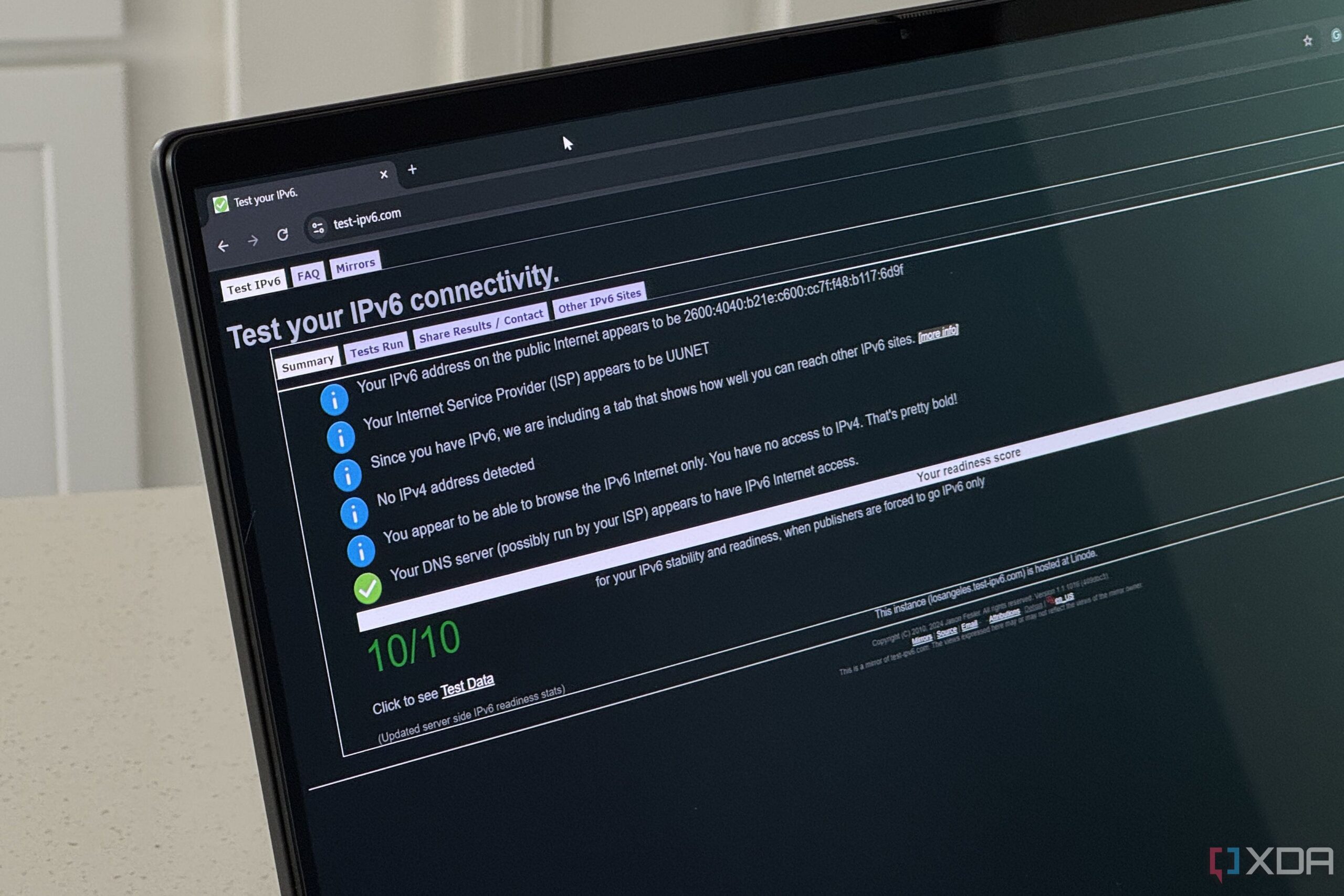
Networking, whether on internal networks or across the Internet, was set up to use the Internet Protocol for relaying datagrams across network boundaries. It’s essentially the addressing layer for the Internet, and whether it’s IPv4 or IPv6, tells network hardware where it should route the packets passing through it, in the same way that an address on an envelope tells the postal service where to deliver a letter.
