![]()
Summary
Google has released new preview versions of its lightweight Gemini 2.5 Flash and Flash Lite models. Both are still in the experimental phase but now offer faster response times, handle multimedia more efficiently, and can tackle more complex tasks.
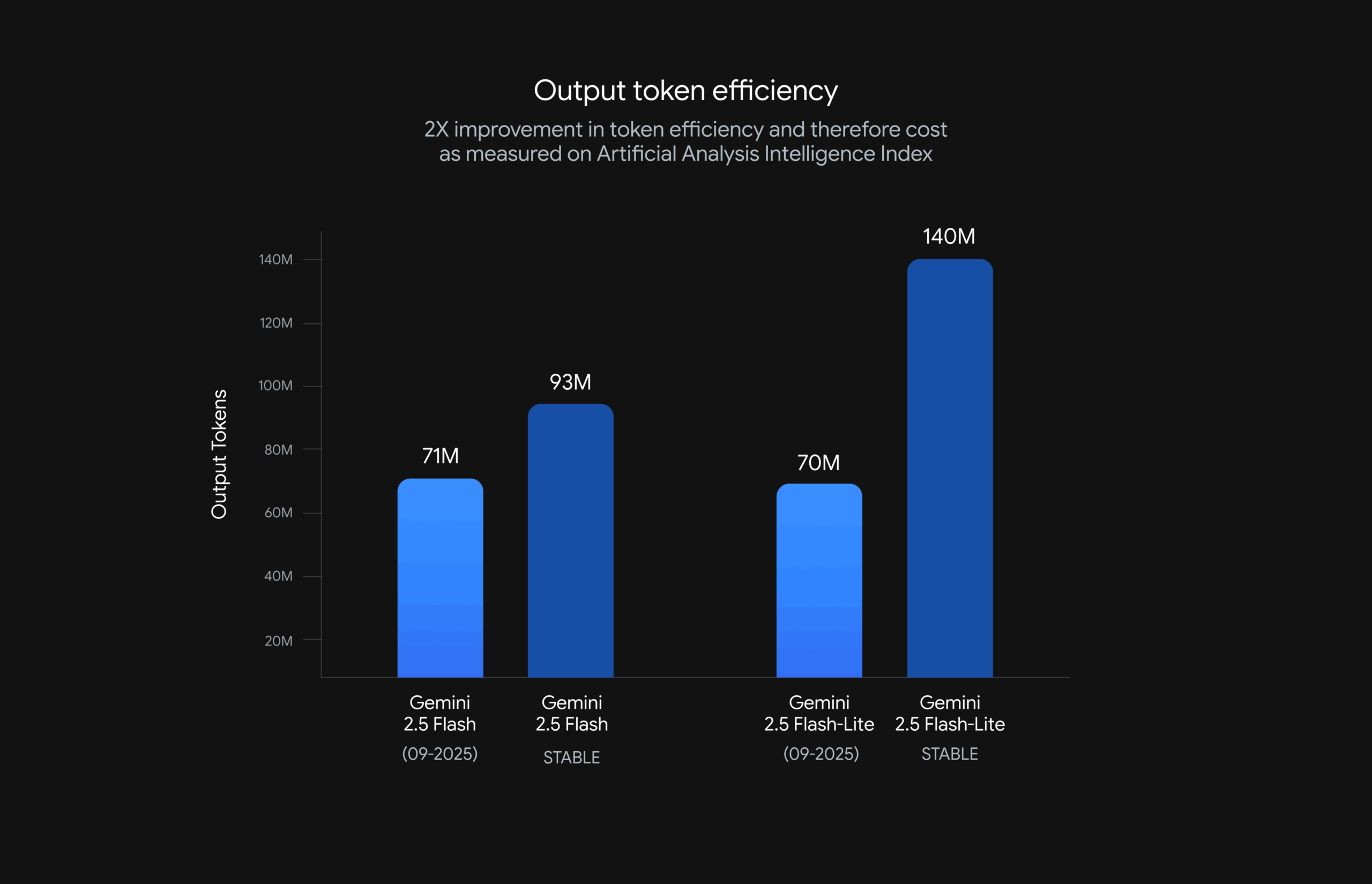
According to the Artificial Analysis Index, the updated models deliver better benchmark performance with higher response speeds, thanks to lower token usage. Pricing remains the same, but reduced token consumption means deploying the models is now less expensive.
