This study provides a comprehensive evaluation of the educational quality and medical accuracy of YouTube videos related to tonsillectomy, integrating human expert assessments with large language model (LLM)-based evaluations and transcript readability metrics. The findings highlight both the strengths and persistent challenges of using open-access digital platforms for disseminating patient education content.
Consistent with previous research, the overall quality of the videos included in this analysis was moderate. The mean DISCERN score (56.3 ± 8.7) aligns with findings from Vasan et al. (2024), Strychowsky et al. (2013), and Ward et al. (2020), all of whom reported that the majority of tonsillectomy-related content on YouTube fails to meet high standards of medical reliability ([6, 8, 9]) These consistent findings reinforce concerns regarding YouTube’s limited role as a dependable source of surgical information for the public, despite its widespread use and accessibility.
One of the most notable patterns in our analysis was the significantly lower quality of patient-generated content than videos produced by physicians, hospitals, or health associations. Both DISCERN and JAMA benchmark scores were significantly lower for patient videos—a trend that aligns with observations from prior studies. In particular, Selen et al. (2024) emphasized that videos produced by professional organizations consistently score higher in quality assessments [10]. While personal experience videos may provide emotional support and relatability, our findings corroborate those of Vasan et al. and Strychowsky et al., who caution that such narratives often lack critical clinical details and may deviate from evidence-based consensus practices [6, 8]. These results underscore the continued need for professional involvement in the creation of patient-facing health content.
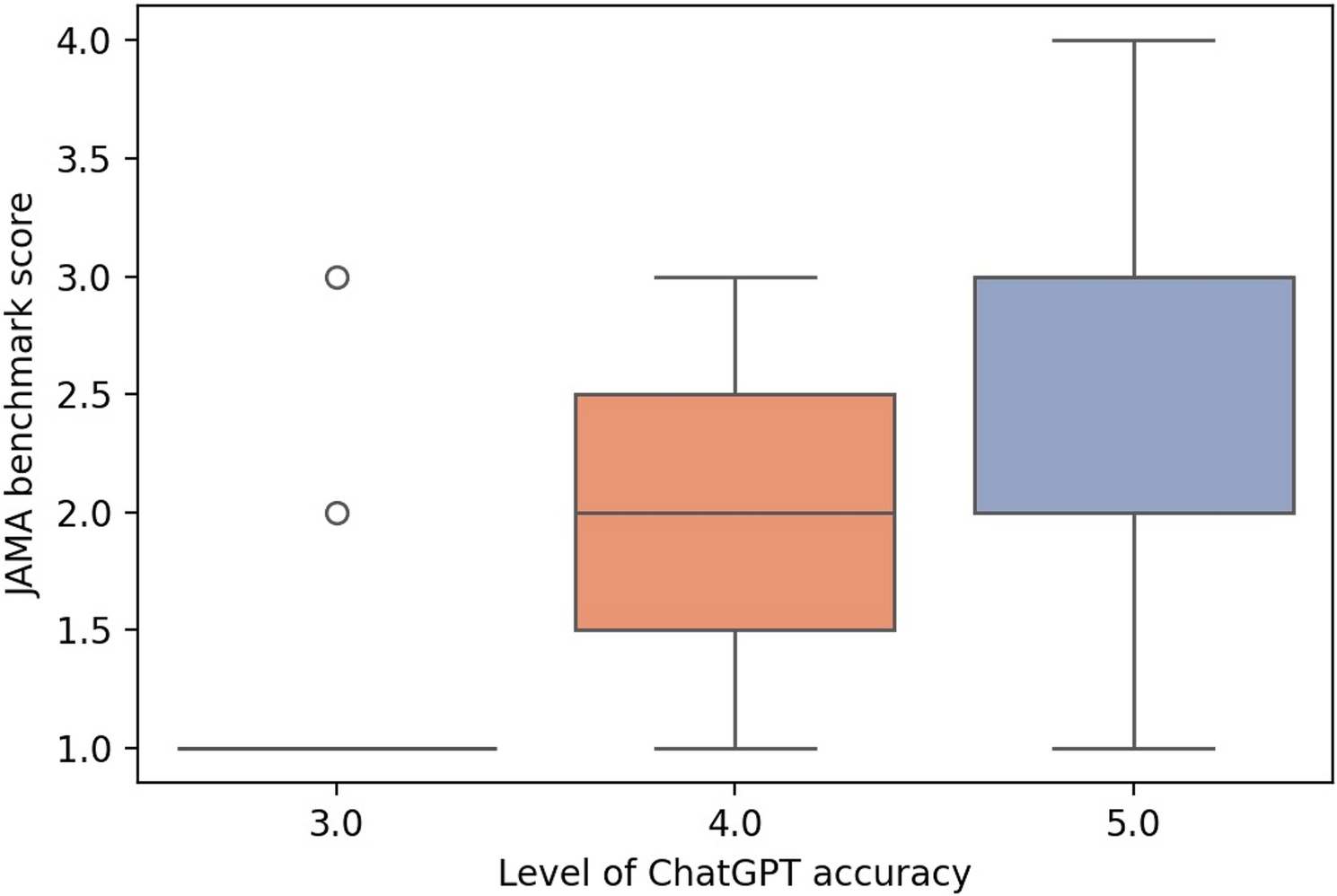
Our study also demonstrated a strong alignment between AI-generated evaluations and those of expert reviewers. Specifically, we found a moderate-to-strong correlation between the ChatGPT-4 accuracy scores and JAMA scores (ρ = 0.56, p < 0.001) and an even stronger correlation between the ChatGPT-4 completeness scores and DISCERN ratings (ρ = 0.72, p < 0.001). Furthermore, DISCERN scores significantly predicted ChatGPT-4 completeness ratings in a regression analysis (R² = 0.51, p < 0.001), highlighting the potential of ChatGPT-4 as a reliable tool for evaluating health information quality. While Demirci (2024) and Yüce et al. (2024) reported only moderate agreement between human raters and ChatGPT-4 models, citing issues such as low reproducibility and overestimation, our stronger correlations may reflect methodological enhancements, including manual transcript correction and the use of structured, task-specific prompts [11, 12]. On the other hand, our results align with those of Bal et al. (2024), who reported high concordance between ChatGPT-4 and expert classifications of language learning video content [13]. Taken together, these findings suggest that while ChatGPT-4 holds considerable promise in content evaluation, its performance may vary depending on the medical context and task.
