
Category: 3. Business
-

Stock market today: Live updates
Traders work on the floor at the New York Stock Exchange (NYSE) in New York City, U.S., Jan. 28, 2026.
Brendan Mcdermid | Reuters
Stock futures fell on Sunday night as Wall Street begins a new month of trading, with traders keeping an eye on bitcoin after a weekend sell-off.
Dow Jones Industrial Average futures lost 143 points, or 0.3%. S&P 500 futures dipped 0.6%, while Nasdaq-100 futures shed nearly 1%.
Bitcoin dropped below $80,000 for the first time since April, a sign investors were taking more risk off the table following Friday’s sharp declines in gold and silver. Silver, which has more than doubled over the past 12 months, plunged around 30% on Friday. That marked the metal’s worst one-day performance since 1980. Gold also dropped around 9%.
Bitcoin last traded near $76,000.
Wall Street also turned its attention to Nvidia as questions over the artificial intelligence loomed.
The Wall Street Journal reported, citing people familiar with the matter, that Nvidia’s plans to pour $100 billion into OpenAI had stalled, with chipmaker execs expressing doubt about the deal.
Big earnings, jobs week
More than 100 S&P 500 companies are due to report this week, including Amazon, Alphabet and Disney. The overall reporting season has been strong thus far, but there have been some high-profile post-earnings sell-offs, including Microsoft.
Nonetheless, Deutsche Bank strategists noted this weekend that earnings growth is on track to be the strongest in four years.
Wall Street is also awaiting the release of the January U.S. jobs report, due Friday morning. Economists polled by Dow Jones expect 55,000 jobs were added last month.
Stocks are coming off a losing session, with the major benchmarks falling after President Donald Trump named Kevin Warsh as his nominee for Federal Reserve chairman. If confirmed, Warsh would replace Jerome Powell later this year.
Continue Reading
-

Saks Ends E-commerce Partnership With Amazon
Bankrupt retailer Saks Global is ending its “Saks on Amazon” partnership with e-commerce giant Amazon.com, a source with direct knowledge of the decision said on Friday.
The partnership was already in dire straits when Saks filed for bankruptcy in February, but the retailer had yet to say outright that it was exercising its right under Chapter 11 bankruptcy to reject the contract.
On Friday, a source said Saks will wind down its Saks on Amazon storefront so it can focus on parts of its business it sees as spurring more growth.
“The Saks on Amazon storefront saw limited brand participation,” the person said, adding that Saks feels it would be better served driving traffic to Saks.com.
Amazon did not immediately respond to a request for comment.
The partnership arose from Amazon’s $475 million investment in Saks’ business in 2024. The companies agreed to an arrangement in which Saks would sell products on Amazon, paying the e-commerce giant at least $900 million over eight years.
But comments by Amazon’s lawyer at a court hearing after Saks filed bankruptcy indicated their relationship had soured, and court battles may lie ahead.
At the hearing, the Amazon lawyer argued that Saks improperly pledged its flagship Fifth Avenue store in Manhattan as collateral for a $1.75 billion loan that is allowing it to operate while in bankruptcy. The lawyer said that property had already been collateralised to guarantee Saks’ payments to Amazon under their partnership.
The partnership was also facing pushback from Saks’ top luxury brands, who feared selling on a mass-market e-commerce site would dilute their brand, according to two sources familiar with these brands’ thinking.
It was likely the brands would use bankruptcy negotiations to push back on the deal, the people said.
By Nicholas P. Brown with additional reporting by Dietrich Knauth; Editor: Lisa Shumake
Learn more:
In the Fight for Early Payouts From Bankrupt Saks, Big Luxury Brands Have the Edge
The embattled luxury department store is ‘absolutely dependent’ on companies like Chanel, LVMH and Kering, who could ‘suffocate’ the retailer if they stopped shipping, Reuters reported.
Continue Reading
-

Do Calix’s (CALX) Record Margins and Bigger Buybacks Hint at a New Strategic Phase?
