
Introduction
The COVID-19 pandemic, instigated by the SARS-CoV-2 virus, has precipitated an unprecedented global health crisis, fundamentally altering societal behaviors and interactions worldwide [-]. Approaching its fifth year, SARS-CoV-2 continues global evolution, manifesting heterogeneous resurgence patterns that have established COVID-19 as an endemic challenge. Sustained surveillance and adaptive public health strategies are needed to address the multiple determinants of disease transmission and outcomes. The global outbreak has demonstrated significant temporal variability, driven by multiple interacting factors that contribute to diverse disease outcomes, collectively referred to as COVID-19 burden metrics [,]. The emergence of immune-evasive variants, coupled with waning immunity from vaccination and prior infections, has created a dynamic epidemiological landscape where COVID-19 burden is assessed through multiple indicators, including the effective reproduction number (Rt), hospitalizations, intensive care unit (ICU) admissions, and mortality rates [,]. These metrics display marked heterogeneity across populations, reflecting the pandemic’s complexity.
Existing literature has extensively explored the effects of nonpharmaceutical interventions (NPIs), vaccination strategies, population mobility, and the strategic allocation of health care resources in curtailing the pandemic’s impact [-]. However, despite extensive vaccine coverage and the development of variant-specific boosters, heterogeneous COVID-19 burden persists, challenging our understanding of population-level immunity dynamics []. The complexity arises from multiple interacting factors —hereafter termed “systematic factors”, defined as the interconnected viral, host, environmental, and intervention-related determinants that collectively shape disease transmission and severity patterns [-]. While vaccination remains essential for controlling variant spread and reducing severe outcomes, its protective efficacy demonstrates temporal decline and variant-specific limitations [-]. The immunological landscape is further diversified by heterogeneous immunity patterns across populations, shaped by natural infection history, vaccination coverage, and potential cross-protection from routine immunizations [-]. Environmental factors, particularly temperature and humidity variations, also modulate transmission dynamics [-].
Recent artificial intelligence (AI) advances have enabled integration of high-dimensional pandemic data for mechanistic understanding [-]. Explainable AI XAI) methods, particularly those applied in clinical decision support systems, have demonstrated the capacity to balance predictive accuracy with interpretability—a critical requirement for translating algorithmic insights into actionable clinical and public health decisions [,]. Machine learning models, particularly ensemble methods, demonstrate superior performance in capturing nonlinear interactions between viral evolution, population immunity, and environmental factors [,]. However, a critical limitation persists: many high-performing models function as “black boxes,” obscuring mechanisms and limiting actionable public health insights [,]. This has motivated a paradigm shift toward interpretable machine learning, where Shapley Additive Explanations (SHAP) enables mechanistic decomposition of complex predictions into individual feature contributions [,]. Recent studies have applied SHAP-interpreted ensemble models to disentangle vaccination, variant, and policy effects on COVID-19 outcomes, demonstrating that interpretable approaches can simultaneously achieve high performance while revealing factor-specific effects and threshold dynamics [-].
Current research predominantly focuses on discrete disease outcomes or specific contributing factors, often using cross-sectional or short-term study designs that inadequately capture the pandemic’s temporal dynamics. These fragmented approaches are particularly problematic in the context of co-circulating variants and heterogeneous immune landscapes, which interact with environmental conditions in complex, time-varying patterns. Three key questions remain inadequately addressed: (1) “How do relative contributions of systematic factors shift across disease severity outcomes?”, (2) “What quantitative thresholds exist where vaccination coverage, natural infection rates, and environmental parameters transition from promoting to suppressing disease burden?”, and (3) “Can cross-protective effects from routine immunizations be systematically quantified with dose-response relationships?” Addressing these gaps requires integrated longitudinal analysis of multifactorial influences on COVID-19 burden metrics.
To address these questions, this study uses big data analytics and interpretable machine learning, analyzing longitudinal datasets from 38 nations to evaluate multifactorial influences on COVID-19 burden metrics. Using extreme gradient boosting XGBoost (extreme gradient boosting) regression models integrated with SHAP [-], we systematically evaluate variables, including policy interventions, migratory trends, health care infrastructure, environmental parameters, viral variant characteristics, vaccination campaigns, and non-COVID-19 immunization programs. We selected XGBoost+SHAP because: (1) XGBoost captures complex nonlinear interactions without requiring prior functional form specification—critical for unknown variant-immunity-environment relationships; (2) SHAP yields consistent local/global attributions that can be aggregated over time and domains to derive interpretable thresholds and uncertainties; (3) our objective prioritizes mechanistic interpretation (quantifying factor contributions, identifying thresholds) over predictive optimization, making interpretable ensemble learning optimal. This approach disentangles the direct and indirect effects exerted by multifaceted determinants on COVID-19 burden metrics. Our methodological approach harnesses large-scale, time-series big data, facilitating a comprehensive examination of multifactorial influences on COVID-19 severity over time, while integrating multiple data sources that capture the evolving interplay between pathogen characteristics, host immunity, and environmental conditions. We hypothesize that systematic COVID-19 burden determinants exhibit hierarchical, threshold-dependent effects that shift across disease severity outcomes, with viral factors dominating transmission while immunity-related and environmental factors increasingly modulate severe disease through nonlinear mechanisms. Through multidimensional big data-driven interpretable machine learning integrating viral surveillance, immunization records, and environmental monitoring, we aim to quantify the dynamic influences of these factors on evolving disease burden for evidence-based pandemic preparedness.
Methods
Study Design
This study uses a retrospective longitudinal, multicountry observational design using big data analytics and interpretable machine learning to systematically evaluate the multifactorial determinants of COVID-19 burden metrics. The analytical framework integrates heterogeneous time-series data from 38 countries across 5 continents, spanning from the onset of confirmed cases in each country through December 31, 2022. Our approach comprises four sequential phases: (1) multisource data collection and harmonization, (2) temporal feature engineering with lag optimization, (3) XGBoost-based modeling with time-series cross-validation, and (4) SHAP-based interpretability analysis to quantify dynamic temporal influences and identify threshold effects. The study leverages publicly available, deidentified aggregate-level epidemiological data, thereby circumventing individual participant recruitment. This design enables a comprehensive examination of the dynamic relationships between viral evolution, population immunity, environmental conditions, and disease outcomes from a global perspective. Reporting was guided by the Critical Appraisal Skills Programme checklist for descriptive studies; the completed checklist is provided in the .
Data
Setting and Study Period
The study encompasses 38 countries distributed across 5 continents (detailed in Table S1 in ), selected based on the highest regional disease burden as measured by cumulative cases, hospitalizations, and mortality rates within their respective geographical areas. Collectively, these 38 countries represented over 60% of both the global population and the global COVID-19 burden as of December 31, 2022, thereby providing substantial representation of global pandemic patterns despite potential surveillance heterogeneity across nations. The observation period extends from the date of the first confirmed COVID-19 case in each country. This endpoint represents a methodologically justified cutoff, corresponding to the final period of consistent global surveillance prior to the World Health Organization’s (WHO’s) recategorization of COVID-19’s public health emergency status in early 2023. Post-2023, substantial heterogeneity in national reporting practices emerged, with many countries discontinuing systematic documentation of key burden metrics, thereby compromising data completeness and cross-national comparability. The study period encompasses multiple global pandemic waves, including the emergence and circulation of major variants of concern (Delta and Omicron lineages), providing sufficient temporal depth to capture recurring patterns in transmission dynamics and disease severity across diverse epidemiological contexts.
