
The Moon formed from a giant impact of the proto-Earth with the ancient protoplanet Theia. In a new study, a team of scientists from the United States, Germany, France and China measured iron isotopes in lunar samples, terrestrial rocks, and…
Author: admin
-

Chadwick Boseman’s widow reveals actor’s creative philosophy
At the Walk of Fame ceremony honoring her late husband on Thursday in Hollywood, Chadwick Boseman’s widow shared the underpinnings of the actor’s creative success.
Simone Ledward Boseman, who married him privately before his death on Aug….
Continue Reading
-
SEC SolarWinds Dismissal: Shifting Cyber Enforcement Risks
The outcome caps a long-running and closely watched legal dispute that began with sweeping fraud and controls allegations tied to SolarWinds’ statements about its cybersecurity practices and its disclosures following the breach of its flagship Orion software platform in 2020. The dismissal comes amid a broader recalibration of enforcement priorities in the new administration, including the SEC’s announcement earlier this year that it will focus on public issuer “fraudulent disclosure” relating to cybersecurity—signaling a pivot away from actions based on more nuanced allegations of disclosure deficiencies. The SEC’s decision to abandon the SolarWinds case altogether is the most pointed example yet of that shift.
The SEC’s dismissal may bring a sigh of relief to many companies and CISOs who were concerned about the chilling effect the case could have on the work of security teams to proactively identify vulnerabilities and gaps in cyber programs. However, public companies must still proceed carefully when making public statements about their security programs. In the wake of a cyber incident, any number of federal, state, or international regulators, as well as courts and litigants, may scrutinize and seize upon a company’s cybersecurity disclosures as evidence of negligence or worse. This includes the SEC, which, in late 2023, issued new requirements for companies to disclose material cyber risks and incidents to investors. Accordingly, effective governance around drafting and vetting cybersecurity statements and disclosures remains critical.
I. Dispute Background
The SolarWinds lawsuit arose out of the 2020 supply-chain attack, widely attributed to the Russian Foreign Intelligence Service, in which the threat actors inserted malicious code into an Orion software update, allowing potential access to thousands of SolarWinds customers. Prior to and after its 2018 IPO, SolarWinds had published a “Security Statement” on its website describing its cybersecurity practices, including its password policies, access controls, secure development lifecycle practices, and use of the NIST Cybersecurity Framework. SolarWinds had also disclosed to investors that its systems were “vulnerable” to threats from nation-state actors. Once it discovered the attack in December 2020, SolarWinds filed a Form 8-K with the SEC and publicly disclosed the incident while continuing its investigation and remediation efforts.
In October 2023, the SEC brought an enforcement action against SolarWinds and Brown in federal court, alleging the defendants defrauded investors by overstating SolarWinds’ cybersecurity practices and understating known risks. First, the amended complaint alleged SolarWinds and Brown violated the Securities Act and Exchange Act by making materially false and misleading statements in the company’s Security Statement posted on its website, in SEC registration statements, in press releases, blog posts, and podcasts. Second, the complaint alleged that SolarWinds violated reporting provisions by filing materially misleading cybersecurity risk disclosures in pre-incident public filings, and by issuing an incomplete December 2020 Form 8-K in which SolarWinds presented its understanding of the attack. Third, the SEC alleged that SolarWinds failed to devise and maintain adequate internal accounting controls under Section 13(b)(2)(B) of the Exchange Act, and it further alleged that Brown aided and abetted these violations. Finally, the agency claimed SolarWinds violated the requirements under Rule 13a-15(a) to maintain proper disclosure controls and procedures to escalate incidents to management. This case marked the first time the SEC brought a cybersecurity enforcement action against an individual CISO, and the first time it asserted accounting control claims based on technical cybersecurity failings.
II. 2024 Partial Dismissal
On July 18, 2024, U.S. District Judge Paul A. Engelmayer of the Southern District of New York issued a 107 page opinion dismissing most of the SEC’s claims. The court rejected the claims alleging false and misleading statements made in press releases, blog posts, and podcasts, finding them to be only “non-actionable corporate puffery.” It also rejected the allegations concerning the post-incident disclosures, emphasizing that they must be read in context of an unfolding investigation and that the SEC’s arguments relied on the benefit of hindsight. The court dismissed the SEC’s novel internal accounting controls claims, holding that such controls are about assuring the integrity of the company’s financial transactions, not detecting or preventing cybersecurity deficiencies in source code or network environments. Finally, the court dismissed the Rule 13a 15(a) disclosure controls claim, finding that the existence of two misclassified incidents did not amount to “systemic deficiencies” in SolarWinds’ disclosure controls and procedures.
