Space is messy when a planet is being born. Dust swirls, gas stretches into rings, and gravity pulls matter into clumps that may one day become planets.
In one distant system, that process is happening right now, and astronomers have just spotted…
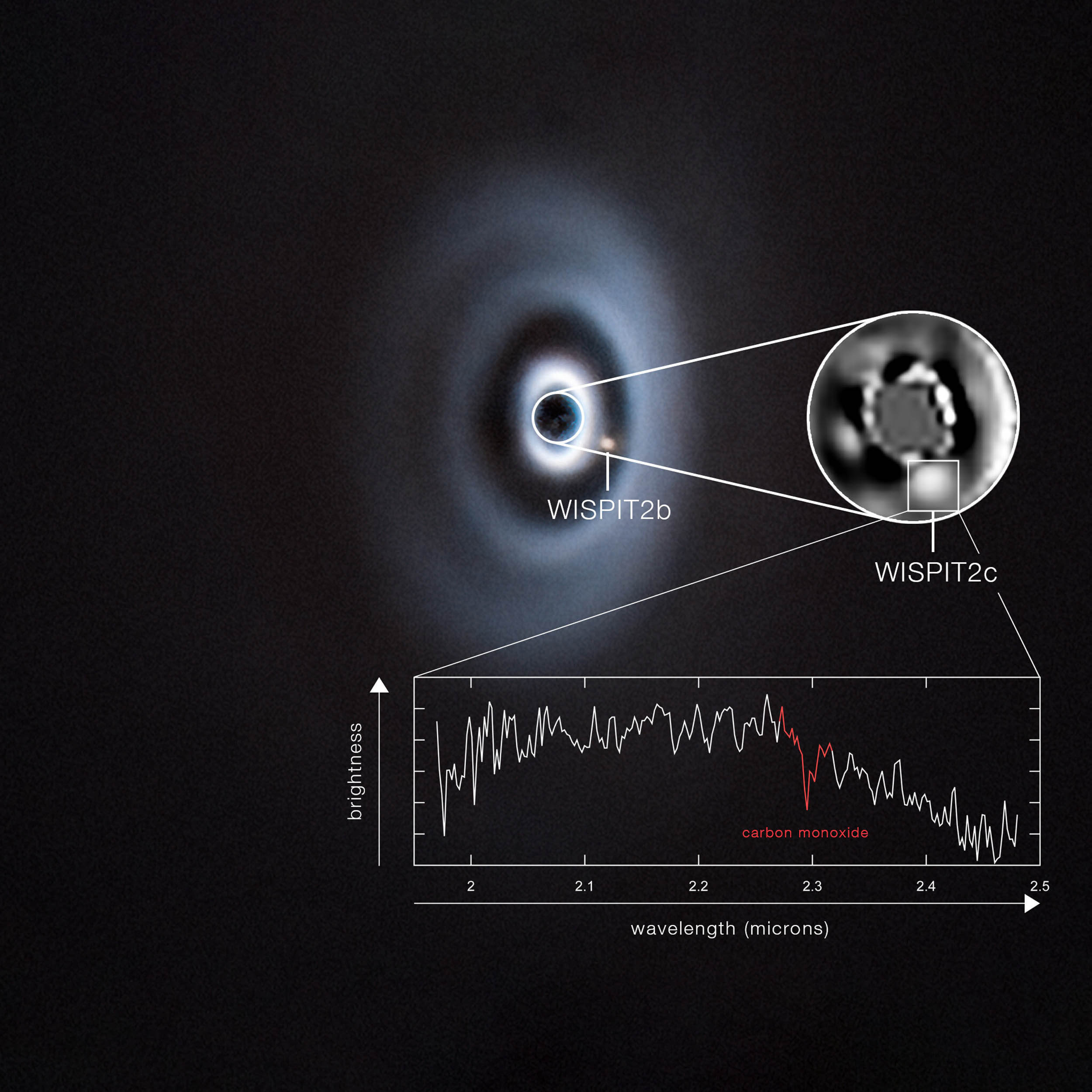
Space is messy when a planet is being born. Dust swirls, gas stretches into rings, and gravity pulls matter into clumps that may one day become planets.
