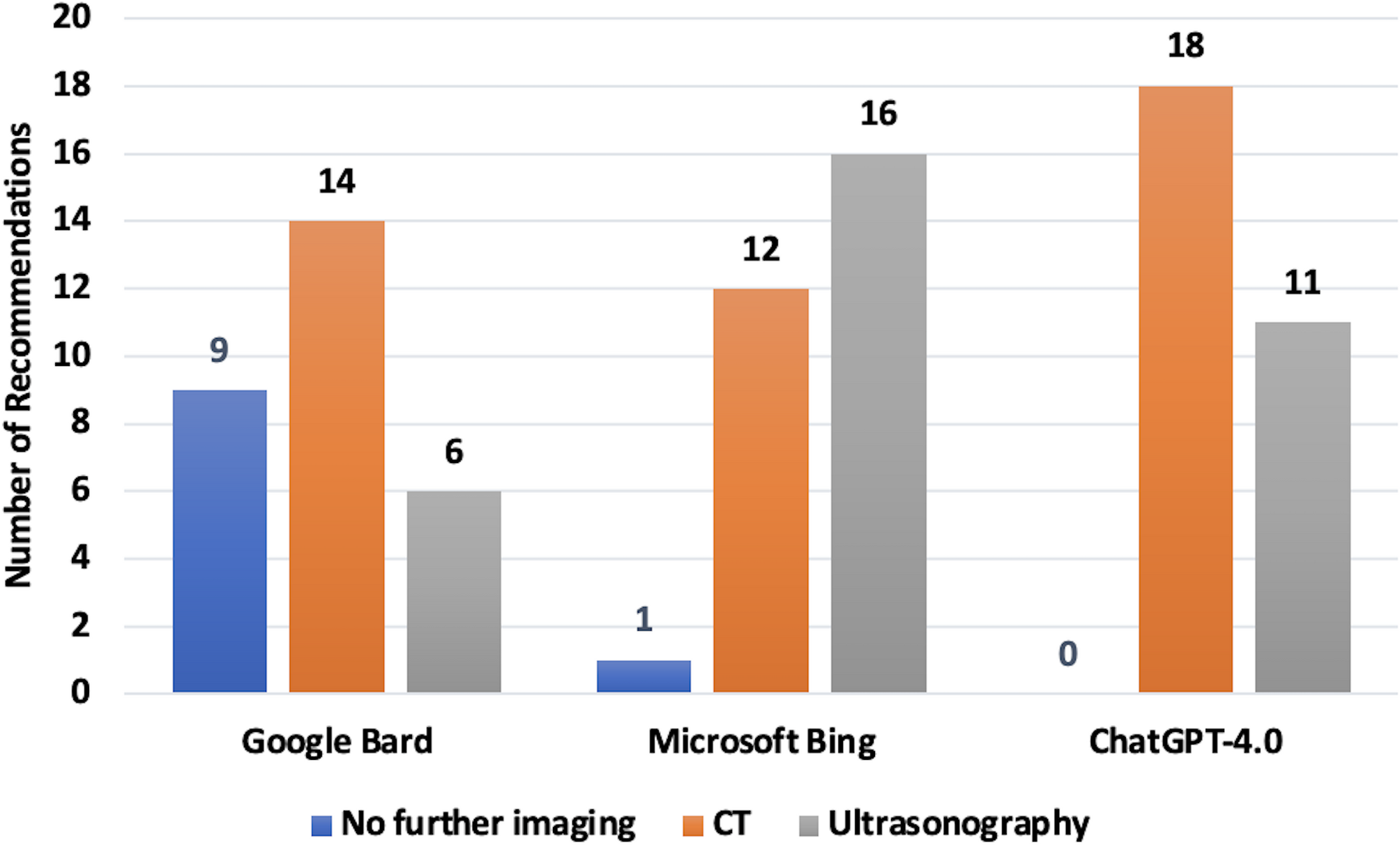
In our study, we evaluated the alignment of three LLMs– Gemini, Copilot, and ChatGPT-4.0– with consensus answers provided by a panel of experts. The findings indicate that Gemini consistently demonstrated a higher degree of agreement with the expert consensus compared to the other LLMs examined. Specifically, Gemini excelled in compatibility with both the majority of the consensus members’ answers and with the responses of any of the nine reviewers who participated in the consensus, regardless of majority opinion. Additionally, among the three commonly utilized LLMs, Gemini was the most aligned in queries where a perfect or excellent consensus was achieved.
The extent to which LLMs can be utilized in clinical decision-making processes remains a topic of growing interest. To shed light on this issue, several studies have been conducted—and continue to be conducted—comparing the performance of various LLMs [9,10,11,12]. In a study involving 134 clinical cases, the diagnostic, therapeutic, and management-related decision-making accuracy of three different LLMs was evaluated, and Gemini was found to have the lowest overall performance [9]. In another study focused on surgical planning in glaucoma patients, Gemini demonstrated 32% lower agreement compared to ChatGPT-4, indicating inferior performance [10]. Similarly, when assessed as an intraoperative decision-support tool in plastic surgery, Gemini again exhibited suboptimal performance relative to ChatGPT-4 [11]. Conversely, another study evaluating the ability of ChatGPT-4 and Gemini to assess diagnosis and treatment plans for patients with acute cholecystitis found comparable performances between the two models [12]. In contrast to these previous studies, our study found that, in the context of selecting the appropriate imaging modality for patients with renal colic, Gemini produced responses that were more aligned with those of the expert consensus panel.