The only claims that were allowed to proceed concerned the representations in the website Security Statement about access controls and password protection policies. The court drew a line between “corporate puffery” and actionable statements and held that the Security Statement was publicly accessible and part of the “total mix of information” SolarWinds provided to the public, and that the SEC sufficiently pled SolarWinds’ practices materially diverged from its statements.
III. 2025 Summary Judgment Proceedings
Following the court’s 2024 ruling, SolarWinds and Brown moved for summary judgment in April 2025. Signaling another shift in SolarWinds’ favor, the SEC acknowledged in a Joint Statement of Undisputed Facts that, during the relevant period, SolarWinds did implement practices described in its Security Statement, including use of the NIST Cybersecurity Framework; role based access provisioning; enforcement of password complexity; and secure development lifecycle measures such as vulnerability testing, regression testing, penetration testing, and product security assessments.
IV. 2025 Settlement and Final Dismissal
On July 2, 2025, prior to any ruling on summary judgment, the SEC, SolarWinds, and Brown jointly notified Judge Engelmayer that they had reached a settlement in principle. The court stayed proceedings to allow the parties to finalize the settlement paperwork. The anticipated settlement, however, did not materialize. Instead, on November 20, 2025, the parties filed a Joint Stipulation to Dismiss, in which the SEC agreed to dismiss the remaining claims against SolarWinds and Brown with prejudice without any settlement conditions (other than a waiver of potential claims against the SEC and the United States arising from the litigation).
V. The Next Chapter: What to Take Away from SolarWinds
The dismissal indicates a shift in the SEC’s enforcement approach—one that narrows, but does not eliminate, risk for public companies. For now, it appears the Commission is moving toward a “back to basics” approach, focusing on egregious misstatements and material misrepresentations resulting in investor harm. Even as the SEC refocuses on more traditional fraud theories, companies remain exposed to liability and scrutiny across multiple fronts, including expanding and disparate regulatory regimes, as well as private litigation that mines public statements and incident reporting for inconsistencies or omissions.
1. Regulatory and litigation risk remains high
While the SEC may pare back enforcement, this does not mean that other regulators will follow suit. Sector-specific regulators and state regulators, for example, have been increasingly active in cyber enforcement and may fill the void. Global companies also face a growing array of international regulators that scrutinize cyber incidents with data privacy, critical infrastructure, and operational resilience impacts.
In addition to regulatory enforcement, private litigation remains active. Securities class actions are common following high profile cyber incidents, particularly when public disclosures are contested. Indeed, plaintiffs’ firms are quick to file derivative suits alleging oversight failures and consumer class actions under consumer protection laws are frequent when cyber incidents are made public.
Of course, courts and regulators evaluate these issues case by case. The record in SolarWinds turned on specific facts, many of which ended up more favorable to SolarWinds following discovery than the SEC had initially alleged. And while Judge Engelmayer agreed with several of SolarWinds’ key arguments related to its conduct and statements at issue, that is not to say that another court would reach the same outcome. One or two slightly different takes on the statements or actions that were in question could have swung the pendulum in the opposite direction.
Regardless of the outcome in this case, companies should continue to concentrate on the quality and accuracy of cybersecurity disclosures, the robustness of governance and controls supporting those disclosures, and the documentation that demonstrates reasonable, risk aligned practices. In particular, companies should ensure incident materiality determinations are well documented, cross channel communications are consistent, and governance processes tie public statements to verified technical facts.
2. Securities disclosure requirements have expanded
The disclosures at issue in SolarWinds took place before the SEC adopted its new rule on Cybersecurity Risk Management, Strategy, Governance, and Incident Disclosure by Public Companies (the “Cyber Rules”). Since December 2023, the Cyber Rules have imposed new requirements for timely Form 8 K reporting of material incidents and added detailed requirements for disclosures of cyber risk management and governance in annual reports. Companies should be diligent in ensuring that their disclosures and public statements made today are in line with what the company has put into place. Even if the SEC declines to bring an enforcement action based on alleged disclosure deficiencies where there is no investor harm, the new triggering requirements and the expanded disclosures under the Cyber Rules heighten the risk that those statements, or the failure to make those statements, will be used against companies by private litigants and other regulators.
