The world has been inspired by generative AI models like ChatGPT. These are very applicable to things like copilots and agentic AI, but the adoption of these models into EDA tools is less obvious. What may be appropriate, and can AI make EDA tools faster or better?
EDA has been enabling Moore’s Law for the past 40 years, and that has required pushing the limits of many of the algorithms and techniques that have been developed (see figure 1). In some cases, algorithms may have existed, but insufficient computing power was available to make them practical. The same is true for AI-based solutions.
“This isn’t a new journey for EDA,” says Rob Knoth, group director for strategy and new ventures at Cadence. “This is what we’ve been working on for decades. With every single advancement in technology, engineers are hungrily embracing automation. They never would have been able to get home and have dinner with their family without this. The workload and complexity are increasing exponentially every generation.”
Fig. 1: Evolution of EDA and algorithms. Source: Cadence
The use of AI within EDA is not new. One of the early developers was Solido Solutions (now part of Siemens EDA), formed in 2005, long before generative AI made its debut. The company used machine learning techniques, and several other examples were based on reinforcement learning. “Early tools focusing on how we could do things like get better design coverage in fewer simulations compared to brute force techniques,” says Amit Gupta, vice president and general manager of Siemens EDA’s Custom IC Division. “These are things that make sense to have inside the tools.”
Many other tools followed. “Think about all the technologies we’ve unleashed over the last five years,” says Anand Thiruvengadam, senior director and head of AI product management at Synopsys. “This started with reinforcement learning based optimization technology.”
Each company made use of the techniques that made sense. “We have leveraged planning algorithms,” says Dave Kelf, CEO for Breker Verification Systems. “These are a broadly used agentic approach that adds intelligence into state space exploration for test generation over and above simple random decisions.”
But just over two years ago, there was a quantum leap in the perceived capabilities of AI, enabled by an explosion of compute capability. Generative AI became accessible, and more recently tools and platforms that enable agentic AI have been introduced (see figure 2). There is no immediate sign that the growth of compute power is going to slow down, even though there may be questions about the economics associated with it.
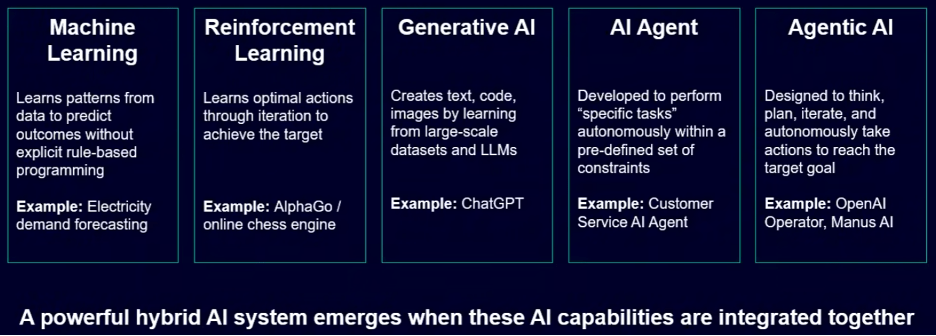
Fig. 2: Categories of AI and their use cases. Source: Siemens EDA
However, these advances don’t mean that every new technology is superior to those that already existed. “Don’t forget about the underlying math,” says Cadence’s Knoth. “AI is a fantastic technology, but AI in a vacuum is not always the most efficient or effective way to get to an answer. If you have the math and the physics to describe a system, computing the answer is an incredibly effective, accurate way to get the work done. AI can help accelerate that. AI can learn from what we’re calculating. But you can’t abandon those first principles. You can’t abandon this true knowledge of the domain, because it really is a superpower. And if you think about how they can reinforce and help each other, that’s where the real magic comes in.”
Most EDA tools continue to be rule based. “You still have some end goals and end constraints you’re dealing with,” says Michal Siwinski, chief marketing officer at Arteris. “With that being the framework, you’re going to have AI inside and AI outside. Both are needed, but they’re going to behave differently. Given the number of tools that have already adopted AI internally, and which show consistent and credible good results, that question about AI was answered at the turn of the decade. Since then, it’s just refining it and making it better.”
Unique demands of EDA
The cost of failure is high for any chip design, meaning that accuracy and verifiability are two very highly regarded features in EDA tools. “They don’t want AI to be a black box solution that spits out an answer, and then you’re not sure if it’s correct or not,” says Siemens’ Gupta. “You want transparency and visibility into how it came up with the solution, and therefore make it verifiable. It needs to work across a broad scope of design problems, not for specific cases, but general robustness.”