-
In late January 2026, Calix reported Q4 2025 revenue of US$272.45 million and a swing to quarterly and full-year profitability, while also expanding its share repurchase authorization to US$425 million after buying back 5.06 million shares since 2022.
-
At the same time, Calix highlighted record non-GAAP gross margins, rapid adoption of its third-generation cloud platform with more than 300 customer migrations, and growing use cases like Zentro’s SmartMDU deployments in dense multifamily housing.
-
Against this backdrop of earnings strength and expanded buybacks, we’ll explore how the third-generation platform launch shapes Calix’s investment narrative.
We’ve found 12 US stocks that are forecast to pay a dividend yield of over 6% next year. See the full list for free.
To own Calix today, you have to believe in its broadband cloud platform story more than the recent share price slide. The Q4 2025 print and full-year swing to profitability, alongside record non-GAAP gross margins and US$1,000.01 million in revenue, reinforce that the third-generation platform and AI investments are becoming a larger part of the business. The expanded US$425 million buyback hints at management’s confidence, but the near 18% pullback since earnings suggests the market is focused on short term margin pressure from dual cloud costs and customer mix. Key catalysts now cluster around successful customer migrations, monetization of services like SmartMDU, and how efficiently Calix manages overlapping cloud expenses. The biggest risk is that execution hiccups on this transition keep margins and returns below what current valuation already assumes.
However, investors should not ignore how sensitive the story has become to cloud transition costs. Despite retreating, Calix’s shares might still be trading above their fair value and there could be some more downside. Discover how much.
CALX 1-Year Stock Price Chart Five Simply Wall St Community fair values for Calix span roughly US$43 to just over US$109, underlining how differently private investors assess upside after the platform-driven earnings swing and growing cloud cost risks. This spread can help you weigh the recent earnings strength against the possibility that margin pressure or execution missteps on the third generation platform shift sentiment again, with clear implications for how the market prices Calix’s transition.
Explore 5 other fair value estimates on Calix – why the stock might be worth over 2x more than the current price!
Disagree with this assessment? Create your own narrative in under 3 minutes – extraordinary investment returns rarely come from following the herd.
Continue Reading
-
-
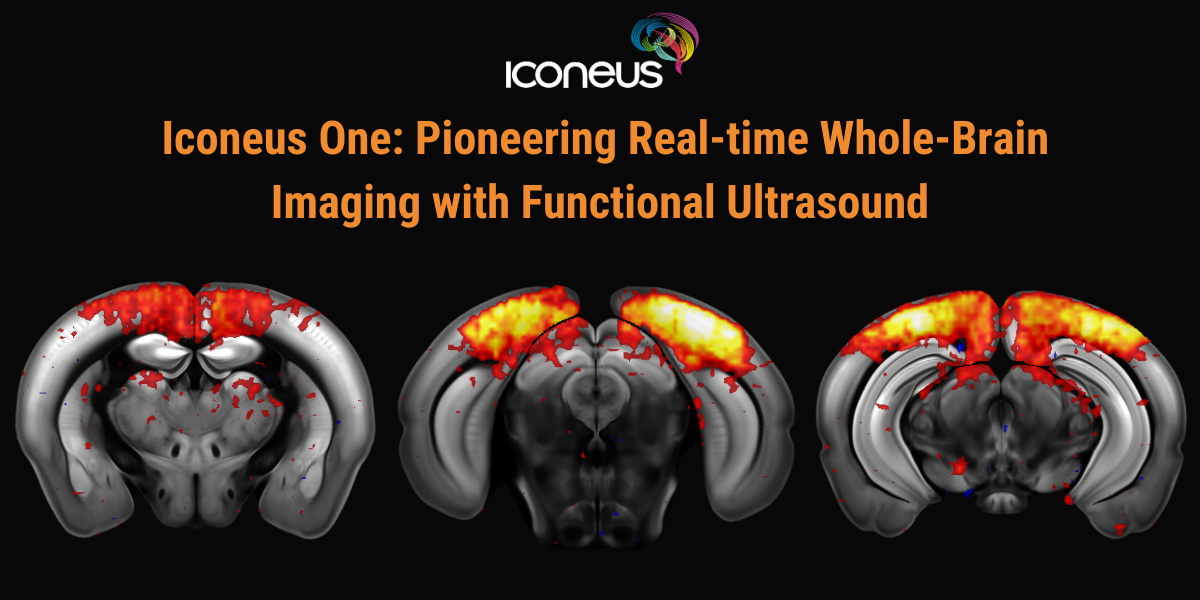
Pioneering Real-time Whole-Brain Imaging with Functional Ultrasound
Date: February 19, 2026
Time: 7:00 AM PT, 10:00 AM ET, 4:00 PM CET
Discover how Iconeus One, the premier functional ultrasound (fUS) system for neuroscientists, is transforming brain function studies. Based on ultrafast plane-wave sonography, Iconeus One offers exceptional spatial (100 x 100 x 400 µm) and temporal (10 ms) resolution, enabling precise, real-time mapping of hemodynamic changes even in conscious subjects.