3. Executives are not off the hook.
The SolarWinds case raised concerns that CISOs could be subject to a low bar for personal liability. With the dismissal, companies may wonder whether individual executive exposure for cyber failures remains a serious risk. While the threshold for individual CISO enforcement risk may now be higher in the securities context, senior leaders may still be targeted in cases involving alleged misrepresentations, negligence, or failures in oversight that result in consumer or market harm.
Indeed, the expectation environment for CISOs and other senior leaders continues to intensify. Regulators increasingly expect sophisticated boards and executive teams to focus not only on the existence of cybersecurity programs, but on their specificity, execution quality, and alignment with risk standards. This includes probing “ground truth” technical measures like vulnerability management, identity and access controls, incident response readiness, logging and monitoring sufficiency, and third party risk management—and assessing whether responsible individuals exercised appropriate oversight.
In short, while one case may reduce immediate headline risk, it may not meaningfully change the direction of the broader legal and regulatory landscape. Executives with cybersecurity oversight should continue to assume heightened scrutiny, ensure governance around risk prioritization and resourcing, and demonstrate reasonableness regarding technical controls and external statements.
4. Enforcement will vary by impact.
SEC enforcement is certainly not one-size-fits-all. Even given the SEC’s refocused priorities, enforcement could vary across companies and sectors. Factors such as inherent cyber risk, size, sophistication, and market impact may influence enforcement. Sectors that are more likely to suffer or inflict greater impact from significant operational disruptions, such as financial institutions, providers of pervasive technology services, or critical infrastructure, may be scrutinized more heavily. In other words, the greater the potential harm to shareholders or the market generally, the greater SEC scrutiny the company is likely to face.
5. Enforcement priorities could shift again.
Agency priorities often change from administration to administration, and the pendulum could swing back again. Companies should assume that shifts in enforcement emphasis are temporary and continue to anchor cyber governance in well-supported risk management practices that can withstand regulatory and judicial scrutiny.
VI. Final Takeaway
The SEC’s decision to dismiss its remaining claims against SolarWinds reflects a narrowing of one enforcement path but still leaves intact significant exposure possibilities, including more traditional securities actions, parallel regulatory regimes, and private litigation. The most durable mitigation is disciplined governance: aligning public statements with verified technical reality, document materiality and incident response judgments, and sustain reasonable, risk based controls. Those steps remain the foundation for withstanding scrutiny from investors, courts, and regulators—regardless of shifting enforcement cycles.
Continue Reading
-

Wealth management firms to pay $25.5 million to settle employees’ class action
WASHINGTON, Nov 21 (Reuters) – A group of major asset and wealth management firms has agreed to pay $25.5 million to resolve claims in U.S. court that they conspired to restrict job mobility and suppress wages for thousands of financial professionals.
Lawyers for the employees on Thursday asked a federal judge in Kansas to grant final approval of the settlement.Sign up here.
The nationwide accord covers more than 4,400 current and former employees who worked for companies including Mariner Wealth Advisors and American Century Companies between 2012 and 2020. The plaintiffs sued last year , alleging the companies violated antitrust law by agreeing not to recruit or hire each other’s workers.American Century and another defendant, Montage Investments, previously reached non-prosecution agreements with the U.S. Justice Department over related allegations, according to the filing.
In a statement, American Century said it was pleased to resolve the workers’ lawsuit in Kansas and “remains committed to fair and honest competition in compliance with all laws and regulations.”
A lawyer for Mariner Wealth and Montage did not immediately respond to a request for comment, and neither did lead attorneys for the plaintiffs.
The asset and wealth management firms denied any wrongdoing.
The plaintiffs said the Mariner defendants have about $65.9 billion in assets under management and the American Century defendants manage about $230 billion in assets.
The plaintiffs said the settlement offers significant and immediate relief and avoids the risk and costs of continuing litigation.
Settlement payments will be based on factors including length of employment, the court papers showed.
Lawyers for the plaintiffs estimated an average payout of about $3,700 per person. Eligible employees will receive payments automatically.
The settlement also said the plaintiffs’ lawyers will ask for up to one-third of the fund for legal fees, or about $8.5 million.