Data Collection and Scope
This research compiles a comprehensive dataset encompassing key indicators of COVID-19 burden metrics across 38 countries. These indicators include Rt, hospitalizations, ICU admissions, and deaths, tracking the pandemic’s trajectory from the onset of confirmed cases in each country through December 31, 2022.
Outcome Variables and Assessments
This study defines four primary outcome variables representing the spectrum of COVID-19 disease burden, assessed as daily time-series data for each country: (1) Transmission potential (effective reproduction number [Rt], representing the average number of secondary infections generated by each infected individual at time t); (2) Hospitalization burden (daily new hospital admissions per million population attributable to COVID-19); (3) Intensive care burden (daily new ICU admissions per million population for COVID-19 patients); and (4) Mortality burden (daily COVID-19-attributed deaths per million population).
Data Categories and Sources
Overview
Previous studies have established various factors that may influence COVID-19 disease burden, including viral variants, vaccination coverage, population mobility, NPI policies, and health care capacity [-]. Additionally, some factors such as routine immunization history and environmental conditions have been hypothesized to affect COVID-19 outcomes, though their impacts remain to be fully elucidated [-]. To comprehensively examine these established and potential determinants, the study systematically collects data from diverse, reliable platforms, encompassing several epidemiological aspects related to COVID-19 burden metrics. The analysis includes 65 independent potential factors serving as covariates in the modeling framework. Specifically, the collected data encompasses the following sections.
COVID-19 Burden Data
Daily data on Rt, hospitalizations, ICU admissions, and mortality rates were sourced from Our World in Data via CSV download with daily extraction timestamps. Data validation involved cross-checking against Johns Hopkins University CSSE COVID-19 Data Repository and national health ministry reports for 10 randomly selected country-date combinations monthly, with >95% concordance observed.
Natural Infection–Related Group
Two epidemiological factors are extracted from Our World in Data: Daily new cases per million population (measured as 7-day rolling average to smooth reporting irregularities) and cumulative cases per million population (calculated as a cumulative sum from pandemic onset, serving as a proxy for population-level exposure and acquired immunity).
Variant-Related Group
We monitor the temporal composition of 13 dominant strains during the pandemic, focusing on variants that demonstrate cross-continental transmission capabilities and are classified as variants of concerns by the WHO. Specifically, for each of the 38 countries, we calculate the weekly proportions of major SARS-CoV-2 lineages, including Delta variants (Nextstrain: 21A [B.1.617.2], 21I [AY.4], 21J [AY.2]) and Omicron variants (Nextstrain: 21K [BA.1], 21L [BA.2], 21M [BA.3], 22A [BA.4], 22B [BA.5], 22C [BA.2.12.1], 22D [BA.2.75], 22E [BQ.1], 22F [XBB], and 23A [BA.2.86]). The proportion is calculated by dividing the number of sequences for each variant by the total number of sequences submitted that week within each country, using data sourced from covariants via weekly automated data pulls. Weekly proportions are forward-filled to daily resolution to align with the outcome variable’s temporal granularity. Sequencing coverage varies by country, with variant proportions assumed representative of circulating strains based on established genomic surveillance methodologies. These lineages are selected based on the Nextstrain naming system, which provides sequential identifiers reflecting the temporal emergence of each lineage, with corresponding Pango lineage designations provided in brackets for clear reference.
COVID-19 Vaccine–Related Group
Six vaccination-related factors are obtained from Our World in Data, including daily vaccine doses administered (total doses given on each day), cumulative vaccine doses (running total since vaccination campaign initiation), rates of at least one dose (percentage of population with ≥1 vaccine dose), complete vaccination coverage (percentage meeting initial full vaccination criteria), and booster dose administration (percentage receiving additional doses beyond primary series). All metrics are expressed as percentages of the total national population or absolute counts per million, sourced from national immunization registries via Our World in Data aggregation.
Non–COVID Vaccine–Related Group
Ten non-COVID vaccine indicators are included, representing annual doses of vaccines administered through national immunization programs. These include Bacillus Calmette–Guérin (BCG), Diphtheria tetanus toxoid and pertussis, Hepatitis B, Haemophilus influenzae type b, human papillomavirus, Measles (measles-containing vaccine), Pneumococcal (pneumococcal conjugate vaccine), Poliomyelitis, Rubella (rubella-containing vaccine), Rotavirus, and yellow fever vaccines (YFVs), which are sourced from the WHO’s vaccine coverage reports. Data represent total annual doses administered nationally, reported by member states through WHO-UNICEF (United Nations Children’s Fund) joint reporting forms. Annual values are uniformly distributed across days within each calendar year for temporal alignment with daily COVID-19 metrics.
Policy-Related Group
Sixteen NPIs are tracked daily using the Oxford COVID-19 Government Response Tracker. Each intervention is quantified on a (0,100) index scale to reflect the stringency of implemented measures (with 0 indicating no policy and 100 indicating maximum stringency, calculated via ordinal coding of policy intensity and geographical scope as detailed in Table S2 in ). Daily index values are extracted via API access with version control timestamps. Further details on these NPIs and the methodology for calculating the stringency index are provided in .
Health Care–Related Group
Nine health care–related factors are collected, including annual population numbers (total population), density (persons per km2), gross domestic product (GDP) per capita (constant US $), percentage of population aged 65 years and older, health care expenditure (percentage of GDP), numbers of doctors, nurses, pharmacists (per 1000 population), and hospital beds (per 1000 population) are collected from Our World in Data and World Bank Open Data. Annual values are carried forward as constant daily values within each calendar year, assuming stable health care infrastructure characteristics over short-term pandemic periods.
Environmental Group
Five environmental factors are analyzed, including daily maximum, minimum, and average temperatures (°C), relative (%), and absolute humidity (g m–3), obtained from the National Oceanic and Atmospheric Administration Global Surface Summary of the Day dataset. For each country, meteorological data are extracted from the city’s primary weather station, serving as a representative measure of national-level environmental conditions. Missing daily values (<3% of observations) are imputed using linear interpolation between adjacent days.
Migration-Related Group
Four migration-related factors are analyzed, including national-level monthly data on domestic air passenger traffic (total passengers on domestic flights) and international air passenger traffic (total passengers on international inbound/outbound flights). These data are obtained from the Official Aviation Guide via licensed data subscription. Monthly passenger counts are distributed uniformly across days within each month for temporal alignment.
Data Preprocessing and Harmonization
To ensure consistency, all time scales standardize to daily intervals using pandas time series methods, facilitating seamless integration and analysis of diverse datasets. Prior to analysis, all collected data undergo a thorough preprocessing procedure, which includes the following: (1) Missing data handling: For outcome variables (Rt, hospitalizations, ICU admissions, deaths), days with missing values are excluded from country-specific analyses (affecting <5% of total country-day observations). For predictor variables, missing values are imputed using carry-forward imputation for time-invariant factors (health care infrastructure) and linear interpolation for time-varying factors (environmental conditions, mobility). (2) Outlier detection and correction: Values exceeding 5 SDs from the country-specific rolling 30-day mean are flagged for manual verification against source databases. Confirmed data entry errors are corrected via source re-extraction; legitimate extreme values (eg, genuine outbreak peaks) are retained. (3) Temporal alignment: All variables are synchronized to daily resolution using forward-filling (policy indices, health care factors), uniform distribution (monthly migration data, annual vaccination data), or linear interpolation (environmental data gaps) as appropriate to variable characteristics.