In one distant system, that process is happening right now, and astronomers have just spotted…

It would be crass for Jonah Singer to reveal what he makes from being a YouTube content creator, but he will show Guardian Australia his new $100,000 mic. The 5128-C is a head and torso simulator (a half-manikin fitted with ear mics, capable of…
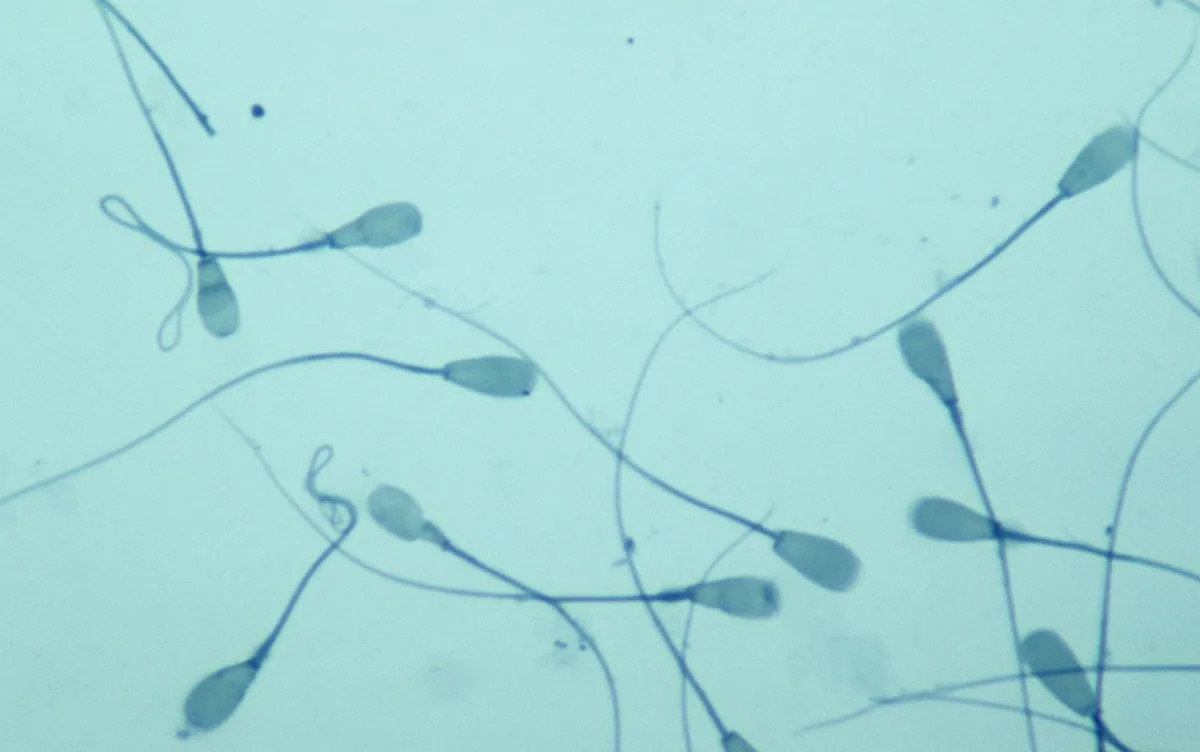
Scientists have used a tiny plastic obstacle course to find out if sperm would struggle to “navigate” during sex in space.
Some particularly resilient sperm did make it through the course, suggesting that conceiving children in space would be…

Summary
The NOTAM applies to flights operating through major Pakistani airports and is intended to ease pressure on domestic jet fuel supplies.