This session will highlight the diverse applications of Iconeus One in Neuroscience, including task-induced activation mapping, resting-state functional connectivity, and in vivo dynamic angiography. We’ll showcase how this cutting-edge technology contributes to our understanding of brain function and discuss its future potential with advancements like 3D solutions for whole-brain imaging and connectivity mapping in mice.
Additionally, we will cover Ultrasound Localization Microscopy (ULM), a derivative technique enabled by Iconeus One, offering super-resolution vascular imaging at the micrometer scale. ULM’s ability to visualize functional hyperemia at 6.5 µm will be demonstrated, underscoring its revolutionary impact on brain research.
Join us to learn about the transformative capabilities of Iconeus One and its role in advancing neuroimaging and Neuroscience research.
Learning Objectives:
-
Understand the principles and advantages of functional ultrasound (fUS) imaging
-
Identify the key neuroscience applications of fUS
-
Explore how advanced fUS platforms like Iconeus One enable cutting-edge research
Continue Reading
-
-

Down Arrow Button Icon
The flood of Chinese exports around the world helped the economy blow past President Donald Trump’s massive tariff hikes, while Beijing touts successes in AI, EVs, robotics and other emerging technologies.
But that strength masks ongoing weakness among consumers and the property sector.
China’s trade surplus jumped 20% to $1.19 trillion in 2025, marking the world’s largest ever, as shipments surged to the European Union, Africa, Latin America and Southeast Asia.
Exports climbed 5.5% and accounted for a third of economic growth in 2025, the highest level since 1997. Imports were virtually flat, reflecting weak domestic demand and Beijing’s push to become more self-sufficient.
The record trade surplus helped GDP grow 5% last year, matching the government’s target, but the headline figure contrasted with mounting signs of broad weakness.
Growth actually slowed toward the end of the year, with GDP up 4.5% in the fourth quarter on an annual basis versus a 4.8% gain in the third quarter.
Retail sales in December inched up just 0.9%, down from 2.9% growth in October and 6.4% in May. Investment in fixed assets reversed sharply into an outright decline, collapsing 15% in December after spiking 15.7% in February.
In fact, fixed-asset investment saw its first annual drop in data going back almost three decades. That’s largely due to China’s real estate crash, which sent property investment down 17.2% last year and offset heavy spending on high-tech industries that Beijing is trying to advance.
Fitch Ratings expects China’s economy to run out of steam this year, predicting GDP growth will cool sharply to 4.1% from 5% in 2025.
“We believe domestic demand will remain constrained by sluggish consumer confidence, deflationary pressures, and investment headwinds that have broadened beyond the property-sector correction and are amplified by the local-government debt overhang,” it said in a report on Jan. 22.
But more than four years since China popped a construction bubble, about 80 million unsold or vacant homes continue to weigh on sales, prices, starts and completions.
After tinkering with attempts to revive the property sector, China has signaled it’s pivoting to a new model of development, away from the emphasis on debt-fueled investment.
“This marks the virtual abandonment of an industry that once accounted for about one-quarter of China’s gross domestic product and roughly 15% of the nonfarm workforce,” Jeremy Mark, an Atlantic Council scholar and former IMF official, wrote on Wednesday.