Correctness is an easier problem to solve when dealing with optimization. “Reinforcement learning based optimization technologies are essentially geared toward helping address this problem,” says Synopsys’ Thiruvengadam. “Generally, in chip design, you are contending with a very large design space, an optimization space, and you have to have an efficient way of exploring that space to come up with the right solution, the best answer, or a set of best answers. That’s a very tough problem. That’s where AI can help.”
Design optimization makes an engineer more productive. “This is helping one engineer be incredibly effective at a subsystem level,” says Knoth. “This is helping to port a recipe that worked on one block to another block. This is about the hard work of delivering better PPA in a short amount of time, without requiring massive new engineering investments. This doesn’t use large language models. It is using reinforcement learning. You can’t just get distracted by the latest shiny thing. It’s about building on and owning the awesomeness that you’ve built up over decades.”
Applying the wrong models to a problem is where trouble begins. “A lot of the AI techniques that incumbents are frustrated with are basically just vanilla LLM calls wrapped around generic GPT models,” says Hanna Yip, product manager at Normal Computing. “They don’t understand the specific context and code bases that design verification engineers operate in. That leads to hallucinations and missed context, which is fatal in chip verification. AI needs to leverage more than just these basic models. Formal modeling and agentic approaches within the code base are the right way to approach it.”
The problem scale is beyond some of the commercial offerings. “We’re not just using off-the-shelf AI, open-source algorithms, and applying it to EDA,” says Gupta. “Rather, we consider the scale of the problems that we are dealing with. We’re talking about having seven process parameters per device from the foundry. We’re talking about millions of devices. We’re talking about huge dimensionality problems. Tools also have to be able to understand the different modalities that exist in EDA. There are schematics, waveforms, Excel spreadsheets, and they have to be aware of both chip design and board design.”
The goals have not changed, even if there are new ways to approach them. “You still have decision trees inside of every technology,” says Arteris’ Siwinski. “Within that, you can replace some dumb heuristics. Can you do better with reinforcement training, or maybe do some better clustering and classification using AI techniques to do some analysis upfront? There are dumb ways to analyze, and there are smart ways to analyze. Are there ways to basically make sure that the heuristics within all the technologies get better and continue to get better? The short answer is yes. Almost every modern tool has some degree of this, because you’re just changing the type of algorithm and the type of math you’re using to perform the task. Whether it is design, verification, or implementation, you’re just changing algorithms.”
With the good comes some bad. “You need data to train the models,” says Rich Goldman, director at Ansys, now part of Synopsys. “That gives a huge advantage to existing IC design companies, and existing EDA companies. It’s going to make it harder for startups to get involved with the creation of EDA tools. It’s harder for them to get that advantage from the models. There are going to be generalized models that will be provided, and LLMs that they can leverage, but not to the extent that established companies will be able to, because they have the data.”
Gaining confidence
One of the big problems is ensuring tools that use AI can be trusted. “Sign-off is all about trust,” says Knoth. “Accuracy plays a huge role in that, but it’s really trust built up over time, over generations, proving that when I get this number out of the system, I can safely make a decision based on it. That’s the really important part. Computation, calculation is what forms the basis of that trust and the rough knowledge of how the tool is working, so that you know when you’re throwing it something it’s never seen before.”
That requires transparency. “Current AI solutions are just black boxes,” says Prashant, staff product manager at Normal Computing. “What is needed is an approach that generates collateral that makes the AI’s reasoning visible. That could be through formal models, ontologies, and linked test plans, allowing design verification engineers to see exactly how the tool’s output maps back to the specification. This interpretability is what builds confidence in AI, and especially in a high-trust environment like chip design, you need confidence that this isn’t just a black-box output.”
Tools need to explain what they are doing. “When dealing with four-, five-, or six-sigma problems, we plot an AI convergence curve,” says Gupta. “Then the user can see what the AI is doing. It does some training of a model, and then it starts finding the six sigma points. It predicts the worst case and runs a simulation against that point to verify it. Then it will get the second worst point, the third worst point. In some cases, it may be wrong, but then it will rerun some training under the hood to build up a more accurate model. It’s an adaptive model training approach that is constantly improving, until it has enough confidence that it’s found all those outliers. Still, there might be a case where there are one or two outliers that it didn’t find, but it’s much better than the manual way of doing it, of doing hundreds of simulations and extrapolating. It’s getting close, almost as good as doing a brute force approach.”
