Hand biometrics, including fingerprints and palmprints, are widely used for secure identification due to their high identification accuracy and non-intrusiveness. It is one of the most used in multiple applications. Actually, multibiometrics and precisely multimodal biometrics are increasingly gaining popularity. They showcased their efficiency by delivering superior performance and increased universality. Recent applications focus on ensuring greater convenience and reduced user cooperation in the development of user-friendly biometric systems1. Hence, multimodality becomes essential to achieve user satisfaction and construct ergonomic security applications without compromising the required accuracy. Multimodal systems further enhance performance by fusing complementary features. Developing robust biometric solutions requires carefully balancing interpretability, efficiency, and accuracy. Traditional methods, using well-defined mathematical models, offer high interpretability and can be computationally efficient. However, they might fail to capture complex variations in biometric data. In contrast, deep learning2 methods excel at learning rich, hierarchical representations directly from data. Which leads to significant gain in accuracy and adaptability. However, it comes at the cost of reduced transparency and increased computational demand.
Deep learning techniques are increasingly applied in palmprint and fingerprint recognition, with distinct methodologies tailored to specific challenges. Authors3 propose PRENet, a CNN-based ROI extraction method that ensures dimensionally consistent palmprint regions. Which is paired with SYEnet, a lightweight neural network leveraging four parallel learners for efficient feature extraction. Meanwhile, Authors4 introduce a self-supervised learning framework comprising two phases: (1) pretraining on unlabeled data and (2) self-tuning the model for refinement.
For fingerprint recognition, LSTM is employed to model dynamic ridge flow patterns by analyzing spatial feature sequences5. Another approach combines Siamese networks with SIFT descriptors to isolate discriminative features from partial fingerprints6. Additionally, Gannet Bald Optimization (GBO) is utilized to train Deep CNNs, enhancing the classification of fingerprint patterns7. Table 1 summarizes the studied approaches.
In multimodal systems, the fusion of processed data can occur at various levels depending on the modalities. Decision and score levels are universally applied to all modalities8,9,10. At the feature level, fusion involves combining extracted features from each modality through data analysis techniques aimed at reducing high dimensionality11,12. Features encapsulate rich and discriminant data extracted from biometric modalities, thereby amplifying the overall effectiveness of the fusion process. Successfully executing fusion at this level holds significant promise for enhancing system performance and accuracy11. Authors13 study impact of multimodal feature proportion on matching performance. They find that unequal proportioned fused vector is more efficient than 50%−50%. As they use fingerprint and face, these results sound coherent since the two modalities have dissimilar matching performances. Moreover, if any features’ filtering is applied to get discriminant ones, the fused features will not ensure improvement of matching performance. Therefore, in feature fusion, we must consider accuracy of each uni-biometric system based on fused features. Each selected feature has an impact on the success of identifying individuals and discriminating between them. Furthermore, feature selection is necessary to preserve only discriminant features. This constitutes the key to improve identification rate and reduce template storage and processing time costs. This assertion finds support in a study conducted by Santos et al.14. This study explores data irregularities and their impact on the overall classification rate.