Thank you, Francisco, for the kind introduction. It is an honor to be here at the Economic Club of Miami.1 Tonight I will talk about a topic too large to ignore: the Federal Reserve’s balance sheet. Like any other bank, the Fed’s balance sheet is a record of the assets and liabilities we hold. The assets are primarily Treasury securities and agency mortgage-backed securities (MBS). The liabilities include all U.S. currency in circulation, reserve balances banks hold at the Fed, and the Treasury General Account. The size and composition of these holdings matter because they affect the amount of money in the banking system and influence broader financial conditions. Understanding how the balance sheet functions is essential to understanding how the Fed supports economic stability and conducts monetary policy.
Tonight I will discuss the various regimes under which the Fed has operated its balance sheet and explain why, in my view, shrinking the size of the balance sheet is desirable. Next, I will explain why the challenge of shrinking the balance sheet is a solvable one, and then I will discuss potential paths forward toward accomplishing that goal. Finally, I will conclude with the monetary policy implications of such action.
The Case for Reduction
Modern balance sheet policy revolves around three somewhat nebulous concepts: “scarce,” “ample,” and “abundant” reserves. Before the 2008 Global Financial Crisis, the Fed operated with scarce reserves. Under that regime, the Fed kept reserves relatively tight and frequently intervened directly in the market, using open market operations to steer the federal funds rate to its target. After the crisis, the Fed moved to an ample-reserves regime, in which the banking system holds enough reserves that the Fed does not need to engage in active daily operations to control the policy rate. This system allows the Fed to control short-term interest rates primarily by setting rates at which it will participate in the market, or administered rates. During much of the post-crisis period, reserves were also described as abundant, or well beyond what’s needed for smooth market functioning. This was because quantitative easing (QE) policies dramatically expanded reserve balances.
There are numerous reasons why reducing the balance sheet is a worthy goal. We should aim for as small a footprint in markets as possible to minimize government-induced distortions, including funding market disintermediation. A smaller balance sheet also helps lower the chances of mark-to-market losses at the central bank and the volatility of remittances to the Treasury. In addition, a smaller balance sheet better protects the boundaries between monetary and fiscal policy by preserving the duration profile of the public debt as a fiscal policy item, keeping the Fed out of the credit allocation game across sectors, and reducing interest payments on reserve balances, which some in Congress view as a subsidy to the banking system.2 Finally, a smaller balance sheet preserves dry powder for a scenario in which policymakers must again confront the zero lower bound on interest rates.
Yet despite these benefits of a smaller balance sheet, many say it simply cannot be done. It’s a pipe dream—it’ll never happen.3 If you tell me something is impossible, I can’t help asking, “Really?” This trait has got me into plenty of trouble, but I can’t help myself. So let’s think through the possibilities here.
A Solvable Challenge
My topline assessment is that shrinking the balance sheet is a solvable challenge. Those who reject the idea out of hand simply lack imagination. In approaching this challenge, I see three primary questions.
The first question is, how much could we shrink the balance sheet? I think quite a lot, but that does not necessarily mean returning it to its share of gross domestic product (GDP) before the financial crisis. I see dipping to that level as not feasible. The growth in currency demand, the post-crisis regime put in place by the Dodd-Frank Act and reforms to the Basel standards, and the resulting changes to market structures and expectations all resulted in greater demand for reserves in the system.
The second question is, does reducing the balance sheet from here necessitate a return to scarce reserves? I argue not necessarily. Instead, the Fed can take steps to reduce the lines that demarcate scarce, ample, and abundant. Lowering these boundaries can be done through a variety of policies that I’ll touch on soon. Shifting these boundaries down would allow for retaining an ample-reserves policy while reducing the size of the balance sheet.
And the third question, is it desirable or even possible to return to a scarce reserves regime? I believe we could return to scarce reserves within the current regulatory and institutional framework, but it would entail tradeoffs. Those include accepting more volatility in short-term rates, more tolerance for active management of reserves from the Fed, and more frequent and regular use of Fed-provided liquidity like daylight overdrafts, the discount window, or standing repo operations.4 How you view the impact of these side effects will inform whether you think returning to scarce reserves is desirable.