One industry concern is hallucinations. “When I hear people talking about AI hallucinating, I just look at it as a garbage-in, garbage-out problem,” says Siwinski. “It’s just math. As we do this in our industry, as we leverage this technology, we definitely have to make sure that we feed it the right data sets for training. Otherwise, we might end up having the wrong answer. It needs checks and balances. You shouldn’t just give it anything. In a business-to-consumer world, you can tell AI to create crazy images based on whatever is out there. That’s an extremely unconstrained problem. We are less prone to hallucinations in our neck of the woods when using AI.”
It is wrong to expect any tool to solve the whole problem in one chunk. “Hardware requires full-system consistency,” says Arvind Srinivasan, product engineering lead at Normal Computing. “You can’t just generate a piece in isolation and hope it makes sense overall. That’s very different from language, where you can write one paragraph that works independently. On top of that, there’s not enough data. We don’t have trillions of examples. IP is locked up in silos, even within a company. You can’t just do supervised learning. You need algorithms that incorporate prior data about system constraints while still learning from that data. Labeling is expensive. You can’t pay chip engineers six figures to annotate training sets. Without ground truth, verifying AI results requires deep industry expertise, which makes evaluation much harder than in consumer domains.”
You don’t always want to constrain the problem. “AI techniques allow us to address problems with more ambiguity,” says Benjamin Prautsch, group manager for advanced mixed-signal automation in Fraunhofer IIS’ Engineering of Adaptive Systems Division. “But at the same time, the result will be more ambiguous. Thus, they must be carefully checked/tested. Positive experience of the users and evidence seen is really the key. For instance, verification tools are seen as ‘golden tools,’ and this is what the market’s view is. It will only be possible to convince people by having a great track record, which is still to be proven.”
But you may want AI to move outside the box of the obvious. “AI is amazing at checking or unchecking the biases, where you give it more degrees of freedom,” says Siwinski. “It still needs to obey some rules, and you still need to hit some performance, so you can’t just do whatever. But, as long as you do that, can you get the AI to give you a different answer than what the expert would have created? Within some constraints, you want that creativity. You want to explore the broader design space, and sometimes it is going to find a different, better answer because the engineer is making some presumptions based on what worked best in the past. They’re valid assumptions, but it doesn’t mean it’s the only way to get there.”
Value can be created in multiple ways. “People don’t use AI tools because they’re always correct,” says Normal’s Yip. “They use them because they save a huge amount of time compared to traditional approaches. The real challenge is making sure engineers aren’t wasting time reviewing bad outputs and giving them the right tools to inspect and fix them. The framing should be, ‘Does it save engineers more time than it costs to review?’ If yes, it earns trust.”
Even some existing EDA tools have not yet gained that trust. “Silicon engineers don’t have an inherent trust in existing EDA design tools beyond pretty basic functionality,” says Marc Bright, silicon lead at Normal. “We spend a lot of time running other tools and writing our own to check the quality of their outputs. When AI tools reduce the effort and time to generate those outputs, then we can spend more time evaluating and refining potentially better solutions.”
Part of the problem is that AI doesn’t have a lot of examples to learn from. “Low propensity languages are ones that lack sufficient data and resources for effective natural language processing,” says Knoth. “If you ask AI to write a document in English, it has been trained on a trove of English. So if you’re asking it to generate a technical specification, that’s something that AI already has a large amount of data to draw from. If you’re asking a large language model to generate C code, that is also trustworthy. It has a smaller body of data that it’s been trained on, but there’s still a lot of C code publicly available and ways to verify the generated code. Let’s keep going down the stack. The amount of publicly available data to train on Verilog is a fraction of what you had for C code. Go even further down — Skill, TCL, UPF. Our industry is rife with these languages, where the amount of high-quality, publicly available data to train a model on is challenging. Inside each company that’s deploying this, they have a fairly large treasure trove, but figuring out how to apply that proprietary IP into a large language model, in a computationally efficient manner, is non-trivial.”
[Editor’s note: Next month continues with an exploration of the models that make sense for use within EDA, the ways they need to be extended, and how AI can help create models that are used with aspects of an EDA flow.]