MIAMI — A work stoppage that leads to canceled games during the 2027 Major League Baseball season could disrupt plans under discussion to have big league players participate in the 2028 Los Angeles Olympics.
The Major…

MIAMI — A work stoppage that leads to canceled games during the 2027 Major League Baseball season could disrupt plans under discussion to have big league players participate in the 2028 Los Angeles Olympics.
The Major…
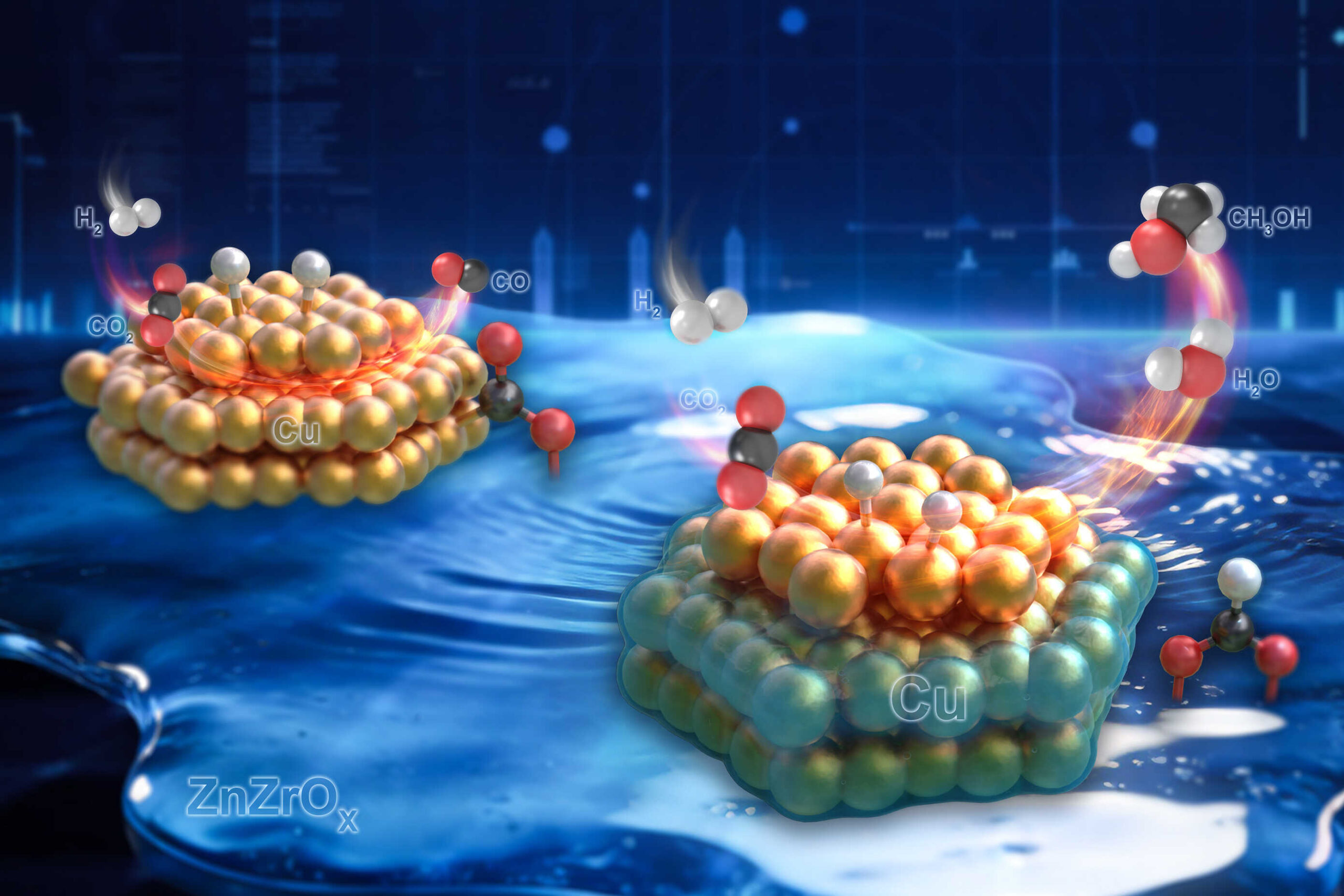
Efficient methanol synthesis is considered a promising approach for carbon resource recycling. Hydrogenation of carbon dioxide (CO2) to methanol is thermodynamically favored at low temperatures, but the sluggish…