Study Size Determination
The study size is determined by the temporal scope of the pandemic observation period and data availability across selected countries. The final analytical dataset comprises 38,908 country-day observations (38 countries × mean 1023 days per country, range: 999-1074 days depending on pandemic onset date). This sample size provides sufficient statistical power (>99% power to detect effect sizes of Cohen f2 ≥ 0.01 at α=0.05) for modeling nonlinear relationships between 65 predictor variables and 4 outcome variables across diverse epidemiological contexts. The multicountry longitudinal design enables both cross-sectional (between-country) and temporal (within-country) variation exploitation, enhancing generalizability and robustness of identified patterns.
Lag Period Optimization
The analysis systematically quantifies the lag effects of key predictors on COVID-19 burden metrics, accounting for the inherent temporal dynamics of epidemiological factors. The analytical approach differentiates between incremental and cumulative measures based on their distinct temporal patterns, necessitating tailored lag optimization methods: For incremental measures (daily new cases, daily vaccination doses, complete vaccination rates, and booster administration), which exhibit stochastic fluctuations and potential autocorrelation decay, partial autocorrelation function analysis identifies optimal lag periods by isolating direct temporal dependencies while controlling for intermediate lags—appropriate for variables where recent values may influence outcomes through short-memory processes. This method captures the strongest temporal correlations while controlling for intermediate lag effects, providing precise estimates of the most influential temporal windows for each factor (detailed in Figure S1 in ). For cumulative infection counts, which represent monotonically increasing exposures with long-memory characteristics (population immunity accumulation), a lag-specific regression framework determines the optimal lag structure for each COVID-19 burden metric through systematic Akaike Information Criterion comparison—appropriate for variables where the relevant temporal window (eg, duration of immune protection from cumulative exposure) may vary by outcome severity and requires outcome-specific optimization. This approach systematically evaluates model fit across the lag space using the Akaike Information Criterion, enabling the identification of the most parsimonious lag period that maximizes the explanatory power for each burden outcome. Figure S2 in illustrates the comprehensive lag optimization process. For migration-related factors, specifically domestic and international air passenger traffic available at monthly temporal resolution, the analysis incorporates both current-month and one-month lagged features, as the delayed impact of population movement typically manifests within this timeframe [].
The identified optimal lag periods integrate into the temporal feature set, ensuring capture of the most relevant temporal associations between predictors and outcomes. This unified and systematically organized dataset serves as the foundation for a comprehensive analysis of the multidimensional factors underlying global COVID-19 burden metrics.
Modeling for Explaining COVID-19 Burden Metric
Overview of the Machine Learning Framework
This study uses a multivariate time-series machine learning framework to develop an explanatory model that analyzes the relationships between COVID-19 burden metrics and their determinants across 38 countries. This framework enables efficient processing and integration of large-scale heterogeneous data, revealing previously unidentified epidemiological patterns and correlations. The interpretable machine learning approach is well-suited for quantifying the individual effects of multidimensional factors on COVID-19 outcomes. This methodology enhances our understanding of the underlying mechanisms driving pandemic dynamics while demonstrating the effectiveness of interpretable machine learning in analyzing complex epidemiological relationships.
Model Construction and Variables
For each country, daily time-series data of Rt, hospitalizations, ICU admissions, and deaths serve as target variables to build the XGBoost regression model. The analysis generates a comprehensive feature set that delineates the relationships between factors and outcomes across all countries. The model integrates temporally-aligned data across 8 domains: natural infection-related (2 factors), variant-related (13 factors), COVID-19 vaccination (6 factors), non–COVID-19 vaccination factors (10 factors), policy-related (16 factors), health care–related (9 factors), environmental (5 factors), and migration-related factors (4 factors) (as detailed in the Data section). All 65 factors serve as covariates in the regression framework, with no derived or composite variables constructed beyond the lag-transformed features described in the lag optimization section. The modeling approach treats these heterogeneous time-series factors as temporally-aligned covariates, enabling XGBoost to capture complex nonlinear interactions and temporal dependencies in their relationships with the 4 outcome variables. This multidomain integration enables a holistic analysis of pandemic dynamics [].
XGBoost Model Training and Cross-Validation
The XGBoost model serves as the primary analytical tool in this study [], selected for its robust fitting capabilities and widespread application in epidemiological research []. This model excels in handling complex, multidimensional time-series data, making it particularly suitable for this application. The model is implemented using the XGBoost Python library (version 1.7.3) in a Python 3.11 environment with scikit-learn (version 1.7.2) for cross-validation and hyperparameter tuning. To ensure robust model performance and generalizability, we use a nested time-series cross-validation approach accounting for both temporal dependencies and cross-national heterogeneity: (1) Country-stratified temporal splitting: For each country, the chronologically ordered daily observations are partitioned into 5 consecutive folds, preserving temporal sequence to avoid data leakage. This yields a rolling-window validation scheme where each fold serves sequentially as the validation set while prior folds constitute the training set. (2) Cross-national validation: Models trained on data from all countries are validated using the held-out temporal fold from each country, enabling assessment of generalization across both time and geographical contexts. (3) Performance aggregation: Final performance metrics (mean absolute error, root-mean-square error, and R2) are calculated as the mean across all validation folds and countries, with 95% CIs derived via bootstrapping (1000 resamples).
Factor Analysis and Model Interpretation
Overview
To quantify key factors influencing COVID-19 burden metrics and decode their relationships, we integrate SHAP into our machine learning framework []. SHAP, an interpretable machine learning technique, facilitates a detailed examination of how multidimensional variables interact with and influence outcome variables within the XGBoost model. SHAP quantifies the contribution of each factor to the outcome variable. This approach provides a granular view of the dynamic interplay among various factors over time, enabling the dissection of the relationships that define COVID-19 burden metrics. Through this methodology, SHAP offers a quantitative measure of factor contributions and decodes complex interactions among multiple variables, thus enhancing our understanding of the factors influencing COVID-19 outcomes.
SHAP Value Computation
The SHAP method, inspired by game theory, explains the predictions of machine learning models by assigning a value to each input feature [,]. This value, known as the SHAP value, signifies how each feature contributes to the prediction of a specific data point []. SHAP values are computed using the TreeExplainer algorithm (SHAP Python library version 0.42.1), which leverages the tree structure of XGBoost models to efficiently calculate exact Shapley values. It identifies factors with positive influence (promotive effect, SHAP values > 0) and those with negative influence (inhibitory effect, SHAP values < 0) on the predicted outcome variable. The computation of SHAP values is formalized as follows:
where the i-th sample of the N-th feature is defined as xiN, the reference value of the model (the mean value of the sample target variable) is ybase, and f(xiN) is the SHAP value of xiN. We compute SHAP values for each influencing factor throughout the entire time series for every country. These values indicate the magnitude and direction of each feature’s effect on the model output (fitted values of COVID-19 burden metrics).
Factor Importance Quantification: SHAP-PCA Integration
The overall importance of factors in this study is quantified by averaging the absolute SHAP values across all time points for each country. These factors are categorized into 8 distinct groups, including policy-related, migration-related, and COVID-19 vaccine–related factors. Principal component analysis (PCA), a dimensionality reduction technique suitable for high-dimensional data, reduces the SHAP value dimensions within each category to a singular, representative impact value. This process effectively transforms the multifaceted nature of these variables into a single dimension, reflecting their cumulative effect—a composite impact indicator of the diverse factors. The Mann-Whitney U test, a nonparametric method, is used to assess the statistical significance of differences between factor categories. This test is selected for its robustness against nonnormal distributions and its capability to handle independent samples of different sizes. Pairwise comparisons are conducted between all factor categories, with statistical significance defined as P<.05. This rigorous statistical approach enables quantitative evaluation of the relative importance of different factor categories in determining COVID-19 burden metrics.