The system worked, except for one thing: Once the Internet took off, IPv4 soon ran out of address space, so IPv6 was created to add billions more unique addresses. The transition to IPv6 has been slow (seriously, it’s been going on for a quarter of a century now), and part of that is how good the Internet’s dual-stack has become, where IPv4 gets translated to IPv6 for transport and then translated back to IPv4 at the other end.
But the other part of the equation is that the Internet’s architecture has changed. Clients or servers no longer need persistent, unique IP addresses for data to be effectively routed to them. Increases in transistor density altered the world of computing from a scarcity model to one of abundance, and that’s where we are now, with Content Delivery Networks (CDNs) caching local copies of content and services close to the user, just in case. It’s a fundamental shift, and because CDNs run on domain names, not IP addresses, the old worries about running out of IP addresses are less valid.
Related
10.0.0.1 times it really was DNS
Sometimes memes are grounded in truth.
The Internet had to scale quickly
The rise of mobile, driven by the iPhone, meant IP workarounds
When IPv4 addresses were rapidly running out in the early 2000s, it was thought that personal computing would be the primary driver of IPv6 adoption. That made sense to most analysts and networking gurus, but then one thing happened—one major inflection point that put a web browser in everybody’s pocket. I’m talking, of course, about the iPhone’s introduction in 2007, which made cellular carriers, like T-Mobile, have to decide between scaling to meet demand or deploying IPv6 more widely.
Early scaling is how we ended up with NAT, which turned one external IPv4 address into a way of addressing every device on your home network so it could be reachable from the Internet. That slowed the issue down, and IPv6 adoption grew, but slowly.
When home users were using 6to4 tunnels to add IPv6 to their routers, T-Mobile went the other way, going IPv6-only for its transportation layer. That meant it needed a translation tool on either end to convert to and from IPv4, and it found this in 464XLAT. This combines stateless translation on the consumer side (CLAT) with stateful translation on the provider side (PLAT) to allow IPv6-only devices to talk to IPv4 servers, and it worked so well that it’s still in use.
IPv6 still grew thanks to countries with low IPv4 allocations
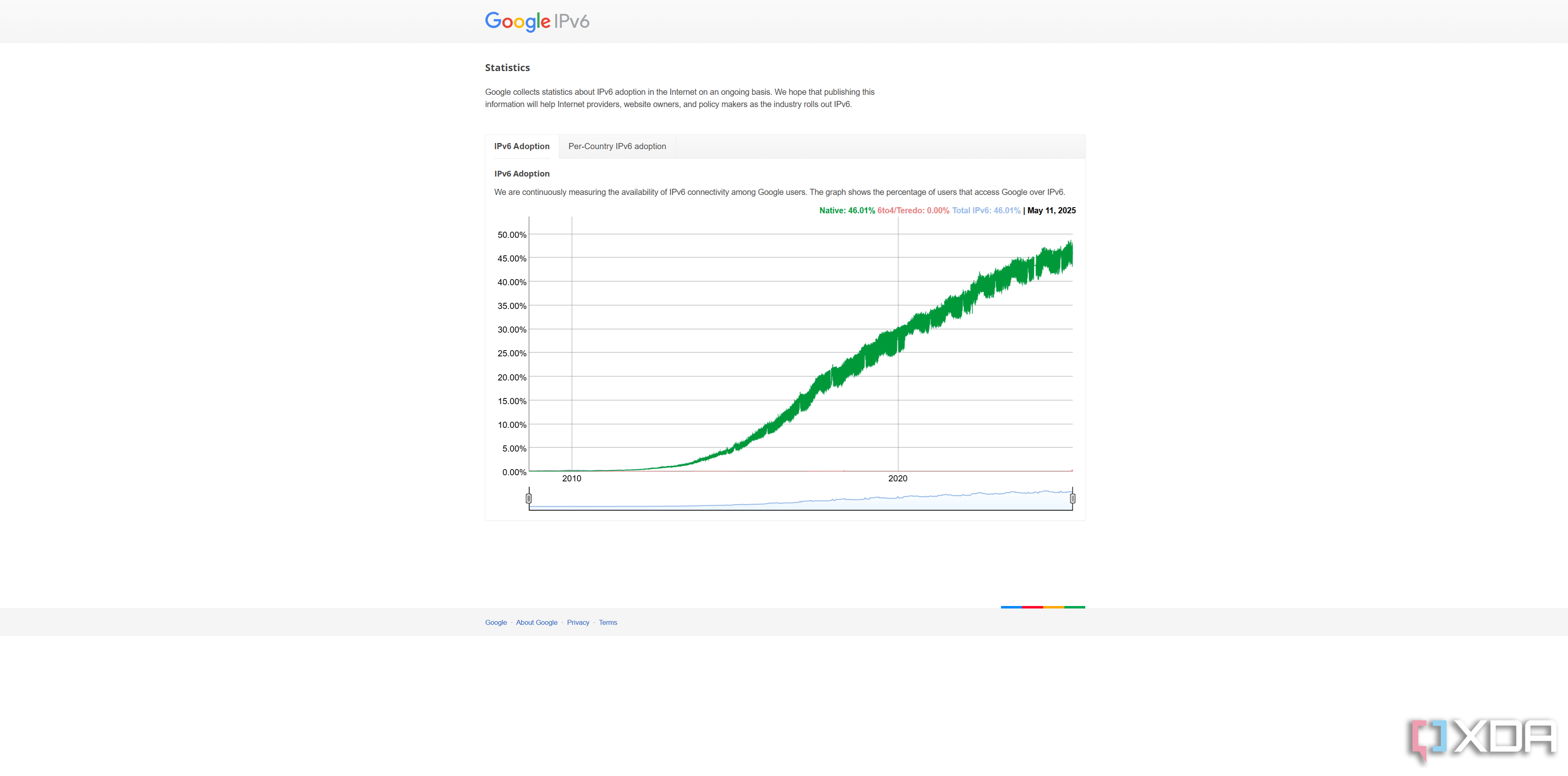
When the Internet Assigned Numbers Authority (IANA) handed out IP blocks to regional registries, not every country got its fair share based on population. China and India, for example, received nowhere near one IPv4 address per person, while the United States got 4.6 per person. That imbalance meant those countries needed to adopt IPv6 much sooner, which is a significant factor in why the worldwide adoption rate is over 40%.