The case is Jakob Tobler et al v. 1248 Holdings LLC, U.S. District Court for the District of Kansas, No. 2:24-cv-02068-EFM-GEB.
For plaintiffs: George Hanson of Stueve Siegel Hanson, and Rowdy Meeks of Rowdy Meeks Legal Group
For Mariner: Jonathan King of DLA Piper
For American Century: John Schmidtlein of Williams & Connolly
Read more:
US naval shipbuilders seek Supreme Court review in engineers’ pay caseUS judge approves pizza chain Papa John’s ‘no poach’ antitrust settlementUS poultry producers sued by growers over hiring and payPharmacy residents accuse US hospitals of wage-fixing in new lawsuitReporting by Mike Scarcella
Our Standards: The Thomson Reuters Trust Principles.
Continue Reading
-
Bloomberg Hot Pursuit: Bentley Unveils New Supersports – Bloomberg.com
- Bloomberg Hot Pursuit: Bentley Unveils New Supersports Bloomberg.com
- How Bentley Turned A Fat Grand Tourer Into A Blue-Blooded Supercar CarBuzz
- Bentley Unveils Lighter, More Focused Continental GT Supersports for 2027 Yahoo! Autos
- Lightweight…
Continue Reading
-
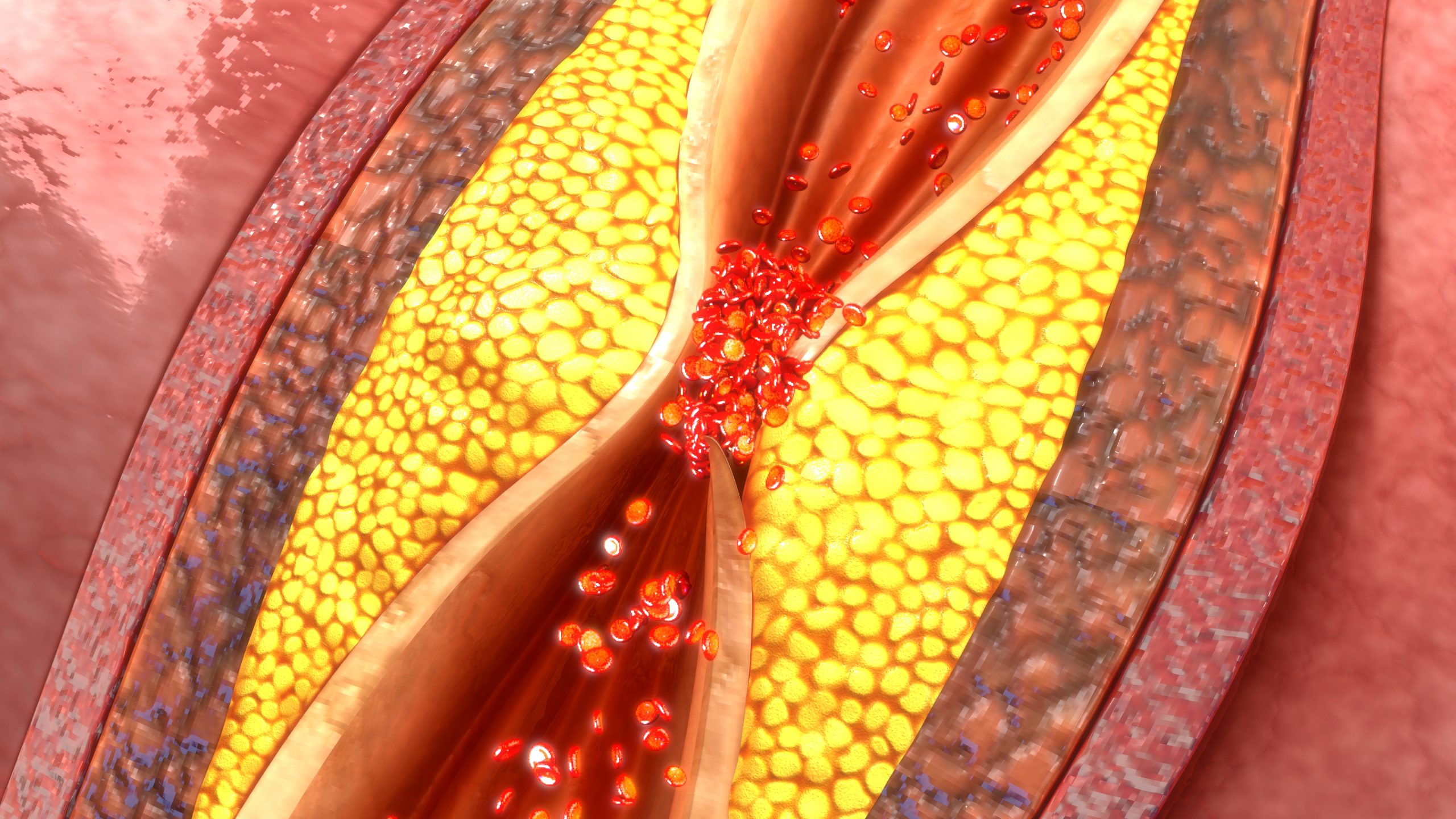
CAR T Cell Therapy for Coronary Artery Disease Shows Early Success
Credit: 7activestudio / Getty Images Researchers at the Perelman School of Medicine at the University of Pennsylvania have developed an experimental chimeric antigen receptor regulatory T cell (CAR Treg) to target…
Continue Reading
-

China controls this key resource AI needs – threatening stocks and the U.S. economy
By Kristina Hooper
AI relies on rare-earth elements to grow its infrastructure – and the U.S. relies on AI to grow GDP
Capital spending on AI has been a key driver of U.S. stock market returns and continues to exceed expectations, comprising a large portion of S&P 500 SPX capital expenditures.
Jason Furman, a Harvard University economics professor, calculated that 92% of total U.S. GDP growth for the first half of 2025 could be attributed to AI spending. Without AI-related data-center construction, he reported, GDP growth would have been an anemic 0.1% on an annualized basis.
Given so much riding on the AI capex boom, it’s important to consider what could derail U.S. economic growth and the U.S. stock market
One major risk is access to rare earth elements. Limited rare-earth access could present the U.S. with challenges similar to what it faced in the 1970s from its dependence on oil.
