The increasing demand for on-device artificial intelligence drives the development of edge accelerators, and understanding their performance limits is crucial for efficient deployment of deep neural networks. Prashanthi S. K., Kunal Kumar Sahoo, and Amartya Ranjan Saikia, along with their colleagues, investigate the energy and time characteristics of these accelerators, specifically the Jetson Orin AGX, across a range of power settings. Their work establishes novel analytical models, termed ‘rooflines’, that reveal fundamental relationships between computation, memory access, and power consumption for both inference and training tasks. This research demonstrates that commonly used default power modes are not always the most energy efficient and, importantly, provides a method for tuning device settings to significantly reduce energy consumption with minimal impact on performance, offering a pathway to more sustainable and powerful edge computing.
Edge Inference, Roofline Analysis and Federated Learning
This research details investigations into the performance and energy efficiency of deep learning models during inference on edge devices like the NVIDIA Jetson AGX Orin. The overarching goal is to identify performance bottlenecks and develop methods to optimize performance and reduce power consumption. A central component of this work involves utilizing and extending the Roofline Model to analyze and predict performance characteristics, extending beyond simple metrics to include considerations for federated learning, fault tolerance, and model architectures. The Roofline Model serves as the primary analytical tool, visualizing performance limits based on computational throughput and memory bandwidth.
Researchers explored extensions to the basic roofline model, including a time-based roofline focusing on execution time, a cache-aware roofline considering cache hierarchies, and an energy roofline incorporating energy consumption. Arithmetic intensity, the ratio of floating-point operations to memory accesses, is a crucial metric, with models exhibiting varying characteristics impacting performance on different hardware platforms. The research investigates how these performance considerations apply to federated learning scenarios and techniques to maintain performance even with hardware failures. Memory bandwidth frequently limits deep learning inference, especially for models with low arithmetic intensity, a challenge pronounced on edge devices with limited memory resources.
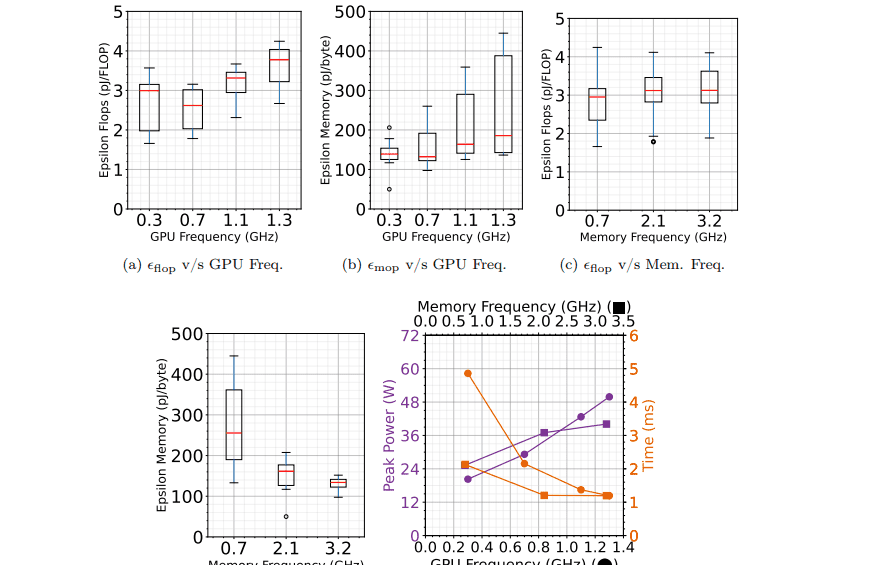
Optimization techniques like quantization, pruning, kernel fusion, and utilizing Tensor Cores can improve performance and reduce memory footprint, while dynamic voltage scaling can reduce power consumption. The work covers a range of models and datasets, including image classification with ResNet and MobileNet, object detection with YOLOv8, and natural language processing with LSTMs and BERT, utilizing datasets like WikiText and SQuAD. Federated learning experiments utilized the GLDV2V dataset, leveraging NVIDIA CUDA, Nsight Compute, and the Empirical Roofline Tool, alongside TensorFlow, PyTorch, and Hugging Face Datasets. Future research directions include developing more sophisticated roofline models, automating performance tuning, prioritizing energy-aware optimization, developing fault-tolerant inference techniques, and applying roofline analysis to federated learning, with a key focus on large language model inference on edge accelerators. Recognizing the limitations of existing data-driven approaches, the research team focused on understanding the fundamental reasons behind performance variations across numerous power modes, pioneering the creation of both a time roofline and a new energy roofline model for the Jetson Orin AGX. These roofline models were coupled with an analytical model quantifying compute operations and memory access for DNN inference workloads, enabling the team to dissect performance characteristics from first principles and reveal insights into how different power modes impact speed and energy consumption. Researchers meticulously analyzed how varying CPU, GPU, and memory frequencies affect the execution of DNN layers, considering both forward and backward passes during training and inference, extending the analysis to DNN training workloads. The team applied these models to tune the power mode of the edge device, optimizing for both latency and energy usage during DNN inference, achieving up to a 15% reduction in energy consumption with minimal degradation in inference time. The research centers on the creation of both time and energy roofline models, providing a detailed understanding of the device’s computational limits and energy consumption characteristics across a wide range of operating conditions. Experiments reveal that the default MAXN power mode, while delivering peak performance, is not necessarily the most energy efficient. The team collected roofline data from 96 diverse power modes, varying GPU, CPU, and memory frequencies, to map performance and energy efficiency, demonstrating that careful tuning of the power mode can deliver lower energy consumption while maintaining minimal degradation in inference time. The research extends beyond inference, also analyzing six DNN training workloads using the same roofline methodology. The team’s analytical models accurately predict the performance of neural networks, offering insights into how to optimize the device’s configuration for specific tasks, demonstrating the potential to shift the device’s performance limits by adjusting power modes rather than modifying the neural network itself.