A study led by researchers from South China University of Technology published a research paper in the special issue “Latest Advances in Artificial Intelligence Generated Content” of Frontiers of Information Technology & Electronic Engineering 2024, Vol. 25, No. 1. They proposed an innovative music generation algorithm capable of creating a complete musical composition from scratch based on a specified target style.
Rule-based music generation models rely on theoretical knowledge, making it difficult to capture deep structures and limiting the diversity of outputs. Among deep learning-based music generation models, generative adversarial networks (GANs), variational auto-encoders (VAEs), and Transformers each have their advantages but face issues such as high training difficulty, insufficient handling of long sequences, or lack of style control. Although style-based music generation research has introduced style information, it has not considered the model’s structural awareness. This paper combines structural awareness with interpretive ability, conducting research and verifying the effectiveness of the method in emotion and composer style generation.
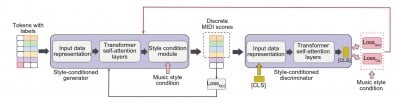
A music generation model under style control, namely style-conditioned Transformer-GANs (SCTG), is proposed. The importance of data representation, style-conditioned linear Transformer, and style-conditioned patch discriminator in the style music generation model is discussed. Data representation includes the representation of MIDI event sequences with inserted style information and grouped musical information. The style-conditioned linear Transformer addresses the limitations in music style-conditioned generation by embedding style information, which is directly embedded into the hidden space of the model and combined with output features to influence the output of the entire sequence. The conversion of generated music into discrete scores enhances the learning effect of the discriminator and promotes the expression of style information in the generated music.
Experiments were conducted using the emotion-style dataset EMOPIA and the composer-style dataset Pianst8, comparing with two state-of-the-art models. Objective evaluations showed that the proposed model achieved the best results in traditional metrics as well as style distance (SD) and classification accuracy (CA), with outstanding style consistency of generated music and similarity to the original data. In subjective evaluations, participants gave the highest scores to the music generated by this model in terms of humanness, richness, and overall quality, indicating its potential for practical use.
Based on CP-Transformer, style conditions are innovatively embedded and a style-conditioned patch discriminator is implemented. Comparisons between the style-conditioned generator and the style-conditioned patch discriminator showed that the music style information in the model helps the generator discriminate music styles and enables it to generate music of specific styles. Additionally, the model performs poorly when either loss is removed; therefore, both Loss₍Cls₎ and Loss₍Gan₎ are important for the performance of the style-conditioned patch discriminator
The paper “Style-conditioned music generation with Transformer-GANs” authored by Weining WANG, Jiahui LI, Yifan LI and Xiaofen XING. Full text of the open access paper: https://doi.org/10.1631/FITEE.2300359.