Many other economic problems—such as weak retail spending, deflation, as well as low consumer and business confidence—can be traced back to the free-fall in real estate, which is the main repository of life savings for hundreds of millions of households, he pointed out.
That’s as an estimated 85% of the price gains in real estate have been wiped out since 2021. As result, consumers hoard their money instead of spending it, forcing businesses to trim wages, staff and prices to remain afloat. In response, consumers pull back further.
This feedback loop has kept consumer prices flat and producer prices in negative territory. China’s overcapacity and its support for manufacturers over consumers have also stoked excess supply that drags down prices. An economy-wide price gauge shows China has been suffering from deflation for three straight years, the longest such streak since its transition to a market economy in the late 1970s.
The real estate crash is also rippling through China’s banks and local governments, as efforts to stave off more bankruptcies among developers have created “zombie” firms and mountains of debt, Mark warned.
“Even if the shockwaves from China’s collapsed property bubble eventually recede, the task of rebuilding will be daunting,” he added. “It requires not only replacing a major pillar of Chinese economic dynamism, but also the revitalization of homeowners’ deeply damaged sense of financial security.”
Export-led growth running out of room
Economists have long urged China to rebalance its growth to a consumer-led model and away from an export- and investment-led model. President Xi Jinping’s industrial policies have even been flagged as a greater threat to the global economy than Trump’s trade war.
But last year’s reliance on exports showed that the country’s leadership remains reluctant to make the switch. While Chinese businesses have flexed their muscle as global manufacturing powerhouses, their ability to prop up the rest of the economy is in doubt.
“China’s growth model is becoming increasingly difficult to sustain,” Cornell professor Eswar Prasad wrote in a Financial Times op-ed in December.
Weak growth in employment and wages, plus the property crash and lack of confidence in the government, have weighed on consumption, he added. With little domestic demand, the only option for China’s factories is to export their output.
But Trump’s tariffs have forced exporters to look elsewhere, creating a backlash in other markets that could put up additional trade barriers and limit future growth, Prasad said.
The EU and some other large economies like Indonesia and India have already imposed some targeted tariffs on certain Chinese goods.
“As the second-largest economy in the world, China is simply too big to generate much growth from exports, and continuing to depend on export-led growth risks furthering global trade tensions,” IMF Managing Director Kristalina Georgieva warned in December.
Continue Reading
-

Freedom Capital Markets Upgrades Netflix, Inc. (NFLX) To Buy
Netflix, Inc. (NASDAQ:NFLX) is among the 12 Most Profitable NASDAQ Stocks to Buy Right Now. On January 27, Freedom Capital Markets upgraded the stock to Buy from Hold, with a price target of $104.
Freedom Capital Markets Upgrades Netflix, Inc. (NFLX) To Buy The adjustment followed the company’s fourth-quarter results, which beat Wall Street’s estimates for both revenue and earnings, driven mainly by an 8% increase in membership to 325 million subscribers from late 2024. Another highlight of the quarter was the streaming giant’s advertising revenue, which grew more than 2.5x to over $1.5 billion.
Based on the recommendations of 40 analysts, the stock is a Moderate Buy with a one-year average share price target of $114.79, representing an upside of 37.49% as of the close on January 30.
In other news, on January 20, Netflix, Inc. (NASDAQ:NFLX) announced that it had revised the agreement with Warner Bros. Discovery (WBD) for the latter’s pending acquisition to an all-cash transaction, as part of efforts to close the doors on Paramount’s rival offer. The takeover price would remain $27.75 per WBD share.
Netflix, Inc. (NASDAQ:NFLX) is a global entertainment company offering TV series, documentaries, movies, and games across multiple languages and genres.
While we acknowledge the potential of NFLX as an investment, we believe certain AI stocks offer greater upside potential and carry less downside risk. If you’re looking for an extremely undervalued AI stock that also stands to benefit significantly from Trump-era tariffs and the onshoring trend, see our free report on the best short-term AI stock.
READ NEXT: 10 Best Defense Stocks to Buy in the S&P 500 and 14 Best Booming Stocks to Buy Right Now.