Temporal Dynamics and Global Trends
The analysis plots simplified category-wise SHAP values across the time series to assess temporal dynamics of factor categories, providing a visual representation of category heterogeneity over time. Within-category Z-score normalization of SHAP values, constrained to a (–1,1) range, enhances the visualization of temporal patterns and facilitates meaningful intercategory comparisons. This standardization procedure effectively highlights the relative temporal variations within each factor category while maintaining their interpretability and comparative significance. This approach aids in evaluating fluctuating category dependencies on various COVID-19 burden metrics. Global trends emerge through the analysis of average PCA-reduced SHAP values across all countries.
SHAP Dependency Analysis and Effect Curves
SHAP partial dependence plots reveal dependency relationships between high-contribution factors and COVID-19 burden metrics () []. These plots demonstrate the marginal relationships between individual factors and COVID-19 burden metrics. Generalized additive models (GAM) with cubic spline smoothing are fitted to the SHAP values across the feature range to quantify these relationships systematically. GAM fitting is implemented using the pyGAM Python library (version 0.8.0) with 20 spline basis functions and a second-order penalty (λ optimized via generalized cross-validation). The GAM-fitted effect curves, accompanied by 95% CIs, capture nonlinear patterns in the feature-outcome relationships. The 95% CIs are derived via simultaneous inference procedures accounting for multiple comparisons across the feature range, providing conservative uncertainty bounds for threshold identification. These curves emphasize trend transitions across the SHAP=0 decision boundary, which represents the critical threshold between risk reduction (SHAP<0) and risk elevation (SHAP>0) for COVID-19 outcomes. Mean SHAP values for high-contribution factors function as reference thresholds, facilitating the identification of factor-specific impact zones. This integrated analytical framework demonstrates both the direction and magnitude of factor effects while accounting for uncertainty in the estimated relationships.
Ethical Considerations
This study was approved by the Institutional Review Board of Shantou University (approval number: STU202510002, approval date: October 28, 2025). The study exclusively uses publicly available, deidentified, aggregate-level epidemiological data from national and international health agencies, thereby not constituting human subjects research requiring individual informed consent. All data sources used provide data under open access licenses permitting academic research use. No individual-level patient data are collected, accessed, or analyzed; all metrics represent population-level aggregates, ensuring complete anonymization and elimination of privacy risks. The research involves no direct participant recruitment or clinical interventions, and no compensation was provided to participants. Data governance complies with institutional policies for secondary analysis of public health surveillance data, with no ethical concerns regarding confidentiality, consent, or participant identification.
Results
Global Contributions and Temporal Dynamics of COVID-19 Burden Drivers
Through comprehensive big data analytics and machine learning approaches, we delineate the differential contribution patterns among factor groups to various COVID-19 burden metrics (including transmission potential: Rt, hospitalizations, ICU admissions, and mortality rates) by implementing the XGBoost model in conjunction with SHAP values. The analytical framework encompasses SHAP importance analysis across the entire pandemic period (A), while using the PCA algorithm to visualize the contributions and temporal evolution of each factor group (B). The model’s performance metrics were rigorously validated through time-series cross-validation across all 38 countries (Tables S3 and S4 in ). Robustness analyses confirmed stable factor group contribution rankings across sensitivity scenarios (Figure S4 in ).
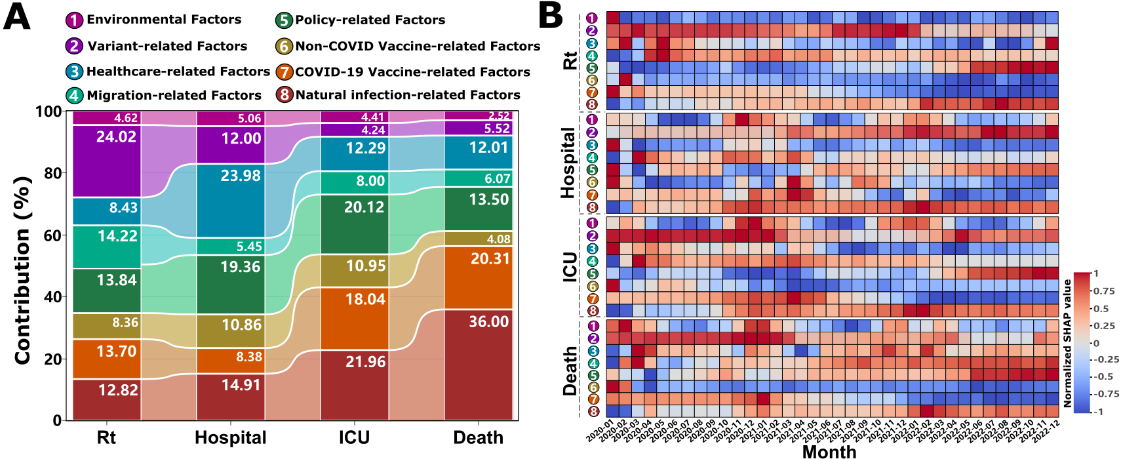
Our findings, illustrated in A and Table S5 in , show that the variant-related group has the highest contribution 24.02% (95% CI 10.10%-66.88%) to COVID-19 transmission (Rt), but its influence decreases dramatically with increasing disease severity (only 4.24% [95% CI 1.59%-10.89%] and 5.52% [95% CI 1.94%-15.39%] for ICU admissions and deaths, respectively). The immunity-related group, including natural infection-related, COVID-19 vaccine–related, and non-COVID vaccine-related factors, emerges as a consistently important contributor across all burden metrics. Specifically, the average contribution of natural infection-related factors showed an ascending pattern of contribution with increasing disease severity, progressively increasing from 12.82% for transmission and 14.91% for hospitalization to 21.96% and 36.00% of the variance in ICU admissions and deaths, respectively. Similarly, the COVID-19 vaccination–related factors maintain substantial contributions to severe outcomes (18.04%, 95% CI 6.39%-42.49% for ICU admissions and 20.31%, 95% CI 6.53%-58.31% for deaths), although its influence on transmission and hospitalization is relatively lower (13.70%, 95% CI 3.85%-35.51% and 8.38%, 95% CI 3.50%-22.29%, respectively). Notably, routine immunization (non–COVID-19 vaccines) demonstrated meaningful contributions (ranging from 4.08%, 95% CI 1.52%-11.48% to 10.95%, 95% CI 4.27%-53.05%) across all metrics, with particularly pronounced effects on hospitalization and ICU admissions. The health care–related group exerted the strongest influence on hospitalization outcomes (23.98%, 95% CI 7.03%-73.13%), where higher per capita GDP and nursing staff density bolstered resilience, albeit modulated by population size (Figure S5 in ). Policy interventions significantly shaped disease burden (Figure S6 in ), and migration factors substantially drove transmission dynamics (averaging 14.22% of Rt variation, Figure S7 in ), whereas environmental impacts were consistently modest (<5%, A). Disaggregating these, age structure (proportion ≥65 years) showed minimal contributions to transmission (0.33%, 95% CI 0.01%-2.15%) and hospitalization (0.53%, 95% CI 0.02%-3.28%) but markedly higher for ICU admissions (1.55%, 95% CI 0.03%-9.96%) and mortality (1.72%, 95% CI 0.15%-6.00%), underscoring a distinct age-severity gradient. Conversely, health care infrastructure (including the number of doctors, nurses and pharmacists, medical input and beds) most affected hospitalization burden (12.54%, 95% CI 0.37%-48.88%), exceeding its influence on ICU (8.21%, 95% CI 0.28%-35.67%) and mortality (6.43%, 95% CI 0.19%-28.54%), indicating its primary role in modulating admission thresholds rather than altering ultimate severe outcomes (Table S5 in ).
