Qaasid News
Download Our App
Latest News from Pakistan
Pakistan Navy takes command of CTF-150 for 14th time
January 29, 2026
Access Denied
January 29, 2026
the Olympic Flame has arrived in Cavalese for the 52nd stage
January 29, 2026
CFK is proud to unveil a host of new game features today (1/29) for the new rogue-lite deck-building game DeckLand .
January 29, 2026
10-month-old infant’s body recovered from Lahore manhole
January 29, 2026
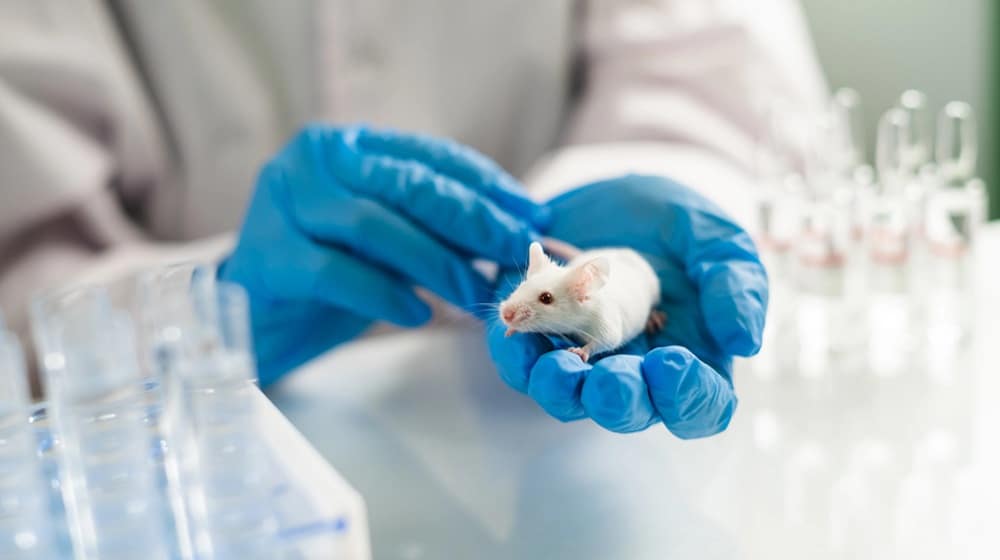
Scientists Successfully Eliminate Pancreatic Cancer in Mice for the First Time
January 29, 2026
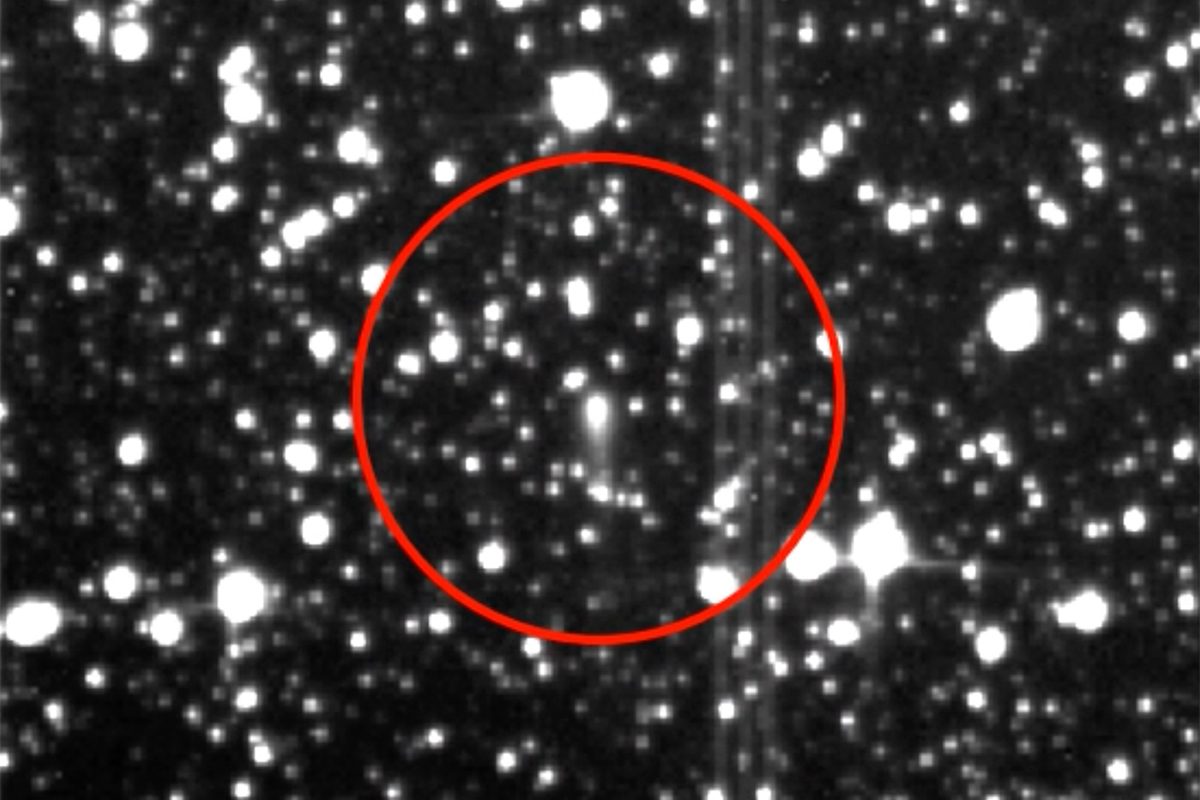
Comet 3I/ATLAS streaks across the sky in video captured by NASA’s exoplanet-hunting spacecraft
January 29, 2026
3 arrested after woman, daughter die from falling into open sewer line in Lahore – Dawn
January 29, 2026
Gold Demand Trends: Q4 and Full Year 2025
January 29, 2026
Global investors signal strong confidence in Pakistan: Khurram – RADIO PAKISTAN
January 29, 2026