Disclosure: None.
Continue Reading
-

With attention on orbital data centers, the focus turns to economics
One of the biggest questions in the tech sector has been if AI is the future, where does all the infrastructure go?
Some space industry leaders — including Elon Musk and Jeff Bezos — believe the answer could be in orbit, via space-based data centers.
That idea has gained attention in recent weeks. Musk is reportedly considering a merger between SpaceX and his generative artificial AI company xAI ahead of his space firm’s planned IPO later this year. In addition, in a filing with the FCC late Jan. 30, SpaceX proposed an orbital data center constellation of up to 1 million satellites in low Earth orbit.
But industry analysts say that while the technological challenges can be surmounted, it’s not yet clear if the business case for data centers in space holds up.
Deep learning models built by frontier labs like OpenAI, Anthropic and xAI all depend on massive clusters of advanced processors operating in data centers. As more deep learning models are built and deployed, more processing power is required — last year companies invested $61 billion in building more data centers. That’s a new record, according to S&P Global, with real estate trackers expecting capacity to double by 2030.
However, there are obstacles facing new data centers on Earth, including environmental permitting, access to electricity for power and water for cooling and community opposition. Microsoft, for example, expects its data center water usage to triple by 2030, according to the New York Times. Data center projects built by Amazon and Chile have been canceled over resource concerns like those.
“The biggest problems are cooling, security, power transmission — all those things can be solved if you just move it into space,” Chris Quilty, a space industry analyst, told SpaceNews. “The big question that has to be solved, can you do it economically?”
Jeff Bezos, long an advocate of moving polluting industries off-world as CEO of Blue Origin, kick-started this discussion with remarks at last year’s International Astronautical Congress.
“We’re going to start building these giant gigawatt data centers in space,” Bezos said. “We will be able to beat the cost of terrestrial data centers in space in the next couple of decades.”
Elon Musk and SpaceX are also onboard. Musk told audiences at the World Economic Forum that it will be cheaper to build data centers in space within three years — although that forecast depends on achieving full reusability for Starship, which Musk expects in 2026.
Meanwhile, start-ups like Starcloud are attempting to build companies around this business, while Google is collaborating with Earth observation firm Planet to launch its own data center pilot in 2027. Chinese companies like ADA Space and Beijing Astro-Future are plotting ambitious space compute architectures.
“The rapidity with which the trend has taken hold has shocked me, even for an old hand,” Quilty said. ”It’s very similar to what happened with direct-to-device — everyone and their brother agreed it was a dumb idea right up until the moment that AST raised a round on the concept.”
Still, much uncertainty remains. “Whether putting data centers in space makes sense or not, and what technologies are needed, depends on the business model,” Akhil Rao, a former NASA economist and managing partner at the frontier technology consultancy Rational Futures, told SpaceNews via email. ”I haven’t seen a business model articulated clearly enough to understand how the system architecture serves particular use cases well.”
Andrew McCalip, the head of research and development at Varda Space Industries, built an online calculator that attempts a comparison of terrestrial and orbital data centers using publicly available data. Right now, it doesn’t pencil out, with orbital data centers costing about three times as much per watt of computing power under his base case.
“If you run the numbers honestly, the physics doesn’t immediately kill it, but the economics are savage,” McCalip wrote in his analysis of the calculator. “It only gets within striking distance under aggressive assumptions, and the list of organizations positioned to even try that is basically one.”
That’s one reason why space data centers have taken a central role in SpaceX’s IPO narrative, which is reportedly planned for June 2026. Justifying a $1.5 trillion valuation is difficult based on the company’s current business lines and revenues, Quilty said, but the company has a record of surprising its doubters. When Starlink was proposed, few thought that phased array antennas could be manufactured at the required scale and cost, but now SpaceX is building them by the millions and selling them for a few hundred dollars a piece.
The latest announcement from Blue Origin may point at a middle ground for AI in space: On Jan. 21, the company announced TeraWave, a new satellite constellation that appears designed to provide new, high-bandwidth connections between terrestrial data centers. Compared to running models in orbit, offering connectivity is a proven way for space companies to dip into the AI surge.