Temporal epidemiological analysis reveals dynamic patterns in factor group influences throughout the pandemic (B). For interpretative purposes, normalized SHAP values approaching 1 indicate strong positive contributions (promoting increased disease burden), while values nearing –1 suggest substantial negative contributions (suppressive effect on disease burden). The variant-related group generally exerts promoting effects on COVID-19 burden metrics, particularly during the initial outbreak phase (January 2020 to January 2021), as evidenced by increasing red intensity (B). While the magnitude of these effects generally attenuates over time, Rt presents a notable exception, demonstrating persistently strong promoting effects from July 2021 to January 2022 (B depicts the variant-related group for Rt). This period coincides with the global dominance of the highly transmissible Delta 21J and Omicron 21K variants. Subsequently, following the widespread implementation of mass vaccination programs globally (post-March 2021), COVID-19 vaccines demonstrate an immediate and pronounced suppressive effect on transmission. This protective immunity is sustained over time, reflected by increasingly negative SHAP values (blue intensity, B, COVID-19 vaccine–related group for Rt). A one-to-three-month lag is observed before similar suppressive effects manifested across other burden metrics (B, COVID-19 vaccine-related group for hospitalization, ICU admissions, and deaths, respectively). Non–COVID-19 vaccines consistently exhibit long-term protective effects (B, non–COVID-19 vaccine–related group). Conversely, factors related to natural infection potentially contribute to an increased disease burden during the endemic phase of the pandemic (post-2022, B depicts the natural infection-related group). Intriguingly, the environmental group demonstrates distinct seasonal patterns of influence on hospitalization, ICU admissions, and mortality rates (B, environmental group for hospitalization, ICU admissions, and deaths, respectively). Specifically, these factors exhibit a propensity to promote increased disease burden during the winterspring seasons (November to March). Conversely, a protective influence is observed during the summer-autumn periods (April to September), suggesting a seasonal modulation of environmental risk factors.
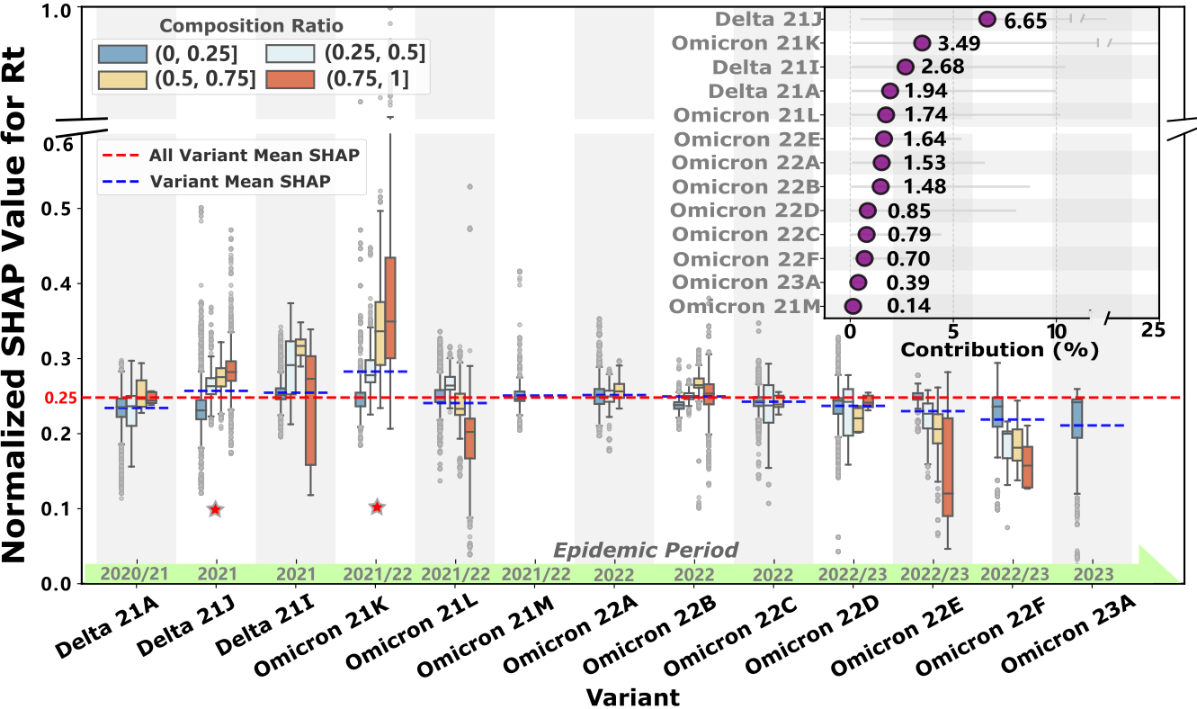
Impact of SARS-CoV-2 Variant Prevalence on Transmission Dynamics
Given that the variant-related group emerges as the predominant contributor to Rt (24.02%, 95% CI 10.10%-66.88%), shown in A, we conduct a detailed analysis of how the prevalence of different variants influences COVID-19 transmission dynamics. We standardize the SHAP values of 13 major variants that have circulated during the pandemic to enable systematic comparison of their transmission potential.
As shown in , the baseline means transmission intensity (red line) across all variants is 0.25 (normalized SHAP value). Six lineages exceed this threshold: Delta (21J, 21I) and Omicron (21K, 21M, 22A, 22B). Notably, Delta 21J (contribution: 6.65%, 95% CI 0.49%-20.76%) and Omicron 21K (contribution: 3.49%, 95% CI 0.1%-25.22%) demonstrate stronger transmission potential with increasing prevalence (marked with asterisks in ). Their normalized SHAP values of 0.26 and 0.28, respectively, indicate transmission intensities 3.4% and 12.2% higher than the baseline. This finding aligns with the pronounced transmission peaks observed during their predominant circulation period (July 2021 to January 2022) as shown in B. Interestingly, several variants were displaced by competing lineages before achieving widespread dominance (eg, Omicron 21M, 22A, and 23A). Meanwhile, some variants, such as Omicron 22E and 22F, exhibited weakening transmission potential with increasing prevalence during their dominance period (August to December 2022, B), ultimately leading to their gradual replacement.
Global Impact of Natural Infection and Immunization Factors on COVID-19 Burden Metrics
Building upon the overall factor importance analysis, we find that infection and immunization-related factors (including natural infection, COVID-19 vaccination, and non–COVID-19 immunization) are critical determinants of all COVID-19 burden metrics. Collectively, these factors average account for 34.88% to 60.39% of the total feature contribution, with a notably higher contribution for severe burden metrics such as ICU admissions and mortality (A). To elucidate the specific effects of these key factors, we conduct SHAP dependence analyses to assess their nonlinear relationships with COVID-19 burden metrics.
