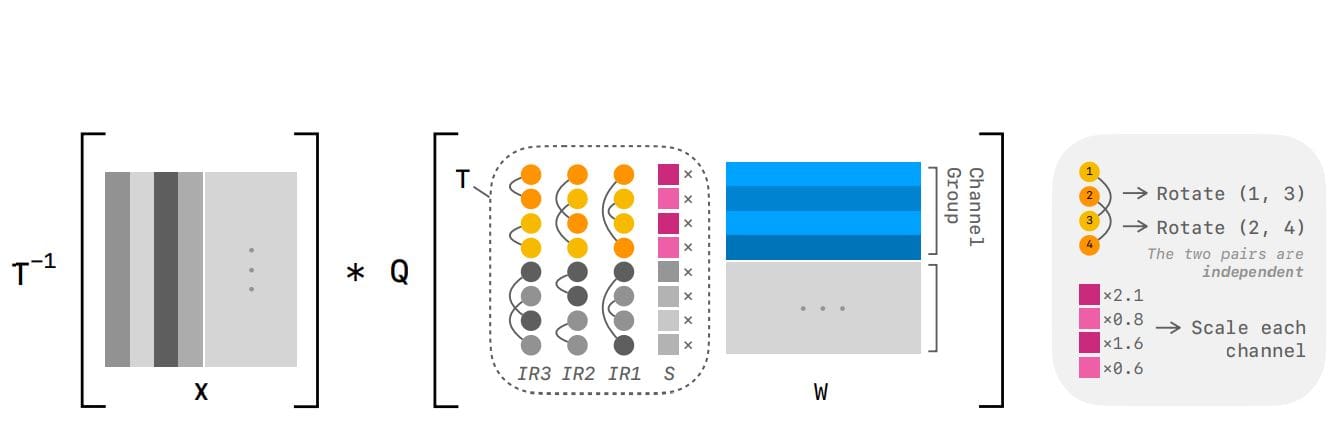
Large language models demonstrate remarkable abilities, but their size often limits practical deployment, prompting researchers to explore methods for efficient compression. Yesheng Liang and Haisheng Chen from UC San Diego, alongside Song Han…
Pairwise Rotation Quantization Achieves Efficient LLM Inference With 2.4% Accuracy Loss And 10% Speedup