Qaasid News
Download Our App
Latest News from Pakistan
Study: Late Ordovician Mass Extinction Cleared Way for First Fishes
January 12, 2026
CSS at Scale With StyleX
January 12, 2026
Recognizing Blood Clots in Unexpected Places
January 12, 2026
Tiny RNA molecules in sperm, big impact on baby health
January 12, 2026
CSULB art grads illustrate the storyboards that bring Hollywood blockbusters to life
January 12, 2026
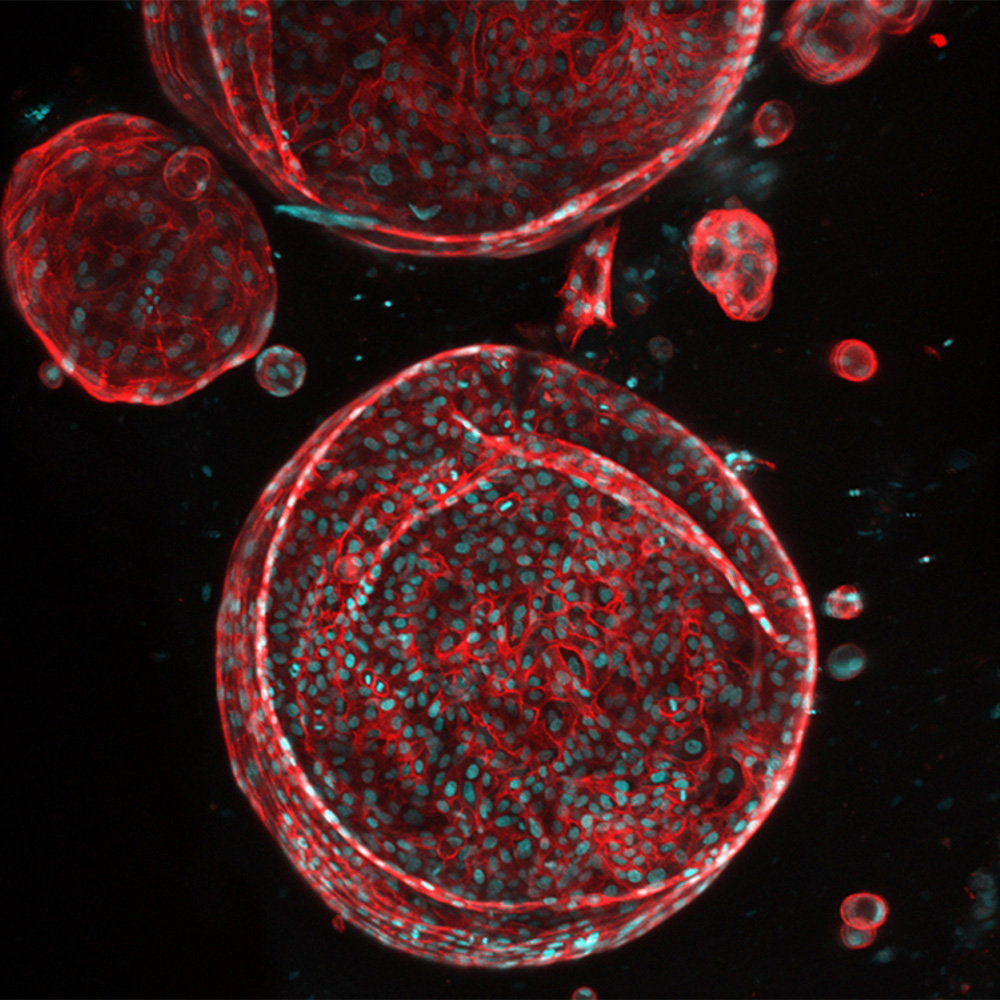
UTSW receives ARPA-H award to create functioning artificial liver: Newsroom
January 12, 2026
MTG Arena Announcements – January 12, 2026
January 12, 2026
Tiny Mars’ big impact on Earth’s climate | UCR News
January 12, 2026
Tributes paid to ‘extraordinary musician’
January 12, 2026
John Wallace: Tributes paid to 'extraordinary musician' – BBC
January 12, 2026