Following infection, the resultant immune protection demonstrates a lagged effect (Figure S1A and Figure S2A in ), effectively controlling the Rt growth (A). This inhibitory effect intensifies with increasing numbers of new infections. Notably, this inhibitory effect becomes more pronounced with higher levels of both new and cumulative infections (Figure S8A in ), suggesting that both recent infection waves and accumulated population immunity can significantly disrupt subsequent transmission dynamics. In contrast, for more severe outcomes—hospitalization, ICU admissions (B/C), and mortality (D)—new infections amplify the burden. For mortality, the relationship is particularly striking: higher levels of new infections consistently exacerbate fatal outcomes (D). Regarding cumulative infection rates, ICU admissions exhibit a strong positive association when the cumulative infection rate is below 10% (ie, fewer than 100,000 cases per million people), indicating a rapid escalation in ICU admissions during early outbreak phases (Figure S8C in ). Beyond this threshold, the effect on ICU burden is more moderate, albeit still positive. For mortality (Figure S8D in ), while a similar pattern is observed, cumulative infection rates exceeding 50% appear to reduce mortality burdens, as indicated by SHAP values below the reference line. This finding implies potential population-level protective effects, possibly attributed to acquired immunity in highly infected populations.
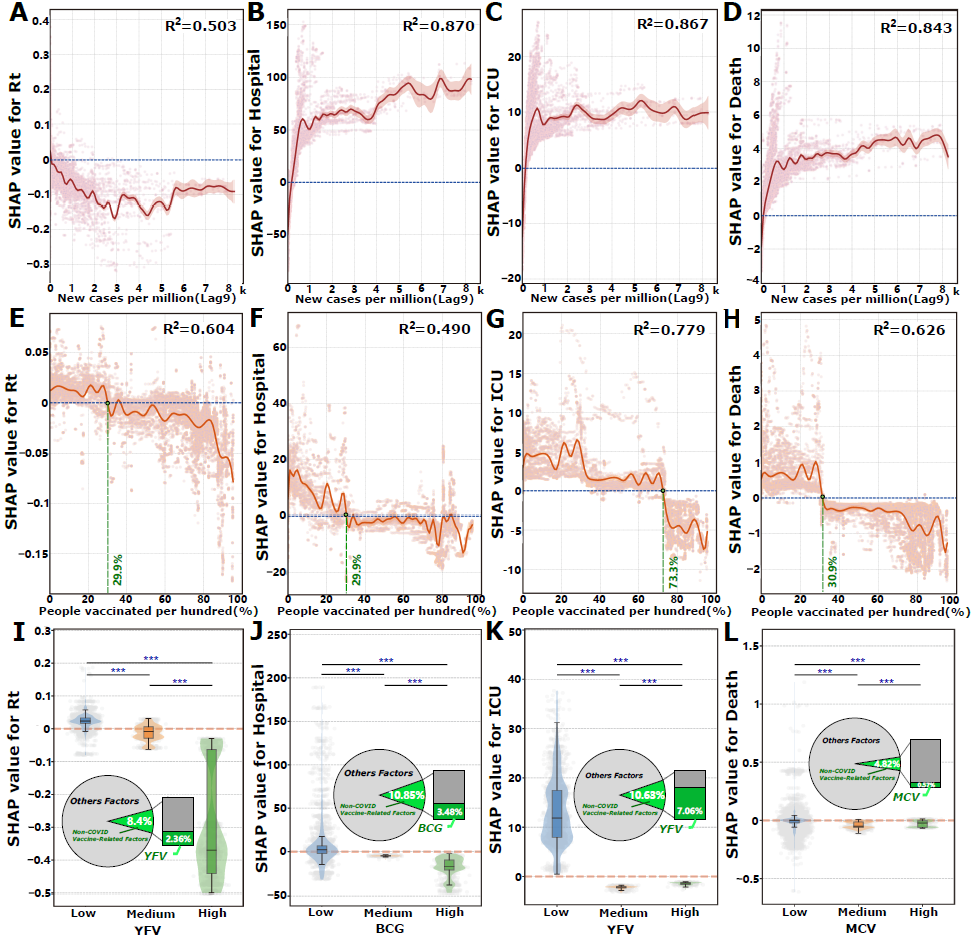
From an immunization perspective, increasing the proportion of the population vaccinated consistently exerts a suppressive effect on all burden metrics (E-H). This relationship is nonlinear and exhibits threshold effects, wherein surpassing specific vaccination rates enhances the efficacy of burden reduction. The identification of these critical vaccination thresholds is grounded in SHAP-based risk decision boundary analysis: threshold values are defined as the vaccination coverage levels where the GAM-fitted SHAP curve crosses zero (transition from positive to negative marginal effects on disease burden), with statistical significance confirmed by nonoverlapping 95% CIs before and after the threshold point. Specifically, vaccination rates of 29.9% (95% CI 29.8%-29.9%) suppress Rt, 29.9% (95% CI 29.4%-31.4%) reduce hospitalization rates, 72.3% (95% CI 72.2%-72.8%) diminish ICU admissions, and 30.9% (95% CI 30.7%-31.1%) decrease mortality. Additionally, we assess the impacts of complete vaccination and booster doses on COVID-19 burden metrics (Figure S9 in ).
Our analysis reveals that certain non–COVID-19 routine immunizations, particularly those with high contribution scores, are found to suppress COVID-19 burdens, especially when administered at medium to high doses. For instance, high-dose administration of the YFV (>600,000 doses) significantly reduces Rt (I). A similar dose-response relationship is observed for ICU admissions, where YFV doses exceeding 100,000 (medium or high dose levels) exhibit a protective effect (K). For other burden metrics, BCG vaccination exceeding 450,000 doses leads to a modest reduction in hospitalizations (J), while the measles-containing vaccine administration exceeding 10 million doses reduces mortality burdens (L). The statistical significance of these dose-based thresholds is confirmed using Mann-Whitney U tests (P<.01).
