Introduction
There has been a gradual decline in antibiotic discovery, contributing to antibiotic resistance crisis. Aljeldah (2022)1 reported that antibiotic resistance is advancing faster than solutions, leaving the world with few options for…
There has been a gradual decline in antibiotic discovery, contributing to antibiotic resistance crisis. Aljeldah (2022)1 reported that antibiotic resistance is advancing faster than solutions, leaving the world with few options for…
Hassen, W. et al. Air pollution dispersion in Hail city: Climate and urban topography impact. Heliyon9(10), e20608 (2023).
Yan, X., Ying, Y., Li, K., Zhang, Q. & Wang, K. A review of mitigation…
RB’s Animal House: Toga vs Nerds – EFE Gift Gathering Party
Please join us on Saturday, January 24 from 7pm to 11pm for the RB’s Animal House – a Toga party benefitting Roger Bacon’s EFE.
Tickets are…
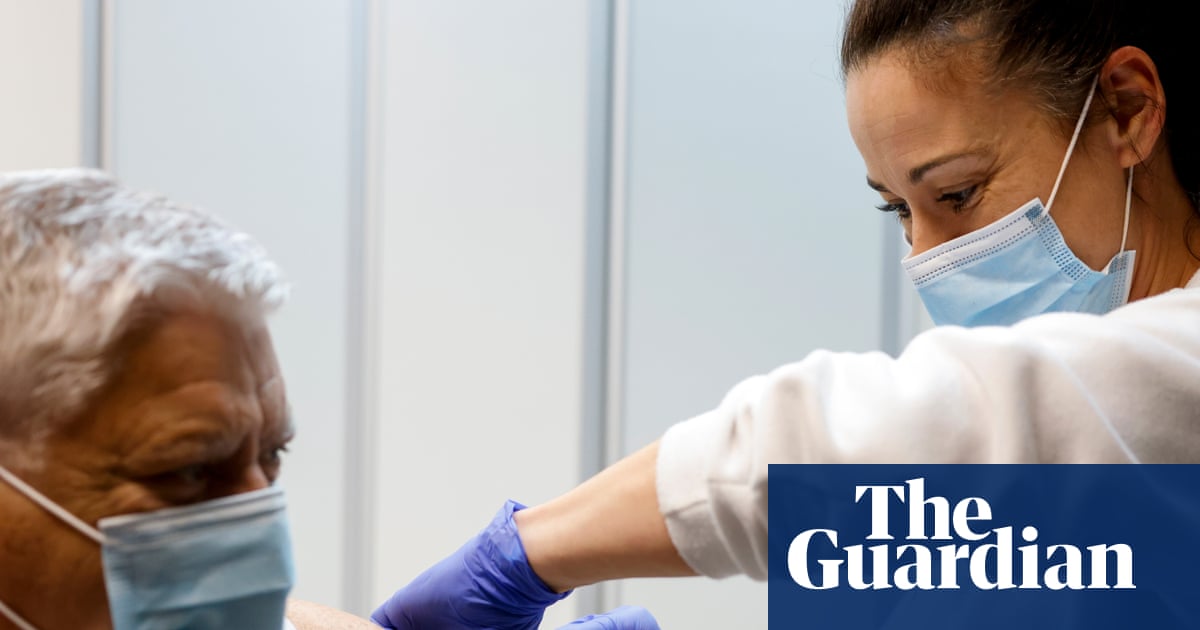
More than 2,500 Australians have rung in the new year with a highly transmissible new strain of influenza, and health authorities are on alert for what could be Australia’s worst year since tracking began 35 years ago.
Last year’s record, when…

News Release
January 7, 2026
The City of Toronto has officially opened applications and renewals for the 2026 CaféTO curb lane program, inviting restaurant and bar operators across the city to participate in one of Toronto’s most impactful initiatives supporting local businesses, vibrant main streets and neighbourhood life.
Launched in 2020 as a rapid pandemic response, CaféTO has grown into a permanent annual program that expands outdoor dining on curb lanes, sidewalks and private patios. In 2026, a year expected to bring increased activity and visitors to Toronto, CaféTO will play an important role in showcasing the city’s diverse local food scene while supporting restaurants, workers and neighbourhood economies.
In 2025, CaféTO supported approximately 1,500 outdoor dining spaces citywide, including 285 curb lane cafés, 579 sidewalk cafés, many of which can remain in place year-round, and 703 private patio endorsements that allow businesses to have a patio on private property. Participation continues to grow beyond the downtown core, with restaurants across Toronto using outdoor dining to attract customers, strengthen local main streets and create welcoming public spaces.
As the City prepares for a vibrant year ahead, CaféTO remains part of a broader suite of programs supporting Toronto’s restaurant sector and main streets. The City is building on the success of the 2025 season by continuing to improve efficiency, streamline process and provide earlier application timelines so that most curb lane cafés can be ready for the Victoria Day long weekend.
Applying for CaféTO
Restaurant operators interested in participating in the 2026 CaféTO curb lane program can learn more by visiting toronto.ca/cafeTO, where they can review program requirements, sign up for virtual information sessions or request one-on-one support before applying.
Details:
Once applications are submitted, City staff will work closely with operators and local Business Improvement Areas to develop traffic management plans that balance the needs of businesses, residents and road users, including loading zones, waste collection, cycling infrastructure and pedestrian access.
Experience CaféTO
The City encourages residents and visitors to explore CaféTO patios and support local restaurants from May through October. With expanded outdoor dining across Toronto, CaféTO helps ensure local businesses are ready to welcome increased activity and visitors, while continuing to create dynamic, inclusive public spaces in neighbourhoods across the city.
More information about the CaféTO program, including other outdoor dining options such as sidewalk cafes and private patios, is available at: toronto.ca/cafeTO.
Toronto is home to more than three million people whose diversity and experiences make this great city Canada’s leading economic engine and one of the world’s most diverse and livable cities. As the fourth largest city in North America, Toronto is a global leader in technology, finance, film, music, culture and innovation and climate action, and consistently places at the top of international rankings due to investments championed by its government, residents and businesses. For more information visit the City’s website or follow us on X, Instagram or Facebook.

About Alaska Air Group
Alaska Airlines, Hawaiian Airlines and Horizon Air are subsidiaries of Alaska Air Group, and McGee Air Services is a subsidiary of Alaska Airlines. We are a global airline with hubs in Seattle, Honolulu, Portland, Anchorage, Los Angeles, San Diego and San Francisco. We deliver remarkable care as we fly our guests to more than 140 destinations throughout North America, Latin America, Asia and the Pacific. We’ll serve Europe beginning in spring 2026. Guests can book travel at alaskaair.com and hawaiianairlines.com. Alaska is a member of the oneworld alliance, with Hawaiian scheduled to join oneworld in spring 2026. With oneworld and our additional global partners, guests can earn and redeem points for travel to over 1,000 worldwide destinations with Atmos Rewards. Learn more about what’s happening at Alaska and Hawaiian at news.alaskaair.com. Alaska Air Group is traded on the New York Stock Exchange (NYSE) as “ALK.”

On the heels of their first European tour under Music Director Gustavo Gimeno, the Toronto Symphony Orchestra (TSO)…

Unlock the White House Watch newsletter for free
Your guide to what Trump’s second term means for Washington, business and the world
The writer is distinguished professor of global economics and management at UCLA
Many Latin Americans have long…

A groundbreaking study conducted by researchers in Osaka, Japan has revealed a significant link between Type 2 diabetes and an increased risk…