Rare-earth elements are used extensively in artificial intelligence, including disk drives, cooling servers and especially semiconductor fabrication. Artificial intelligence has enormous computational and memory demands, which is why high-capacity, high-performance semiconductors are the linchpin of the AI build-out. Rare earths are also integral for national security – used in radar, lasers and satellite systems.
From the 1960s to the 1990s, the U.S. was the leader in rare-earth elements production. In 1995, two decisions were made that had far-ranging consequences, dramatically changing the trajectory of U.S. leadership in rare earth elements.
First, the U.S. approved China’s purchase of U.S. rare-earth magnet company Magnequench from General Motors, thereby acquiring a highly advanced technology that arguably would have taken many years to develop.
Second, China applied to join the World Trade Organization, ultimately enabling it to sell its rare-earth elements to a global market. China was able to sell at a lower cost than the U.S., contributing to the closure of the U.S. mining company that produced rare earth elements, MP Materials Corp. (MP), in 2002.
MP Materials was reopened for national defense use in 2017. U.S. production has since ramped up, with rare-earth production reaching 45,000 tons in 2024 – yet that’s still less than one-sixth of China’s production.
Yet the U.S. Department of Defense’s lofty goal of meeting defense-related demand for light- and heavy rare earths by 2027 may not be achieved, given America’s rare-earth mining and processing limitations. Even if it is, significant commercial demand, including the enormous AI build-out, will not be met.
China controls the supply
China controls around 70% of the world’s rare earth resource output and about 90% of the world’s rare earth processing capabilities. Access to rare-earth elements has been a key bargaining chip in U.S. trade negotiations with China.
As a result, the U.S. has been increasing efforts to diversify its rare-earths supply and gain reliable and adequate exposure to these elements through its allies. Australia and Canada, for instance, have significant rare-earth resources that can help support America’s rare-earth element needs.
New technologies may also lessen or eliminate the need for rare-earth elements in various uses and make rare-earth element recycling more efficient (currently, just 1% of rare-earth elements are recycled). In addition, U.S. government policies can discourage or at least disincentivize demand for rare earth element-intensive products such as electric vehicles, as the Trump administration has done by eliminating EV tax credits.
