Scientists at Rothamsted Research have identified a natural defence mechanism in ancestral einkorn wheat that could lead to more sustainable pest management in modern agriculture.
Published in the Journal of Agricultural and Food…

Scientists at Rothamsted Research have identified a natural defence mechanism in ancestral einkorn wheat that could lead to more sustainable pest management in modern agriculture.
Published in the Journal of Agricultural and Food…

Compared with placebo, PCSK9 inhibition with evolocumab reduced the risk of first cardiovascular events among patients with atherosclerosis or…

EXCLUSIVE: Lionsgate scored its second biggest trailer launch in the studio’s history — in the same month, by the way — with its The Hunger Games: Sunrise on the Reaping teaser, which drew 109 million global views in its first 24 hours…

TL;DR: Skoove Premium lifetime access is on sale for just $99.97 (reg. $299.99), giving you unlimited, self-paced piano lessons built around the music you love — plus smart AI…

On a trip to Sweden this past summer, I tried to pop into the flagship atelier of Saman Amel, a Stockholm-based tailoring house founded in 2015. It was booked solid. Though the decade-old operation still feels like a menswear secret, its vision…

 SNS
SNSThe Tartan Army shook the earth as they celebrated Scotland’s men qualifying for a first World Cup in 28 years.
The British Geological Survey (BGS) recorded…
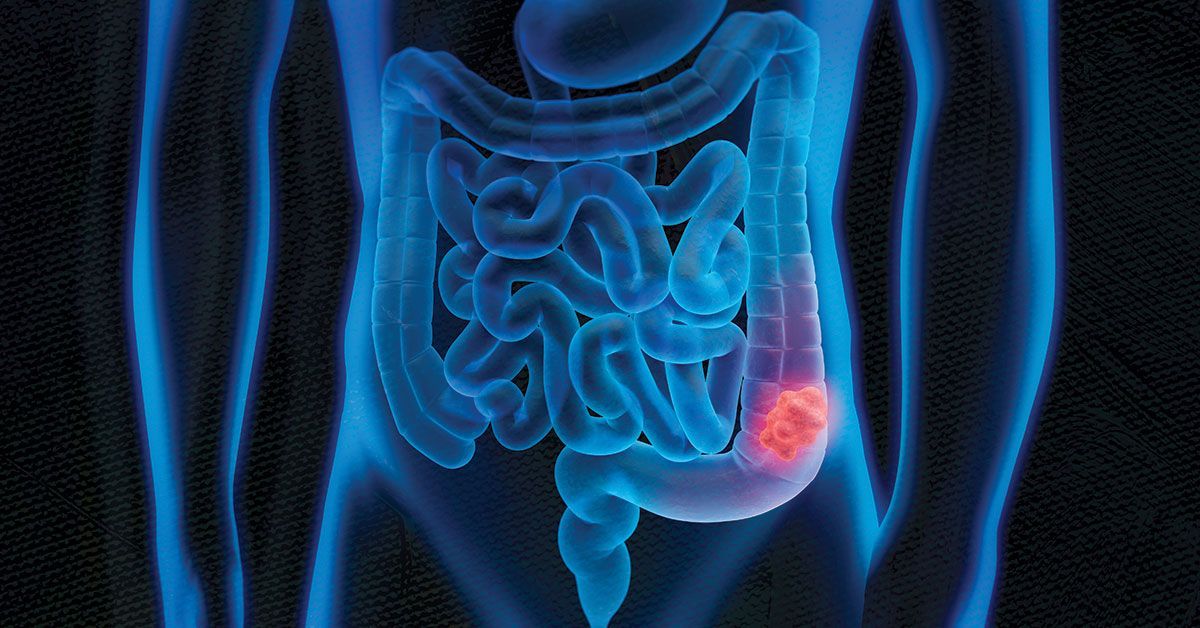
This story originally appeared in the winter 2025 issue of UC San Diego Magazine as “What’s Fueling Colorectal Cancer in Young Adults.”
In the past decade, as the rate of colorectal cancer…

A friend of mine recently asked me what the best AirPods were, and I told him the AirPods Pro 3. I said they had the best sound quality and noise canceling. When I spoke to him a few days later, I was surprised to hear that he’d bought the

Luke Littler won his first match as world number one to progress at the Players Championship Finals, while Gian van Veen produced a second stunning comeback victory against Luke Humphries in the space of a month.
Less than a month after upsetting…