Multimodal training data of paired transcriptomes and text
To establish a large training dataset of transcriptomes and their matched textual annotations, we processed two community-scale repositories: GEO10,11 and CELLxGENE Census (version…
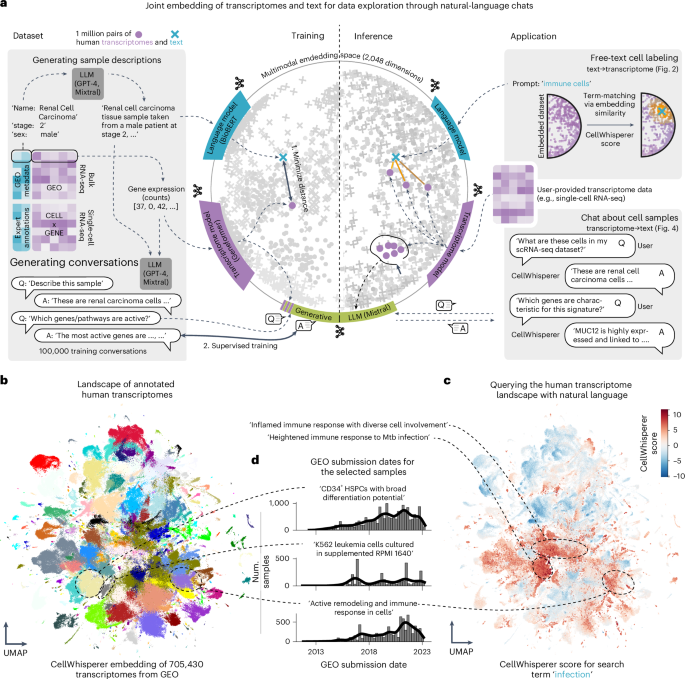
To establish a large training dataset of transcriptomes and their matched textual annotations, we processed two community-scale repositories: GEO10,11 and CELLxGENE Census (version…