Related
I tried living entirely on IPv6 for a day, and here’s what happened
Spoiler: Don’t do this to yourself
Content delivery networks are how the majority of content reaches end users
And those run on domain names, with DNS steering users to the closest service point
The Internet is no longer served to users from individually addressed servers. Not that those have gone away, but the rise of cloud providers, global data centers, and content delivery networks (CDNs) means that the old ways of routing data have changed. Instead of the Internet being focused on the network layer being the revenue driver, it’s moved up the stack to the app layer. Data is no longer stored for on-demand pulls; it’s pre-provisioned and cached globally for just-in-case availability.
The Internet is no longer served to users from individually addressed servers
When multiple copies of the data a user might need are on different servers or even on different continents, you need a different routing model. And it just happens that DNS (Domain Name System) is the answer. When you request data from a domain that a CDN handles, it uses your general geographical area and advanced routing to respond from the closest cached copy of the data or service, while keeping the IP address of the physical server hidden from the user. It’s generally faster, safer, and easier for users, developers, and sysadmins to use, but as we’ve all seen, CDN issues prevent huge swathes of the Internet from being accessed.
DNS is becoming more important than IP addresses
The changing infrastructure of the Internet has made IP addresses less of a concern outside private networks. End users don’t need to know where CDNs have stored the resource they’re trying to access; they only need the domain name of that resource. The CDN is responsible for matching those domain names to the closest cached copy of the requested data, and it all happens transparently to the user.

Related
IPv4 was meant to be dead within a decade; what’s happening with IPv6?
IPv4 has long outstayed its welcome, yet IPv6 still isn’t the norm. What’s happening?
Content is king, even when it comes to connectivity
The dual-stack of IPv4 and IPv6 on the Internet might never disappear completely, but that’s perfectly fine. Like many things in life, it doesn’t have to be one or the other; they can happily coexist. And with the rise of content delivery services, Internet Protocol translation layers, and the decentralization of the Internet, IP address space is less of a concern, as the CDN handles the complicated parts so that you can use domain names for everything.