Rare earth element independence should be as high a priority for the U.S. as energy independence was 50 years ago. Until there’s a viable alternative to the China-dominated rare-earth supply chain, AI capital spending – and both the U.S. economy and stock market – are vulnerable. Accordingly, stock investors should pay attention to trade deals and policymakers’ comments, and consider supply-chain risks when evaluating AI-related investments.
Kristina Hooper is chief market strategist at Man Group, which manages alternative investments. The opinions expressed are her own.
More: Big Tech is spending on power for AI – whether Washington functions or not
Also read: AI has real problems. The smart money is investing in the companies solving them now.
-Kristina Hooper
This content was created by MarketWatch, which is operated by Dow Jones & Co. MarketWatch is published independently from Dow Jones Newswires and The Wall Street Journal.
(END) Dow Jones Newswires
11-21-25 1619ET
Copyright (c) 2025 Dow Jones & Company, Inc.
Continue Reading
-

Kristen Bell, Brian Cox Surprised Fox Podcast Uses 2010 Audio
Kristen Bell and Brian Cox were among a string of actors who were recently announced to be voicing Biblical figures in Fox News Audio’s The Life of Jesus Podcast, though they were unaware prior to Wednesday’s announcement of the podcast…
Continue Reading
-
FDA Approves KEYTRUDA® (pembrolizumab) and KEYTRUDA QLEX™ (pembrolizumab and berahyaluronidase alfa-pmph), Each with Padcev® (enfortumab vedotin-ejfv), as Perioperative Treatment for Adults with Cisplatin-Ineligible Muscle-Invasive Bladder Cancer
Represents the first PD-1 inhibitor plus ADC regimens for this patient population
RAHWAY, N.J.–(BUSINESS WIRE)–
Merck (NYSE: MRK), known as MSD outside of the United States and Canada, today announced that the U.S. Food and Drug Administration (FDA) has approved KEYTRUDA® (pembrolizumab) and KEYTRUDA QLEX™ (pembrolizumab and berahyaluronidase alfa-pmph) in combination with Padcev® (enfortumab vedotin-ejfv), as neoadjuvant treatment and then continued after cystectomy as adjuvant treatment, for the treatment of adult patients with muscle-invasive bladder cancer (MIBC) who are ineligible for cisplatin-based chemotherapy. These approvals represent the first PD-1 inhibitor plus ADC regimens for this patient population.These approvals are based on data from the Phase 3 KEYNOTE-905 trial (also known as EV-303), which was conducted in collaboration with Pfizer and Astellas. Results, which were presented at the recent European Society for Medical Oncology (ESMO) Congress, showed that after a median follow-up of 25.6 months, KEYTRUDA plus Padcev, as perioperative treatment, demonstrated a statistically significant 60% reduction in the risk of event-free survival (EFS) events versus surgery alone in patients with MIBC who are not eligible for or declined cisplatin-based chemotherapy (HR=0.40 [95% CI, 0.28-0.57]; p<0.0001; 48/170 [28%] versus 95/174 [55%]; median EFS not reached [NR] [95% CI, 37.3-NR] versus 15.7 months [95% CI, 10.3-20.5]). KEYTRUDA plus Padcev also demonstrated a statistically significant 50% improvement in overall survival (OS) versus surgery alone (HR=0.50 [95% CI, 0.33-0.74]; p=0.0002; 38/170 [22%] versus 68/174 [39%]; median OS NR [95% CI, NR-NR] vs 41.7 [95% CI, 31.8-NR]). The trial demonstrated a statistically significant difference in pathologic complete response (pCR) rate (57.1% [95% CI: 49.3, 64.6] vs. 8.6% [95% CI: 4.9, 13.8]; p<0.0001). The effectiveness of KEYTRUDA QLEX for its approved indications has been established based upon evidence from the adequate and well-controlled studies conducted with KEYTRUDA and additional data from MK-3475A-D77 comparing the pharmacokinetic, efficacy, and safety profiles of KEYTRUDA QLEX and KEYTRUDA.