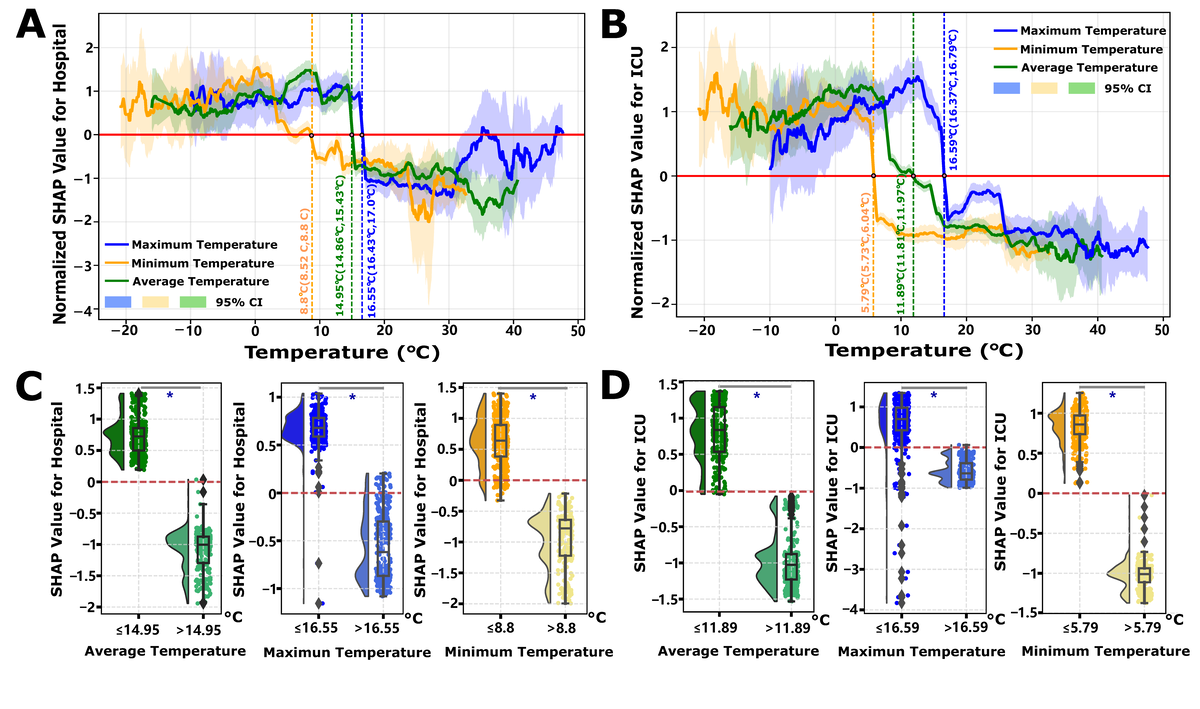
Seasonal Modulation of Environmental Factors on COVID-19 Burden Metrics
Our previous analysis reveals that the composite effect of environmental factors, derived via PCA on multivariate environmental time-series data, exhibits heterogeneous patterns of promotion and inhibition across the majority of COVID-19 burden metrics (B). Notably, despite these observable periodic influences, the majority contribution of the environmental group remains below 5%. To elucidate the determinants underlying the heterogeneous risk modulation induced by environmental factors, we used SHAP local dependency analysis. Our findings highlight that temperature emerges as a regulatory factor, with its overall contribution accounting for 1.37% (95% CI 0.06%-5.73%) and 1.59% (95% CI 0.14%-4.42%) of the variance in hospital and ICU admissions, respectively. In contrast, humidity contributed 1.46% (95% CI 0.07%-5.51%) and 0.29% (95% CI 0.008%-1.18%) to hospital and ICU admissions, respectively (Figure S3 and Table S5 in ).
Leveraging extensive temporal environmental data, a more granular examination of temperature reveals the existence of distinct risk decision boundaries. The determination of temperature thresholds follows a SHAP-based risk transition framework: for each temperature variable (mean, minimum, and maximum), we fit GAM curves to SHAP values across the observed temperature range and identify the threshold as the temperature value where SHAP=0, representing the decision boundary between risk elevation (SHAP > 0, promoting disease burden) and risk reduction (SHAP<0, suppressing burden). Statistical significance is confirmed by nonoverlapping 95% CIs of SHAP values in the temperature ranges immediately below versus above the threshold (P<.05 via bootstrap resampling). Specifically, lower temperatures are associated with an increased burden of both hospital and ICU admissions, whereas higher temperatures appear to confer a protective effect, mitigating these burdens. The analysis identifies precise temperature thresholds acting as risk transition points: for hospital admissions, the temperature threshold is determined to be 14.95°C (with a minimum and maximum temperature ranging from 8.8°C to 16.55°C, A), and for ICU admissions, the threshold is identified at 11.89°C (ranging from 5.79°C to 16.59°C, B). Importantly, the determination of these temperature thresholds—encompassing average, maximum, and minimum temperatures—demonstrates statistically significant differences before and after the threshold points (P<.05, C/4D). Continental stratification analyses confirmed similar temperature-dependent risk transition patterns across 5 continents, with region-specific decision boundaries for both hospitalization and ICU admissions (Figures S10 and S11 in ), validating the global threshold findings. Humidity exhibits a more complex influence on COVID-19 burden metrics. For hospital admissions, absolute humidity displays a U-shaped relationship, indicating that values outside the range of 8-16 g m–3 are associated with an increased risk (Figure S12A in ). Conversely, for ICU admissions, absolute humidity exceeding 18 g m–3 is linked to a heightened risk (Figure S12B in ). Contrary to temperature, humidity does not exhibit analogous risk threshold decision points concerning the Rt and mortality burdens (Figure S13A,B in ). Nonetheless, moderate temperature conditions (average temperatures above 15°C for Rt (Figure S13C in ) and above 5°C for mortality (Figure S13D in ) are associated with reduced risks. In these scenarios, the impact of humidity is negligible, particularly concerning mortality, where SHAP values for humidity remain close to zero, manifesting as a near-constant line (Figure S14 in ).
Discussion
Principal Findings
This study presents a multicountry, time-resolved analysis of multifactorial COVID-19 burden determinants across 38 nations, addressing the research questions and hypotheses posed in the Introduction through big data analytics integrated with interpretable machine learning. Findings are consistent with all four a priori hypotheses: (1) variants most strongly shape transmission (Rt), with attenuated influence on severe outcomes; (2) population immunity displays threshold-dependent effects that differ for transmission versus severity; (3) selected routine immunizations show dose-response associations consistent with cross-protective “trained immunity”; and (4) environmental factors modulate burden through nonlinear thresholds. Beyond hypothesis testing, 3 underrecognized patterns emerge: variant “fitness” appears shaped by contemporaneous immunity landscapes rather than intrinsic transmissibility alone; a hierarchical immunity architecture requires higher coverage to prevent severe outcomes than to reduce transmission; and population-level trained immunity from routine vaccines may contribute to resilience. Together, large-scale, multidimensional time-series data clarify how viral evolution, immunity dynamics, and environment jointly structure COVID-19 burden, yielding interpretable, hypothesis-generating metrics for preparedness [].
Variants dominate transmission (24.02% contribution to Rt, 95% CI 10.10%-66.88%) but attenuate toward severe outcomes (4.24% for ICU, 5.52% for deaths; A), with Delta 21J and Omicron 21K exhibiting 3.4% and 12.2% higher transmissibility than baseline (). This differential contribution pattern reveals a previously overlooked mechanism: variant evolutionary success is shaped not solely by intrinsic biological properties but by dynamic interactions with population immunity landscapes []. The displacement of Omicron sublineages (21M, 22A, 23A) before achieving dominance, and the declining transmission potential of 22E/22F despite high initial prevalence (B, August-December 2022), suggests that viral evolution follows a “path of least immunological resistance”—variants must balance immune escape capacity with transmission efficiency in heterogeneous immunity contexts [,]. This pattern aligns with recent AI-driven variant prediction models using ensemble methods and deep learning fusion approaches for COVID-19 detection [,], yet our SHAP-interpreted framework advances beyond black-box predictions by quantifying temporal threshold dynamics and revealing variant-immunity co-evolution []. Mechanistically, the temporal lag in variant effects (strongest during January 2020-January 2021, B) likely reflects initial population immunological naivety, whereas subsequent attenuation corresponds to accumulating hybrid immunity from infection and vaccination.
Conversely, natural infection contributions escalate with severity (12.82% for Rt to 36.00% for deaths, 95% CI 10.25%-78.56%; A), exhibiting dual roles: protective against transmission via lagged immunity (A) but amplifying severe burdens during early outbreaks (B-D). This dichotomy arises from heterogeneous immune waning and reinfection vulnerabilities in populations with incomplete immunity coverage []. The ICU threshold at 10% cumulative infection rate (Figure S8C in ) suggests a critical tipping point where health care systems transition from manageable to crisis states, while mortality reduction beyond 50% infection rate (Figure S8D in ) implies population-level protective effects emerging only after widespread exposure—a pattern potentially reflecting trained innate immunity or T-cell cross-reactivity from endemic coronavirus exposures []. Health care infrastructure’s predominant role in hospitalization (23.98%, 95% CI 7.03%-73.13%; A and Figure S4 in ) underscores resource-dependent outcome modulation, where capacity acts as a buffer against admission surges rather than altering ultimate severity—a critical distinction for health care planning.