Paths Forward
Is lowering the boundary between scarce and ample easier said than done? Perhaps, but I see a path forward to achieving that goal. Measures that could effectively shift the boundaries down are articulated in a working paper I co-wrote with some of my Federal Reserve colleagues, “A User’s Guide to Reducing the Federal Reserve’s Balance Sheet.”5 These actions include the following steps:
That is only a sample of the steps that we could take to reduce the size of the Fed’s balance sheet. There is much more in the paper, and I encourage you to review it. To be clear, both in the User’s Guide and in these remarks, I am not advocating any specific step. I’m simply listing options we were able to identify, so that if and when the time comes, the Fed will have some tangible actions we can take to move in this direction. Each option will require its own cost-benefit analysis.
Even if Fed policymakers were to opt to return to scarce reserves, taking steps to reduce reserve demand will make it easier to do so and allow the balance sheet to shrink further while minimizing downsides. Some of the options, like destigmatizing repo operations, the discount window and daylight overdraft credit, or conducting temporary open market operations, will also improve the state of the world in a scarce reserves regime. My own lean is toward reducing demand but retaining ample reserves, but it’s not a firmly held conviction.
Let’s return to my first question—how much can the balance sheet be reduced? As I said, the pre-crisis level is not a realistic benchmark, so instead I offer two alternatives. First, after the conclusion of the first round of QE, the balance sheet was about 15 percent of GDP. It is possible that this level of balance sheet was needed to accommodate the liquidity requirements of the financial sector before the second round of QE and subsequent asset purchases began scaling up the balance sheet for the purpose of achieving our dual-mandate goals, rather than financial stability. Or, second, before the start of open-ended QE in 2012, and in 2019, before the pandemic, the balance sheet was about 18 percent of GDP. This level, in theory, reflects the liquidity needs of the banking sector as the scope of Dodd-Frank and Basel requirements became clear, before the launch of open-ended QE. It also reflects the scope of possible balance sheet reduction after the crisis but before the pandemic. This level incorporates some of the so-called ratchet effects on the balance sheet, but not the ones incurred since the pandemic.6
Loosely speaking, this range could reflect $1 trillion to $2 trillion of balance sheet reduction, numbers that are reasonably provided in the User’s Guide without needing to return to scarce reserves. Of course, the optimal size of the balance sheet is a subject that warrants more serious work, and it’s possible it’s better to scale the balance sheet by a financial variable like bank deposits rather than by GDP. I don’t aim to settle this question today.
The tools identified in today’s User’s Guide would unlock substantial room to further reduce the balance sheet, which I would like to see. However, in a scenario in which the Fed is shedding securities from its balance sheet, policymakers also need to ensure that financial markets can absorb those securities with minimum disruption.
The most important thing we can do will be to go slowly. It is hard to overemphasize how important this is. It also means allowing securities to mature rather than selling them outright, which would realize losses on the balance sheet. I could imagine selling our securities if we saw them trading at a profit, but not otherwise. Some other steps in the User’s Guide might make it easier for the market to digest securities from our balance sheet.
Implications for Monetary Policy
Now that I have outlined some of the ideas we expand upon in the User’s Guide, I’d like to conclude my talk with a few thoughts on how balance sheet operations can affect the economy and monetary policy. I principally see that happening through two channels.
The first is through the supply of money and liquidity, the liability side of the Fed’s balance sheet, in a classic monetarist sense. Reserves are high-powered money, and increasing their supply is an expansion of the money supply. The second is through what economists call the “portfolio balance” effect, on the asset side of the Fed’s balance sheet. To expand on this concept, at a given set of prices, the private sector has a fixed capacity to absorb additional financial risk, including interest rate risk. The Fed’s removal or provision of interest rate risk to the public will therefore affect the private sector’s willingness to take financial risk overall.
