Generating effective representations of data is crucial for many machine learning tasks, yet current methods often depend on pre-defined encodings that may not capture the most relevant features. Shengxin Zhuang, Yusen Wu, and Xavier F. Cadet, alongside colleagues from The University of Western Australia, Imperial College London, and the University of Paris City/University of Reunion, now demonstrate the power of autoencoders, a type of neural network, to learn these representations directly from data. The team proves that this autoencoder method efficiently learns from data, and then trains it on a massive dataset of three million peptide sequences. Results show that representations generated by the autoencoder improve accuracy by between 0. 4% and 8. 1% across seven different peptide classification problems, including predicting peptides with antihypertensive properties and those capable of crossing the blood-brain barrier, establishing a viable approach for practical applications and effective transfer learning without task-specific adjustments.
Peptide Activity Prediction Using Quantum Autoencoders
Scientists are exploring the use of quantum autoencoders and protein language models to predict the biological activity of peptides, aiming to classify these molecules based on their function, such as whether they lower blood pressure, act as antioxidants, or exhibit neurotoxic effects. This research utilizes extensive datasets of peptide sequences to develop machine learning models capable of accurately identifying peptide function. Several protein language models, including ESM-2, PeptideBERT, and BioBERT, are employed to generate representations of peptide sequences for analysis. The study leverages multiple datasets, including a large collection of over 3 million peptide sequences from the UniProt Knowledgebase for initial training, and smaller datasets focusing on specific activities like antihypertensive, antioxidant, blood-brain barrier penetration, cytotoxicity, hemolysis, and neurotoxicity, to evaluate model performance. Data preparation involves careful collection, filtering of non-standard residues, reduction of sequence redundancy, balancing of datasets, and encoding sequences for numerical processing. This research combines quantum autoencoders for unsupervised learning and feature extraction with protein language models to create a robust system for predicting peptide function, harnessing the power of quantum machine learning and data-driven representation learning to advance bioinformatics.
Learning Peptide Representations with Quantum Autoencoders
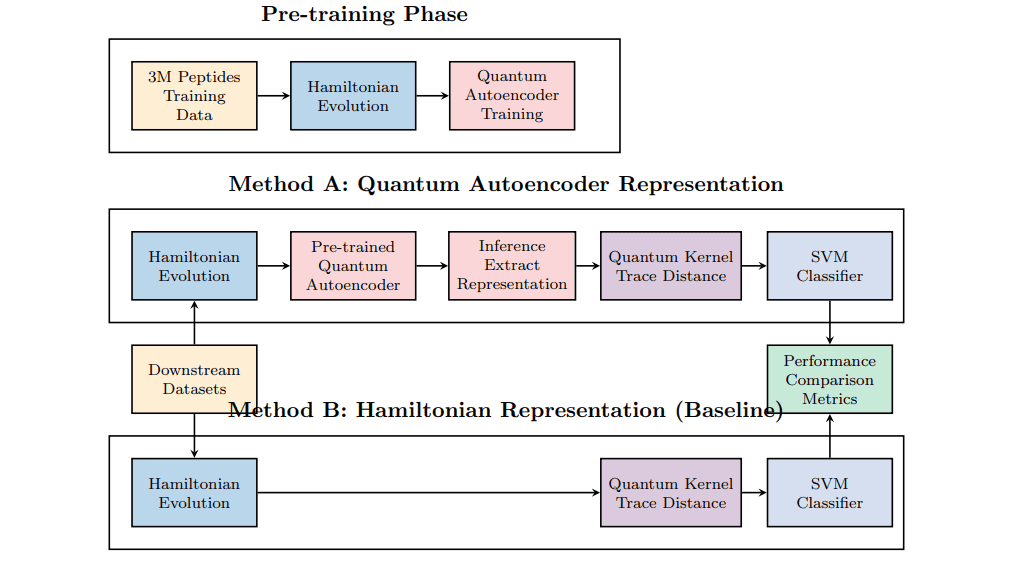
Researchers have developed a novel method using quantum autoencoders to learn data-driven quantum representations, moving beyond traditional fixed encodings in quantum machine learning. The team demonstrated the theoretical efficiency of this approach, showing its ability to minimize the amount of data needed for training, and trained these autoencoders on a substantial dataset of 3 million peptide sequences. These learned representations were subsequently tested across seven distinct peptide classification datasets. The methodology involved a direct comparison between representations generated by the quantum autoencoders and those derived from alternative quantum baselines, utilizing a quantum kernel with support vector machines for evaluation.
This allowed scientists to isolate the impact of the learned representations, demonstrating improvements ranging from 0. 4% to 8. 1% in accuracy across the seven datasets, and highlighting the effectiveness of pre-training for transfer learning without task-specific fine-tuning. Notably, the quantum autoencoder architectures learned effectively from the large-scale dataset while maintaining compact parameterizations of approximately 900 parameters, demonstrating their potential for practical quantum applications and establishing that quantum autoencoders can provide measurable improvements in supervised peptide classification tasks compared to static encodings.
Quantum Autoencoders Improve Peptide Classification Accuracy
Scientists have demonstrated the power of quantum autoencoders in learning effective data representations, achieving measurable improvements in peptide classification tasks. The research team trained quantum autoencoders on a substantial dataset of over 3 million peptide sequences, then evaluated the resulting representations across seven distinct computational biology datasets. Results demonstrate that representations learned by the quantum autoencoders consistently outperform those derived from alternative quantum baselines, with accuracy improvements ranging from 0. 4% to 8. 1% across all tested tasks.
This breakthrough establishes a quantum analog to classical representation learning, showcasing the ability of unsupervised quantum pre-training to enhance performance without task-specific fine-tuning. The study employed support vector machines with trace distance kernels to ensure a consistent downstream classifier and data input for accurate comparison, revealing strong transferability as models generalized effectively to diverse downstream tasks. The team established a methodology for unsupervised quantum representation learning, training quantum autoencoders with varying compression schemes and circuit depths to optimize performance. Measurements confirm that the quantum autoencoder approach delivers consistent improvements over alternative quantum baselines, establishing its viability as a practical component in quantum machine learning workflows.
Quantum Autoencoders Learn Peptide Representations Effectively
This work demonstrates the successful application of quantum autoencoders for learning representations from peptide sequences. Researchers established that these autoencoders train efficiently on large datasets, specifically a corpus of three million peptide sequences, without encountering the training difficulties known as barren plateaus. Importantly, the resulting quantum representations consistently improved classification performance across seven diverse datasets when compared to established alternative quantum baselines. These findings establish a quantum analog of representation learning, showing that unsupervised pre-training can effectively extract meaningful features from biological sequences.
While the magnitude of improvement observed was smaller than that achieved by classical pre-trained language models, the results highlight the feasibility and potential of quantum approaches to bioinformatics, and suggest learned quantum representations offer a promising alternative to fixed encoding strategies. Future research directions include scaling the quantum autoencoder architecture, developing hybrid quantum-classical pipelines, and integrating these methods with classical pre-trained language models to leverage the strengths of both paradigms. This work represents a significant step towards harnessing the power of quantum machine learning for biological data analysis and opens new avenues for developing more accurate and efficient bioinformatics tools.