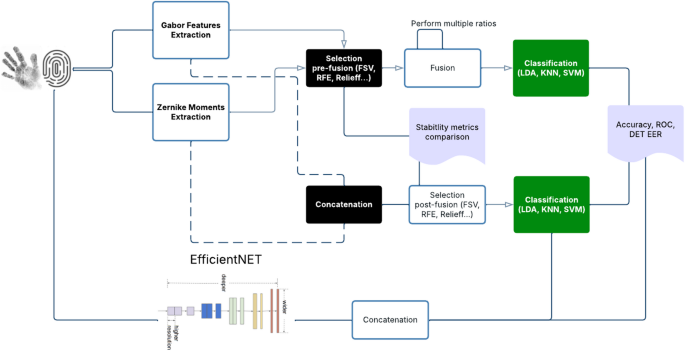
In this paper, we compare traditional feature extraction (Gabor, Zernike) with deep learning (EfficientNetV2) in a multimodal (fingerprint + palmprint) framework. We analyze fusion strategies and selection robustness. First we start by extracting features from the two modalities using Gabor and Zernike moments. Through intensive testing, we identify the most suitable method for each modality. We then select the adapted one along with appropriate parameters. Subsequently, we employ various selection and classification methods. We aim by that to objectively assess the impact of fusion and feature selection on the identification rate. Then, we compare with deep learning extractor using the latest optimized and fastest version of Convolutional Neural Network: EfficientNetV215. Our main objective is to show and analyse the efficacy and limitations of both techniques while dealing with fusion and selection methods. This can be a challenging task when working with unbalanced performances of fused baseline systems. In fact, an effective design of the fusion process plays a critical role in boosting system performance. This is why it is important to study thoroughly features using ranking methods. The applied selection methods achieve good results in preserving classification accuracy. Therefore, we further analyse the stability of their ranking with samples variations using multiple metrics. The implementation code and associated results are available at Github.
Selection and fusion of features
Biometric features have significant influence over recognition or identification rates, potentially contributing positively or negatively. The curse of dimensionality, primarily responsible for limitations in efficiently processing high-dimensional feature spaces16, presents a considerable obstacle. While data richness can be advantageous, redundant features within intraclass and interclass contexts may impede performance. In multibiometric systems, fusion at a single high level (Rank, Decision, Score) does not guarantee accuracy enhancement, as different matchers can yield significantly diverse performances17. Therefore, striking a balance between the quantity and quality of features becomes crucial. Ensuring sufficient high-quality features capable of effectively identifying numerous classes is imperative for optimizing identification rates using classifiers.
Feature extraction
Feature extraction is the first and one of the most important steps in the biometric process. Texture extraction methods or operators as described by Amrouni et al.18, are perfect to process rich signals like fingerprint and palmprint. These modalities are known for their uniqueness and their universality, especially the palmprint texture18,19. Gabor filters and Zernike moments are commonly used to extract feature vector from texture images20. While minutia and principal lines-based methods extract characteristic points and features21, these two methods compute subspace and statistical information which remains invariant to rotation and translation22.
Fingerprint Gabor features
Gabor filters, a class of structure-based methods, are predominantly employed for edge detection and image enhancement23. Additionally, they serve as effective tools for pattern extraction, capable of capturing both local and global information within image texture24. In this paper, we utilize a 2D log-Gabor filter based on Fourier transform to compute features derived from phase congruency. The log-Gabor filter offers several advantages25. The non-presence of the DC-component ensures that the features remain unaffected by variations in the mean value. Its large bandwidth facilitates robust feature extraction across diverse datasets. The log-Gabor filter exhibits a Gaussian frequency response when plotted on a logarithmic frequency axis. This characteristic contributes to the filter’s effectiveness in capturing intricate texture patterns across different scales.
Palmprint Zernike moments
Zernike moments are widely used for different modalities classification such as fingerprint, face, iris, hand vein, finger knuckle, and signature26. The Zernike moments are invariant to rotation and can be invariant to scaling and translation using normalization of their orthogonal polynomials. In addition, they reach a near zero redundancy thanks to their orthogonal property27. In fact, independent features are extracted from moments of different orders. However, they are computationally more complex and time-consuming according to the chosen order. This can be overcome using fast computation algorithms28. The Zernike moments of order n and repetition m are defined by calculating each nth order of m repetitions Zernike polynomials in one loop as follows:
$$:{V}_{nm}left(x,yright)={R}_{nm}left(rright){e}^{imtheta:}:,:rin:::[-text{1, 1}]$$
(1)
where R is the radial polynomial based on factorials.
Deep learner extractor and classifier EfficientNET
EfficientNET15 is a family of Convolutional Neural Networks with faster training speed and better parameter efficiency. It combines training-aware neural architecture search NAS with adaptive scaling technique called MBConv. It applies progressive learning and adapts the regularization to the image sizes. The goal of the new version EfficientNETV2 is to find a good compromise between improving training speed and increasing parameters.