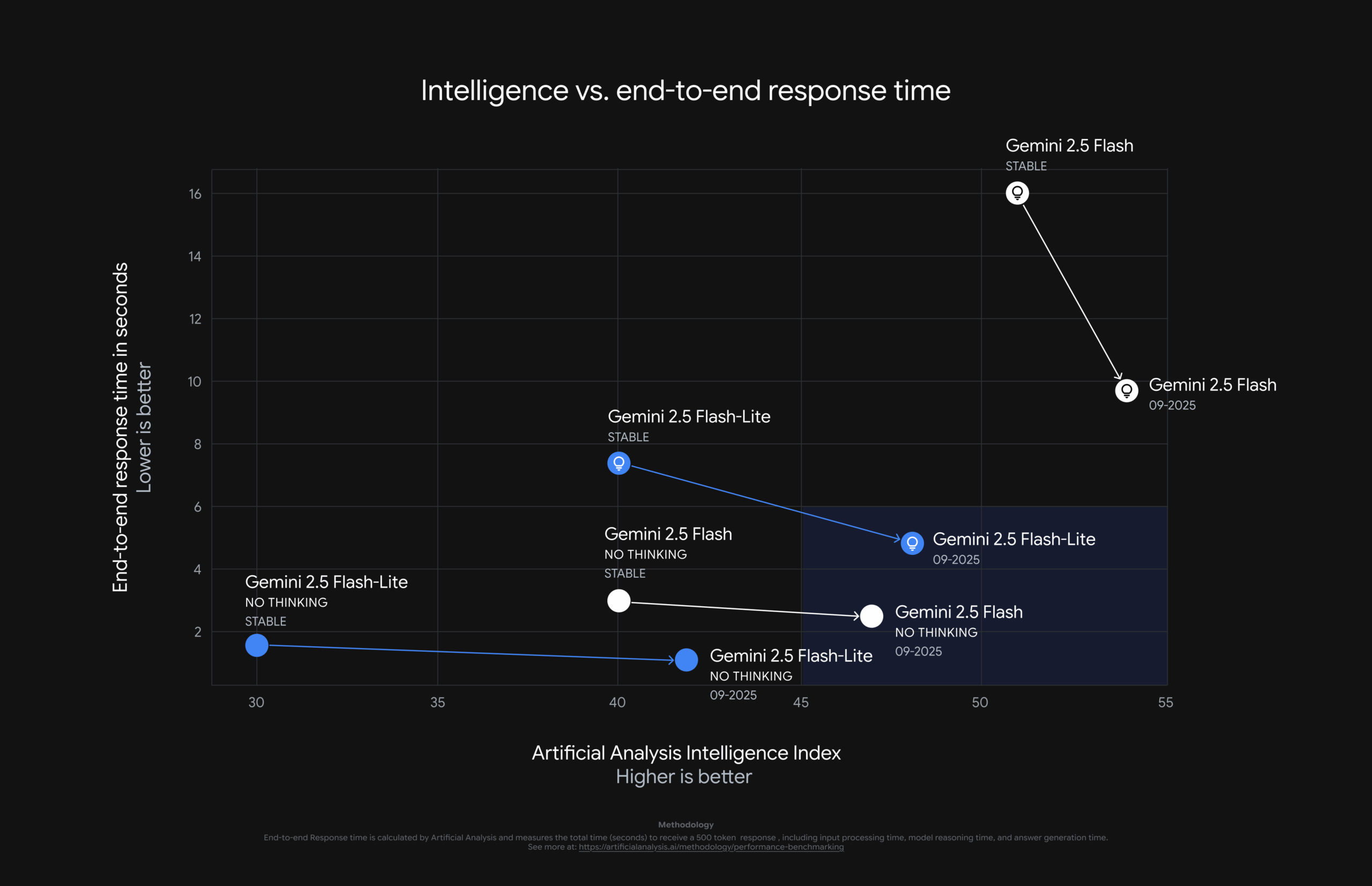
According to Google, the latest Gemini 2.5 Flash Lite is better at following complex instructions and system prompts. It now produces shorter, more accurate answers, which helps lower token costs and reduce latency. Google also claims improvements in multimodal tasks, including audio transcription, image analysis, and translation quality.
For the larger Gemini 2.5 Flash model, Google says it has been updated to use external tools more effectively in complex, multi-step tasks. The company reports an increase on the SWE-Bench Verified Benchmark, from 48.9 to 54 percent. This benchmark measures how well AI models can solve real-world software development problems.
Ad
Efficiency has improved for both models: with the “Thinking” feature enabled, the model delivers higher quality output while using fewer tokens, which speeds up responses and lowers costs.
How to use Gemini 2.5 Flash and Flash Lite
The new models are now available in Google AI Studio and Vertex AI. To try them, use the model ID gemini-2.5-flash-lite-preview-09-2025 for Flash Lite or gemini-2.5-flash-preview-09-2025 for Flash.
Google is also rolling out an alias system for easier access to the latest versions. The aliases gemini-flash-latest and gemini-flash-lite-latest always point to the newest models, so you don’t have to update model names manually each time.
However, Google notes that pricing, features, and rate limits for these aliases may change as new versions are released. If you need stable conditions, stick with the fixed model names: gemini-2.5-flash and gemini-2.5-flash-lite. Google will announce any changes to the “-latest” aliases at least two weeks in advance.
| Model | Input tokens (text/image/video) | Input tokens (audio) | Output tokens (including “thinking tokens”) |
|---|---|---|---|
| Gemini 2.5 Flash | $0.30 per 1 million | $1.00 per 1 million | $2.50 per 1 million |
| Gemini 2.5 Flash Lite | $0.10 per 1 million | $0.30 per 1 million | $0.40 per 1 million |
Batch API requests are billed at 50 percent of the standard interactive price. Full pricing details are available in the official Gemini API price list.
Recommendation