All else equal, reducing the balance sheet has contractionary effects for the economy, through both channels.7 Contractionary economic effects of balance sheet reduction can be offset with a lower federal funds rate, so long as we are not at the effective lower bound. It is therefore likely that a resumption of balance sheet reduction warrants additional reductions in the federal funds rate relative to baseline projections. However, putting magnitudes on these effects is challenging, and I won’t attempt to do so just yet.
Conclusion
In closing, the benefits of reducing the size of the Fed’s balance sheet are clear and achievable. The Fed’s balance sheet can shrink, but policymakers should first take steps to make sure they are successful. I have laid out some of those possible steps today and offer further details in the User’s Guide. Each of those steps is likely to have some costs and benefits and will have to be duly studied and calibrated.
Implementing these steps before beginning to reduce the balance sheet means it will be some time before we can begin. Based on my experience with how government navigates the Administrative Procedure Act, this process is likely to take well over a year once the decision is taken to proceed. It could take several years. That timeline would dictate when the Federal Open Market Committee decides to begin reducing the balance sheet and studying how to implement these changes, including giving markets guidance on how new mechanisms will function. And once the process begins, I would counsel a slow pace of reductions to ensure the private sector can absorb all the securities shed off our own balance sheet. I am excited that all this can happen, but, if or when it does, I expect it to proceed slowly.
Thank you again to the Economic Club of Miami for the opportunity to speak here this evening. I look forward to your questions.
1. The views expressed here are my own and are not necessarily those of my colleagues on the Federal Open Market Committee or the Board of Governors of the Federal Reserve System. Return to text
2. By holding large volumes of MBS, the Fed preferentially injects credit into the housing sector in ways it does not for other sectors of the economy. This situation could be ameliorated either by reducing the balance sheet and allowing MBS to roll off or by exchanging MBS for Treasury securities. Return to text
3. See, for example, Stephen Cecchetti and Kim Schoenholtz (2026), “Warsh’s War on the Fed Balance Sheet,” Financial Times, February 16, https://www.ft.com/content/9b0c3d50-f397-4879-9161-75d0042370c1. Return to text
4. Advocates for scarce reserves point out that regular uptake of the overnight reverse repo facility or standing repo operations are themselves regular and frequent management of reserves. They have a point. Return to text
5. See Alyssa G. Anderson, Alessandro Barbarino, Anthony M. Diercks, and Stephen Miran (2026), “A User’s Guide to Reducing the Federal Reserve’s Balance Sheet,” Finance and Economics Discussion Series 2026-019 (Washington: Board of Governors of the Federal Reserve System, March). Return to text
6. See Bill Nelson (2025), “How the Federal Reserve Got So Huge, and Why and How It Can Shrink,” Southern Economic Journal, vol. 91 (April), pp. 1287–322; and Viral V. Acharya, Rahul S. Chauhan, Raghuram Rajan, and Sascha Steffen (2022), “Liquidity Dependence: Why Shrinking Central Bank Balance Sheets Is an Uphill Task (PDF),” paper presented at the Jackson Hole Economic Policy Symposium: Reassessing Constraints on the Economy and Policy, held at the Federal Reserve Bank of Kansas City, Kansas City, Mo., August 27, pp. 345–427. Return to text
7. The role of money supply in a system of administered rates remains a contested question, but given that much monetary policy works through signaling and commitment mechanisms, I view money supply as still relevant even with administered rates. Return to text

Donald Trump’s signature will soon appear on US paper currency, the treasury department announced Thursday.
The move marks the first time a sitting US president’s signature will appear on legal tender. To accommodate this change, the…

Minerva Fabienne Hase and Nikita Volodin clinched Germany’s first figure skating world title in eight years with a triumphant routine at the 2026 ISU World Figure Skating Championships in Prague on Thursday (26 March).
The Germans, bronze…

The liver plays a vital role in human health, regulating metabolism and blood nutrient levels, filtering toxins, and synthesizing important proteins for blood clotting. It is also sensitive to changes in diet, behavior, and environmental…