Feature selection
Classification models need a comprehensive set of features that are both relevant and non-redundant, enabling effective discrimination between classes in supervised classification scenarios. Conducting feature classification analysis without classes’ label can be valuable for evaluating feature contribution. On the other hand, prioritizing the acquisition of a subset of features with superior discriminant power is paramount29. In our context, it is important to use both feature evaluation and feature subset search as we are fusing features of different modalities. These features, extracted using two distinct methods, coupled with the observed variability in classifier accuracies, underscore the significance of evaluating each feature’s independence and non-redundancy. It is equally important to evaluate each feature, as it is assumed to be independent and not redundant, then we test the effect of feature selection on the identification rate. Consequently, we assess the impact of feature selection on the identification rate, employing a diverse array of methods from various classes, including variable elimination techniques such as filter and wrapper methods, as well as embedded methods30.
Next, we describe the different existing methods for feature selection that we use in our proposed scheme. These methods were carefully chosen to encompass the primary feature selection strategies, each employing distinct measures and criteria to evaluate the relevance of features31.
Filter methods
The filter-based methods evaluate correlations between features and the class label, and feature-to-feature or mutual information. They assess intrinsic properties of features independently of the classifier employed, offering simplicity and success across numerous applications through the utilization of a relevance criterion and a selection threshold30. Here, we introduce several filter methods utilized in our experiments, organized based on the relevance criterion:
These methods utilize correlation measures between features with or without considering class membership. The principal methods selected for our experimentation include:
Multi-Class Feature Selection (MCFS): An unsupervised feature selection method that assesses correlations between features independently of the class label29. It operates as a correlation-based feature selection method (CFS) for multi-class problems, leveraging Eigenvectors and L1-regularization.
Correlation-based Feature Selection (CFS): A method based on correlation that evaluates the pairwise correlation of features and identifies relevant features that exhibit low dependence on other features. The ranking is accomplished through a heuristic search strategy32.
The Relief-F Algorithm: is one of the six extensions of the relief algorithm. It is applied in multi-class problems and estimates the relevance of features to separate between all pairs of classes. It is the best approach, and it can provide results when stopped but it yields to better results with extended time and data33.
These methods build a graph model of the features to keep the relevant ones.
Laplacian: is based on Laplacian Eigenmaps and the Locality Preserving Projection34. Utilizing a nearest neighbor graph to model the local geometric structure of the data, it identifies relevant features that preserve the local structure based on their Laplacian Score.
Infinite Latent Feature Selection (ILFS): it performs feature selection using a probabilistic latent graph that considers all the feature subsets35. Each subset is represented by a path that connects the included features. The relevancy is determined as an abstract latent variable evaluated through conditional probability. This approach enables weighting the graph based on the importance of each feature.
These methods acknowledge the manifold structure, whether the class membership of the features is known or not.
MUTual INFormation Feature Selection (Mutinffs): is a method predicated on mutual information as a criterion of correlation36. Mutual information serves as an invariant measure of statistical independence, capable of quantifying various relationships between feature-feature or features-class, including non-linear ones, thereby yielding a relevant subset of features.
Unsupervised Discriminative Feature Selection (UDFS): seeks to select the most discriminative features using discriminative analysis and l2 1-norm minimization37. It considers the manifold structure of data based on the local discriminative information, as the class label is not used in the classification training.
Wrapper methods
A wrapper method explores the feature subset by considering the classification performance as an objective function30. It incrementally constructs the feature subset by iteratively adding and removing features to optimize the objective function and achieve the best classification performance.
Feature Selection with Adaptive Structure Learning (FSASL): is an unsupervised learning approach that seeks to identify the most relevant features while preserving the intrinsic structure of the data. As such, it simultaneously conducts feature selection and data structure learning38. FSASL leverages a matrix of Euclidean Distance induced probabilistic neighborhood for global manifold and induced Laplacian for local manifold to achieve this objective.