The Guardian focuses on government plans to send “minesweeping drones” to the Strait of Hormuz, external. It says officials have warned that deploying warships, as requested by the US, could make the situation in the Gulf worse.
According to the…


Researchers at The University of New Mexico and Los Alamos National Laboratory have introduced a new computational approach designed to solve one of the most difficult problems in statistical physics. Their system, called the Tensors for…
Researchers at The University of New Mexico and Los Alamos National Laboratory have introduced a new computational approach designed to solve one of the most difficult problems in statistical physics. Their system, called the Tensors for…
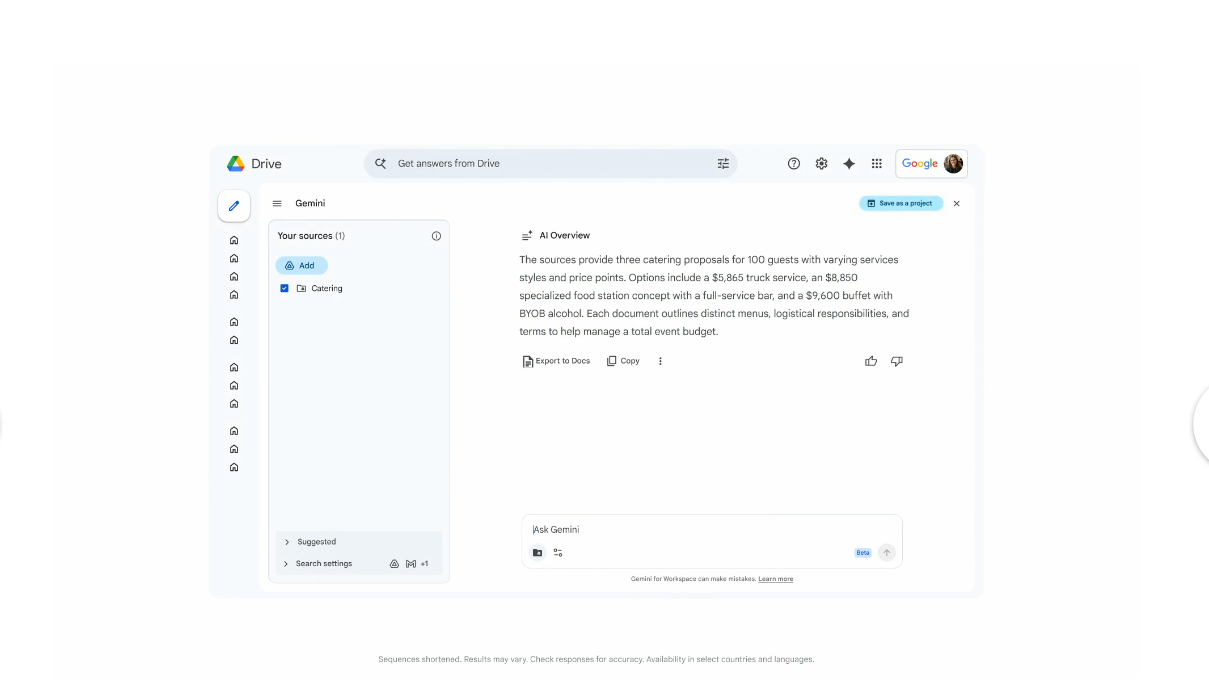
Google is expanding Gemini across Google Workspace, embedding new generative AI capabilities directly into Docs, Sheets, Slides, and Drive.
The updates introduce features that help users generate documents, analyze data, create presentations, and…