One potential factor contributing to variability in LLM responses is the influence of different guideline sources used during model training. While our study utilized the 2019 consensus report [7] as the reference standard, it is possible that the UK NICE guidelines, which have recommended low-dose non-contrast CT as the first-line imaging modality since January 2019, were included in the training datasets of the evaluated LLMs. This difference in guideline exposure may have contributed to discrepancies in LLM recommendations.
However, this does not undermine the validity of our findings, as our study was specifically designed to assess how well LLMs align with an established expert consensus rather than to evaluate the absolute correctness of their responses based on multiple guideline sources. In clinical practice, variations in recommendations across different guidelines are well-recognized and do not indicate an inherent flaw in an individual guideline or its interpretation. Future research could further investigate how different LLMs integrate and prioritize diverse clinical guidelines, providing additional insights into their decision-making processes.
Gemini demonstrated a significantly higher level of concurrence with the consensus, providing responses that were largely similar to those of the majority of consensus participants. This suggests that Gemini may have better performance in understanding and appropriately interpreting clinical case examples consistent with expert opinions. In contrast, only 41.4% of the questions were answered by ChatGPT-4.0 and Copilot in agreement with the consensus, indicating a less robust alignment with expert guidelines. Notably, Gemini achieved an agreement rate of 82.7% when comparing its overall responses with those of the nine reviewers. These findings indicate that Gemini could be a more credible tool for applications requiring strong conformity with expert guidelines [7]. In addition, Gemini’s high rate of agreement with expert evaluations suggests that it may assist clinicians in making imaging decisions in patients with renal colic.The high level of agreement of the Gemini scale with the highest scoring responses suggests that it may have the potential for widespread adoption in professional and academic contexts if supported by future studies. In addition, Gemini and other LLMs can have more sensitive evaluation capabilities with each new update. With the use of more data sets and the development of more fine analysis capabilities with each new update, more accurate results can be achieved in the clinical context. Future studies can contribute to the increase of our knowledge and experience in this subject by focusing on how the reliability and accuracy rates of these LLMs, especially Gemini, can be improved with new updates.
Although the use of AI-enabled LLMs may attract attention with their performance in clinical case assessments, the integration of AI technologies into healthcare systems raises significant ethical and legal concerns that warrant careful consideration [13, 14]. As these complex models become increasingly embedded in critical clinical decision-making processes, it is crucial to meticulously assess the multifaceted risks and responsibilities associated with their potential impact on patient outcomes. A primary and pressing ethical issue pertains to the transparency and explainability of the decision-making mechanisms within AI systems. Healthcare providers must be able to comprehend and trust the recommendations and rationale generated by these AI systems in order to maintain patient confidence and ensure appropriate treatment. The lack of explainability can lead to profound challenges in establishing clear lines of accountability, making it profoundly difficult to determine whether the healthcare professional or the AI system bears responsibility for an erroneous or suboptimal decision that could significantly impact a patient’s well-being [15]. This adaptation is essential for safeguarding patient trust and ensuring that the integration of AI into healthcare supports, rather than undermines, the quality and reliability of patient care.
Another concern regarding the usability of LLMs in clinical case evaluations is the legal processes related to the compliance of the use of AI in healthcare with standards regarding patient privacy and data protection [16]. In Turkiye, the Law on the Protection of Personal Data (KVKK) imposes strict regulations on the management and disclosure of patient data [17]. Similarly, in the United States, the Health Insurance Portability and Accountability Act (HIPAA) sets stringent rules on patient data handling [18]. AI systems must be designed to comply with these requirements in both jurisdictions, ensuring the safeguarding of patient information against unauthorized access and breaches. This highlights the importance of ensuring that AI systems in healthcare settings are designed to comply with stringent data protection regulations—such as KVKK in Türkiye and HIPAA in the U.S.—to safeguard patient information from unauthorized access and breaches. Legally, the utilization of AI in healthcare must adhere to standards pertaining to patient confidentiality and data protection [16]. The Health Insurance Portability and Accountability Act in the United States imposes strict rules on the management and disclosure of patient data [17]. AI systems must be engineered to adhere to these requirements, guaranteeing the safeguarding of patient information against unauthorized access and breaches.
Limitations
This study has several limitations that should be considered when interpreting its findings. Firstly, the variability in the types and phrasing of questions posed to the LLMs can influence their responses, introducing variability that may affect the conclusions. However, the use of a standardized set of 29 clinical scenarios helps mitigate this variability, ensuring a consistent basis for comparison.
Secondly, the study’s generalizability is limited by the specific scenarios and questions presented. While the results may not apply to all medical inquiries, the selected scenarios are representative of common clinical situations in emergency departments. This relevance supports the applicability of the findings within the intended context. Thirdly, each vignette was presented only once in our study. Repetitive testing might increase the quality and robustness of the results of the study. Another limitation is that no power analysis was applied in our study. Instead, the study was designed using all vignettes in the consensus report. Finally, Copilot uses the infrastructure of ChatGPT-4.0. However, it also integrates the Microsoft database into its infrastructure, focusing on producing more balanced, creative and precise answers. Therefore, although they use similar infrastructures, they use different approaches to reach results on the given data, which distinguishes these two LLMs models from each other.
Despite these limitations, the study’s design and scenario selection provide a strong foundation for its conclusions. Future research can further address these limitations to enhance our understanding of LLMs in healthcare settings.