Qaasid News
Download Our App
Latest News from Pakistan
INVNT® Appoints James Nicholas Kinney as Global Chief AI Officer, Advancing a New Era Of AI-Powered Brand Storytelling
December 16, 2025
This rare earthquake did everything scientists hoped to see
December 16, 2025
Tiny CMOS Photonic Chip Could Remove a Key Bottleneck in Scaling Quantum Computers
December 16, 2025
Behind the scenes at the Royal Opera’s spectacular Turandot – photo essay | Opera
December 16, 2025
Handbook on tuberculosis laboratory diagnostic methods in the European Union
December 16, 2025
Rob Reiner, director and actor, 1947-2025
December 16, 2025
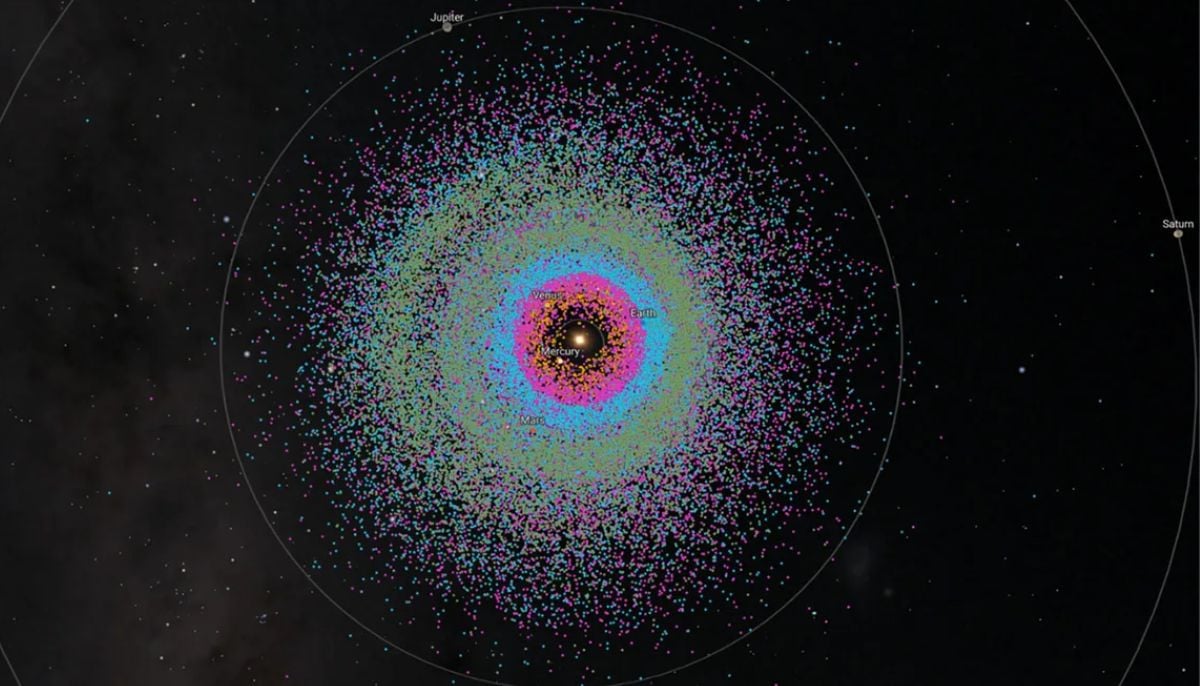
Discovery of 40,000 near-Earth asteroids could pose threat to Earth: Here’s how
December 16, 2025
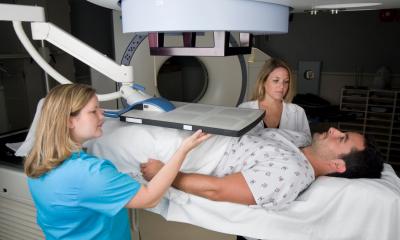
Repurposed radiotherapy scans to guide prostate cancer treatment • healthcare-in-europe.com
December 16, 2025
Gold prices in Pakistan Today
December 16, 2025
Menstruation Linked to Longer Football Injury Recovery – Medscape
December 16, 2025