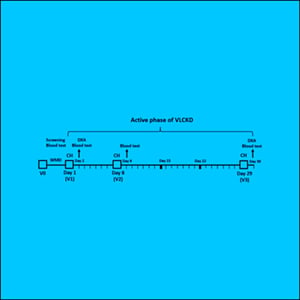
Alessio Basolo, Paolo Piaggi, Valentina Angeli, Paola Fierabracci, Chiara Bologna, Edda Vignali, Daniela Troiani, Roberta Jaccheri, Caterina Pelosini, Melania Paoli, Guido Salvetti, Luca Chiovato, Jonathan Krakoff, Alberto Landi,…
Effects of 1-Month Very-Low-Calorie Ketogenic Diet on 24-Hour Energy Metabolism and Body Composition in Women With Obesity