medical (0.84). While Gemini and OpenAI show strong results in certain areas, neither matches Llama’s across-the-board consistency.
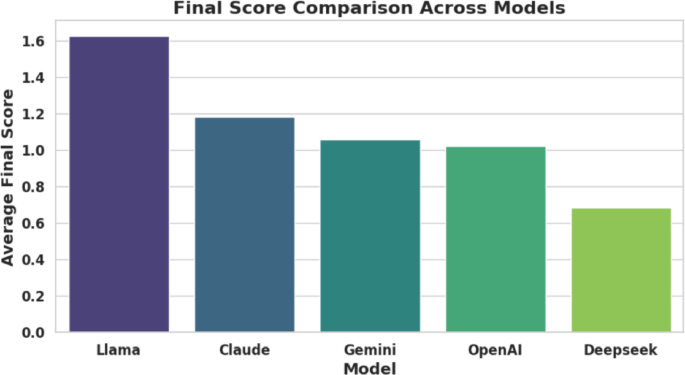
Model-Wise Aggregated Score Visualization Reflecting General Effectiveness and Robustness Across Evaluation Metrics.
Overall, these findings emphasize the necessity of using multi-metric evaluation frameworks when choosing LLMs for knowledge-intensive tasks. High semantic similarity ensures contextual precision, while strong TF-IDF and NER metrics safeguard factual reliability and domain-specific expertise-critical factors for deploying LLMs effectively across diverse fields such as agriculture, biology, economics, medical, and IoT.
A comparative analysis of five prominent LLMs Llama, Gemini, Claude, OpenAI’s GPT-4 Turbo, and DeepSeek reveals clear performance variations. Llama, in particular, demonstrates strong and consistent performance across all examined domains, suggesting a high degree of adaptability and general-purpose capability. The findings also reveal that some models are designed as generalists, while others excel in specific fields, likely due to differences in training data composition and model architecture. Training data quality appears to be a major factor influencing model performance. Models like Llama and Gemini show high semantic coherence and relatively low rates of factual error, which can be attributed to well-curated and balanced training datasets. On the other hand, DeepSeek exhibits weaker performance on TF-IDF and NER metrics, which may stem from a reliance on broader, less domain-focused data. This can lead to more frequent factual inconsistencies, particularly in complex technical domains. Sentiment analysis further supports the idea that models trained on domain-specific content tend to generate more neutral and objective responses a desirable characteristic for academic and technical discourse.
Limitations
While the MultiLLM-Chatbot framework offers a structured way to evaluate LLMs, several limitations should be acknowledged. The dataset, which consists of 50 research articles across five domains, is balanced but may not fully capture the breadth of scholarly writing, limiting how broadly our findings can be applied. Additionally, the 1,250 model responses, while diverse, may still carry biases related to source geography, discipline, or annotation. Our hallucination detection approach, based on TF-IDF and NER alignment, effectively flags surface-level errors but may miss deeper issues like paraphrased misinformation or logical gaps, which is especially concerning in sensitive fields like medicine or law.