In terms of linguistic accessibility, the average Flesch–Kincaid Grade Level (FKGL) of the video transcripts was 8.38, which is well above the recommended sixth-grade reading level for patient education materials. This aligns with prior reports indicating that even trusted sources such as MedlinePlus often exceed ideal readability thresholds [14]. Although readability metrics were not significantly correlated with DISCERN or JAMA scores, this finding raises concerns about the accessibility of video content for individuals with lower health literacy. Given that many viewers seeking tonsillectomy-related content may include parents of pediatric patients or individuals unfamiliar with medical terminology, an eighth-grade readability level may hinder comprehension and limit the practical usefulness of the information. Enhancing the clarity and simplicity of language used in video narration or captions could improve user understanding and engagement, especially in vulnerable populations. Future educational content should aim to align more closely with the recommended sixth-grade reading level to ensure broader accessibility.
This is one of the first studies to apply a multi-method framework combining human, AI, and readability analyses to assess the quality of tonsillectomy-related YouTube videos. Our inclusion of the ChatGPT-4 as an evaluative tool offers valuable insights into the evolving role of artificial intelligence in quality assurance for online health information. The strong correlations observed between human and AI ratings suggest that LLMs may serve as supportive prescreening tools for clinicians, educators, and platform moderators aiming to identify high-quality educational content at scale.
Practical significance and educational implications
While only ChatGPT-4 accuracy showed a statistically significant difference between transcript-heavy and visually-rich videos (Cohen’s d = 0.600, p = 0.030), this represents a large effect size with potential educational relevance. The 8% increase in AI-rated accuracy for visually enriched content highlights its value in enhancing comprehension—particularly for procedures like tonsillectomy that rely heavily on visual demonstration. This aligns with Mayer’s Cognitive Theory of Multimedia Learning, which posits that individuals learn more effectively when information is presented using both verbal and visual modalities [15]. Prior work in health communication also emphasizes the role of visual aids in improving understanding, recall, and engagement, especially among audiences with lower health literacy [16]. Given the consistently large effect sizes observed in correlations between AI-generated and expert ratings (ρ = 0.56–0.72), these findings support the use of LLM-based scoring tools for preliminary quality screening, provided their limitations are acknowledged.
However, it is important to note that ChatGPT-4 only assessed the textual transcripts, and the model had no access to the actual visual or auditory elements. Therefore, the observed accuracy gains in visually rich videos may reflect indirect improvements in transcript clarity or contextual grounding, rather than a direct effect of visual features. This suggests that visual enhancements may improve the way speakers articulate or structure information, which in turn benefits AI interpretation. Future studies using AI models capable of analyzing multimodal content are needed to verify this effect directly.
Limitations
Several limitations should be acknowledged. First, our analysis was restricted to English-language videos, which limits the generalizability of the findings to non-English-speaking audiences. Second, despite excellent inter-rater reliability, the subjective nature of human assessments cannot be eliminated. Third, as a cross-sectional study, our findings reflect a snapshot of the YouTube landscape between May and June 2025. Another limitation of this study is the inclusion of only English-language videos. This introduces selection bias and restricts the generalizability of the findings to English-speaking populations. Language and cultural context may significantly influence both the production and the perception of health education content, as communication styles, health beliefs, and literacy expectations can vary widely across regions. Future studies incorporating multilingual datasets and cross-cultural comparisons would be valuable to understand how video quality and accessibility differ across global audiences. Given the dynamic nature of online content and search algorithms, the results may vary over time. Additionally, ChatGPT-4 evaluated only transcripts; it cannot assess visual or auditory elements, which may influence the educational quality of a video. Previous work by Yüce et al. has also noted the model’s tendency to underperform when analyzing lengthy or complex video content and highlighted that video length itself may positively correlate with quality, an aspect not addressed in this study [12].
Future directions
Future research should explore strategies for producing engaging and medically accurate health videos that are both accessible and algorithmically visible. Studies evaluating the optimal design features—such as visuals, narration style, and interactivity—may help enhance the visibility, reach, and impact of such content. Continued development and fine-tuning of large language models (LLMs) for healthcare-specific evaluation tasks could further strengthen their reliability and utility. Additionally, future studies incorporating patient-reported feedback through surveys may provide valuable insights into the perceived usefulness and trustworthiness of online health content, thereby bridging the gap between objective quality metrics and real-world user experience. Longitudinal analyses are also warranted to monitor how the quality of medical videos evolves in response to platform changes and shifting public expectations.