Vaccination demonstrates hierarchical protection with strikingly different thresholds: 29.9% coverage (95% CI 29.8%-29.9%) suppresses Rt/hospitalization/mortality, while 72.3% (95% CI 72.2%-72.8%) is required for ICU prevention (E-H). This tiered architecture reveals a previously unrecognized immunological insight: vaccine-induced immunity operates through distinct mechanistic pathways across disease severity gradients. Lower coverage likely achieves transmission reduction via humoral antibody responses providing transient infection blockade, whereas higher coverage is necessary for severe disease prevention through durable cellular immunity (T-cell mediated pathology mitigation) [,,]. This hypothesis is supported by the 1-3 month temporal lag before protective effects emerge across severity metrics (B), corresponding to T-cell response maturation timescales []. Compared with prior AI-driven vaccination modeling using SHAP-interpreted ensemble methods, our framework uniquely identifies dual coverage thresholds with temporal resolution, advancing beyond aggregate vaccination effects to reveal severity-specific immunity requirements []. Most intriguingly, routine immunizations exhibit dose-specific cross-protection: YFV >600,000 doses reduces Rt (I) and >100,000 doses protect against ICU (K), while BCG >450,000 doses reduces hospitalizations (J). These dose-response patterns suggest population-level trained immunity effects—where diverse pathogen exposures prime innate immune memory (eg, epigenetic reprogramming of monocytes/macrophages), conferring nonspecific protection against SARS-CoV-2 [,]. However, this cross-protection hypothesis requires mechanistic validation through immunological assays (eg, cytokine profiling and immune cell phenotyping), as our observational design cannot exclude confounding by health care access or socioeconomic factors correlated with routine immunization coverage [,].
Environmental factors demonstrate nonlinear threshold effects: temperatures below 14.95°C (95% CI 14.86°C-15.43°C) increase hospitalizations, and below 11.89°C (95% CI 11.81°C-11.97°C) increase ICU admissions (P<.05; ), while humidity shows U-shaped relationships (optimal 8-16 g m–3; Figure S12A in ). These thresholds likely define “vulnerability windows” where low temperatures enhance viral aerosol stability and suppress mucosal immunity (reduced interferon responses), compounded by indoor crowding behaviors [,]. Yet environmental contributions remain modest (<5% overall, A), suggesting they modulate disease timing rather than ultimate severity [,].
Several important limitations temper the interpretation of these findings. First, the ecological observational design identifies associations rather than causal relationships. Vaccination thresholds, environmental effects, and cross-protection from routine immunizations represent correlative patterns that may be confounded by unmeasured factors and require experimental validation through mechanistic immunological studies (eg, controlled vaccine trials, in vitro immune profiling) before inferring causation. Second, data biases compromise generalizability: sample selection of 38 high-burden countries, while representing >60% both of the global population and COVID-19 burden, systematically favors nations with robust surveillance infrastructure, potentially limiting applicability to low-resource settings with different reporting capacities; post-2022 reporting heterogeneity (discontinuation of systematic surveillance in many nations) creates missing data bias; and variant sequencing coverage variations across countries mean proportions may not fully represent circulating strains in undersequenced regions. Third, time-dependent confounding and nonstationarity in pandemic data pose threats to validity—reporting practices, testing intensity, and clinical definitions evolved over the study period, potentially introducing spurious temporal trends. While our partial autocorrelation function–based lag optimization mitigates some temporal biases, residual immortal time bias may persist in time-series analyses tracking outcomes over extended periods [], and we cannot fully exclude confounding from unconsidered time-varying factors (eg, behavioral changes and antiviral treatment availability). Fourth, factor interactions were not explicitly modeled; the XGBoost framework captures some nonlinear interactions, but synergistic or antagonistic effects between variants, immunity, and environmental factors remain incompletely characterized. Fifth, identified thresholds (vaccination coverage and temperature) likely vary across geographic/demographic contexts due to differences in population behavior, health care infrastructure, and climatic conditions, limiting global applicability without region-specific validation. Finally, the study lacks external replication with independent datasets from different countries or time periods post 2022, essential for confirming reproducibility and establishing reliability before the framework can be considered a generalizable template for pandemic response.
Priority next steps include (1) external validation using post 2022 independent datasets to test threshold stability and replication in low-resource settings, (2) mechanistic validation of trained immunity through randomized trials and immunological assays measuring innate immune markers, (3) integration of additional predictors (host genetics, viral genomic features, and social determinants), (4) methodological refinements addressing temporal biases (time-varying models and landmark analysis), and (5) operationalization into real-time decision support tools translating thresholds into automated public health alerts.
Conclusions
This study demonstrates how interpretable machine learning applied to large-scale, multidimensional pandemic surveillance data can systematically decompose complex burden determinants into quantifiable contributions and actionable thresholds. Three underrecognized population-level patterns emerge: variant evolutionary trajectories constrained by shifting immunity landscapes rather than intrinsic fitness accumulation, hierarchical immunity architecture requiring differential coverage targets across the severity spectrum, and potential trained immunity from routine immunization programs contributing to pandemic resilience. At the same time, the observational design limits causal inference; the integration of viral genomic surveillance, immunization records, environmental monitoring, and clinical outcomes within a unified analytical framework generates mechanistic hypotheses prioritizing experimental validation. This approach offers a methodological template for rapid multifactorial analysis in future epidemics, provided findings undergo pathogen-specific adaptation and independent replication to establish reproducibility and guide evidence-based preparedness strategies.
The authors extend their deepest gratitude to the numerous staff members of the Centers for Disease Control and Prevention, the devoted health care workers, and the diligent data scientists. These individuals tirelessly gather and generously disseminate data, demonstrating their unwavering dedication to controlling the proliferation of COVID-19. Their invaluable contributions have not gone unnoticed, and we appreciate their tireless efforts profoundly.
The data that support the findings of this study are available from the corresponding author upon reasonable request.
This work was supported by the Major Program of Guangzhou National Laboratory (grant number GZNL2024A01015 and GZNL2024A01002), the Key-Area Research and Development Program of Guangdong Province (2022B1111020006), the National Key Research and Development Program (2022YFC2303800), the Shenzhen Science and Technology Program (grand number ZDSYS20230626091203007), the Medical Scientific Research Foundation of Guangdong Province (B2023083), and the STU Scientific Research Initiation Grants NTF22021.
XD and ZC designed the study. ZC, WH, XZ, YC, HL, and JC collected and analyzed the data. ZC, WH, XZ, CZ, and JZ interpreted the data. XD and ZC prepared the manuscript. XD and ZC edited the paper. All authors reviewed and approved the submitted manuscript.
None declared.
Edited by S Brini; submitted 26.Jun.2025; peer-reviewed by OA El Meligy, SW Lee; comments to author 14.Oct.2025; accepted 12.Nov.2025; published 29.Dec.2025.
©Zicheng Cao, Wenjie Han, Xue Zhang, Chi Zhang, Jinfeng Zeng, Yilin Chen, Haoyu Long, Jian Chen, Xiangjun Du. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 29.Dec.2025.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work, first published in the Journal of Medical Internet Research (ISSN 1438-8871), is properly cited. The complete bibliographic information, a link to the original publication on https://www.jmir.org/, as well as this copyright and license information must be included.