And of course, there is the question of an AI bubble. Analysts have noted that justifying the investment in data centers will require significant increases in revenue — say $650 billion in annual consumer spending, per one JP Morgan analysis — for companies like OpenAI that currently lose tens of billions of dollars annually. AI boosters are confident that they will prove out the value of their software, but users, particularly at the enterprise level, are still figuring out how to generate returns using these tools. If they don’t meet expectations, demand for more processing power could prove elusive.
Related
Continue Reading
-

Price of consumer goods could surge as shipping costs soar, industry body says | Supply chain crisis
The price of consumer goods including computers, electrical machinery and transport equipment could surge this year as a result of soaring shipping costs, an industry body has said, adding that “cracks [are] forming in the global trading system”.
The cost of transport, energy and raw materials continues to rise and prices remain volatile, which could feed through to businesses and consumers during 2026, according to a study by the Chartered Institute of Procurement and Supply (CIPS).
Concerns about disruption to supply chains during the next three months reached the highest level in two years, suggesting growing worries among procurement teams. The concerns were reported in a survey conducted in late 2025 by CIPS, an international trade body that represents 64,000 member organisations in procurement and supply chains across 180 countries.
Bosses responsible for procurement said they were often the first within companies to notice rising prices or problems getting hold of goods. They said uncertainty and price volatility risked becoming a permanent feature of international trade rather than a temporary disruption, as the turmoil unleashed by the pandemic has been followed by geopolitical tensions around the world.
Shipping and logistics is the area most likely to see significant price rises in 2026, according to the procurement bosses surveyed, with 22% of respondents reporting cost increases of more than 10% by the end of 2025.
Nearly a fifth (18%) said they had seen similar price increases for computers and peripheral equipment, while 15% reported cost rises for transport equipment and 14% for electrical machinery and apparatus.
Chinese shipping containers at the Port of Los Angeles this month. The average spot shipping rate between Asia and the US west coast has soared. Photograph: Mike Blake/Reuters These price rises and continued volatility are fuelling expectations of more inflationary pressure for consumers during 2026. Shoppers had already seen increases for some computers late last year, with Lenovo and Dell reportedly hiking prices by about 15%. In December, the price of some Dell laptops rose between $130 (£95) and $765, depending on the model and memory size, Business Insider reported.
The average spot shipping rate between Asia and the US west coast jumped by nearly 30% between late December and early January. The rate increased to $2,145 for a 40ft (12-metre) equivalent unit (FEU), a standard shipping container, up from $2,757, according to the Freightos Baltic Index.
Prices on shipping routes between Asia and the US east coast and Europe have also climbed in recent weeks.
Ben Farrell, the chief executive of CIPS, said: “Procurement professionals are often the first to see cracks forming in the global trading system.”
He added: “Volatility is no longer an exception. When logistics costs can swing by 20%-30% in weeks, those pressures inevitably ripple through to businesses and consumers alike.”
A man passes a mural depicting Iranian soldiers near an anti-US and Israel billboard in Tehran on Thursday. Photograph: Abedin Taherkenareh/EPA International freight shipping costs were already on the rise and climbed further after increased tensions, stoked by Donald Trump’s recent threats to take over Greenland and impose further tariffs on European allies as well as the possibility of war between the US and Iran, sending investors fleeing to traditional safe haven assets such as gold and the Swiss franc.
US tariffs and protectionist policies were highlighted as important causes of price volatility by those surveyed, who said they were directly being affected by shifting trade rules and China-US tensions.
Continue Reading
-

French tech giant Capgemini to sell US subsidiary working for ICE – BBC
- French tech giant Capgemini to sell US subsidiary working for ICE BBC
- French MPs demand explanation over tech firm’s contract to help ICE in US The Guardian
- Capgemini to sell unit linked to US immigration tracking Financial Times
- French Firm to Sell Division That Helps ICE Track Immigrants The Wall Street Journal
- French IT giant Capgemini to sell subsidiary working with US immigration agency ICE Anadolu Ajansı
Continue Reading