The Dependence Guided Unsupervised Feature Selection (DGUFS): is based on a joint learning framework that uses a projection-free with l2,1- norm39. The model, which places heightened emphasis on geometric structure and discriminative information, as well as Hilbert-Schmidt Independence Criterion, is tackled using an iterative algorithm.
Local Learning Clustering Feature Selection (LLCFS): integrates feature selection into an unsupervised Local Learning Clustering (LLC) framework, employing regression trained with neighborhood information. The nearest neighbors’ selection performed using τ-weighted square Euclidean distance and a kernel learning are applied to overcome LLC limitations against irrelevant features40.
Embedded methods
These methods integrate the feature selection into the training step to build an efficient selection model without increasing the computation time by evaluating different subsets recurrently like wrapper methods30.
Feature Selection concaVe (FSV): it is a feature selection method based on concave minimization. The concave minimization aims to minimize a bilinear function on a polyhedral set of vectors. The feature selection is integrated into the training step using a linear programming technique41.
Support Vector Machine-Recursive Feature Elimination (SVM-RFE): embeds Recursive Feature Elimination within SVM classification, utilizing weight magnitude as the ranking criterion42. A good ranking feature method does not necessarily provide a good subset of features. Therefore, evaluating the effect of removing one feature or more, that has the smallest ranking value, at a time seems to be interesting. It allows to construct gradually an optimized feature subset. The SVM-RFE employs a selection method that is an instance of the greedy backward selection.
Feature classification
We selected the following methods, widely referenced in classification literature30, with the aim of identifying the most suitable classifiers for our data distribution. We aim by this to testify the stability of the selected feature43.
Regularized linear discriminant analysis (RLDA)
This method is based on Linear Discriminant analysis that uses regularization to avoid data training failures44. Discriminant Analysis proves to be straightforward due to the relationship between the number of features and the number of samples. Specifically, for palmprint data, the number of features is less than the number of samples, while for fingerprint data, it is the opposite. Therefore, we utilize both minimal and maximal regularization to assess features’ independence and validate the competitiveness of this method compared to others.
K-Nearest neighbor (KNN)
It is a straightforward and effective supervised machine learning method that employs various distances and retains all training data while performing computations at runtim34,45 We examine the following distances: Euclidean, Cosine, Spearman and Correlation. In addition, we vary the number of neighbours in the range [2–10] and apply weighting.
Multi-Class support vector machine (MC-SVM)
There are different strategies of multi-class SVM where the principles are based on multiplying binary SVM and training them using one of the following strategies: One against One (OAO) and One Against All (OAA)46. We opt for the OAO SVM, as it is more suitable for biometric identification, employing a classifier for each pair of classes rather than one for each class.
Feature fusion
The concept of fusion has garnered significant attention across various research domains, including biometrics47. In the realm of biometrics, fusion techniques are motivated by the complementary nature of modalities and, conversely, the challenge posed by a lack of discriminant features48. Indeed, leveraging different modalities enables the construction of robust and adaptable biometric systems capable of mitigating the impact of feature scarcity. Nonetheless, fusion alone does not guarantee performance enhancement. The conventional approach of combining features through simple concatenation may lead to increased dimensionality, which can impede computational efficiency48. Recent research efforts have therefore focused on proposing quality-based fusion models49,50. Consequently, there arises a need to reduce feature dimensionality and prioritize the most relevant features for classification. Feature selection emerges as a crucial step in biometric fusion, offering performance stability without compromising classification efficiency. In this study, we aim to implement feature selection on fused vectors using methods outlined in Sect. 2.2, subsequently examining the impact of the resulting feature set on the classification process. Through the application of diverse selection methods, our objective is to evaluate feature ranking based on different criteria and stability metrics. Thus, we consider the impact of the applied selection on the identification and equal error rates.