KEYTRUDA QLEX is contraindicated in patients with known hypersensitivity to berahyaluronidase alfa, hyaluronidase or to any of its excipients. Immune-mediated adverse reactions, which may be severe or fatal, can occur in any organ system or tissue and can affect more than one body system simultaneously. Immune-mediated adverse reactions can occur at any time during or after treatment with KEYTRUDA or KEYTRUDA QLEX, including pneumonitis, colitis, hepatitis, endocrinopathies, nephritis, dermatologic reactions, solid organ transplant rejection, other transplant (including corneal graft) rejection. Additionally, fatal and other serious complications can occur in patients who receive allogenic hematopoietic stem cell transplantation (HSCT) before or after treatment. Consider the benefit vs risks for these patients. Treatment of patients with multiple myeloma with a PD-1/PD-L1-blocking antibody in combination with a thalidomide analogue plus dexamethasone is not recommended outside of controlled trials due to the potential for increased mortality. Important immune-mediated adverse reactions listed here may not include all possible severe and fatal immune-mediated adverse reactions. Early identification and management of immune-mediated adverse reactions are essential to ensure safe use of KEYTRUDA or KEYTRUDA QLEX. Based on the severity of the adverse reaction, KEYTRUDA and KEYTRUDA QLEX should be withheld or permanently discontinued and corticosteroids administered if appropriate. KEYTRUDA and KEYTRUDA QLEX can also cause severe or life-threatening infusion-related reactions. Based on their mechanism of action, KEYTRUDA and KEYTRUDA QLEX can each cause fetal harm when administered to a pregnant woman. For more information, see “Selected Important Safety Information” below.
“Pembrolizumab plus enfortumab vedotin is poised to address a critical unmet need,” said Dr. Matthew Galsky, Lillian and Howard Stratton Professor of Medicine, Director of Genitourinary Medical Oncology, Mount Sinai Tisch Cancer Center, and KEYNOTE-905 study investigator. “Half of patients with MIBC may experience cancer recurrence even after having their bladder removed, and many of these patients are ineligible to receive cisplatin. These approvals, based on striking event-free and overall survival benefits, may represent an important practice-changing advance for these patients who’ve had no new options in decades.”
“Our company’s ongoing commitment to putting patients at the center of finding new innovations in cancer care has made the introduction of these new options a reality for patients who are truly in need,” said Dr. Marjorie Green, senior vice president and head of oncology, global clinical development, Merck Research Laboratories. “Moreover, we are honored to provide these patients who previously had only one option — surgery — with a choice to receive their immunotherapy either intravenously or subcutaneously.”
Study design and additional data supporting the approval
KEYNOTE-905, also known as EV-303, is an open-label, randomized, multi-arm, controlled Phase 3 trial (ClinicalTrials.gov, NCT03924895) evaluating perioperative KEYTRUDA, with or without Padcev, versus surgery alone in patients with MIBC who are either not eligible for or declined cisplatin-based chemotherapy. The trial enrolled 344 patients who were randomized 1:1 to receive either:
- Neoadjuvant KEYTRUDA 200 mg over 30 minutes as an intravenous infusion on Day 1 and enfortumab vedotin 1.25 mg/kg as an intravenous infusion on Days 1 and 8 of each 21 day cycle for 3 cycles prior to surgery, followed by adjuvant KEYTRUDA 200 mg over 30 minutes on Day 1 of each 21 day cycle for 14 cycles and adjuvant enfortumab vedotin 1.25 mg/kg on Days 1 and 8 of each 21 day cycle for 6 cycles (n=170).
- Immediate radical cystectomy (RC) and pelvic lymph node dissection (PLND) alone (n=174).
Treatment continued until completion of study medications, disease progression, not undergoing or refusal of RC and PLND, disease recurrence in the adjuvant phase, or unacceptable toxicity. Assessment of tumor status, including CT/MRI, was performed at baseline, within 5 weeks prior to RC and PLND, and at 6 weeks post radical cystectomy. Following RC and PLND, assessment of tumor status, including cystoscopy and urine cytology for patients who did not undergo surgery, was performed every 12 weeks up to 2 years, and every 24 weeks thereafter.
A total of 149 (88%) patients in the KEYTRUDA in combination with enfortumab vedotin arm and 156 (90%) patients in the RC and PLND alone arm underwent RC and PLND.
The trial was not designed to isolate the effect of KEYTRUDA in each phase (neoadjuvant or adjuvant) of treatment.
The major efficacy outcome measure of this trial was EFS defined as the time from randomization to the first of: disease progression preventing curative surgery, failure to undergo surgery for participants with muscle invasive residual disease, incomplete surgical resection, local or distant recurrence after surgery, or death. OS and pCR rate as assessed by blinded independent pathology review were additional efficacy outcome measures.
For the 167 patients who received KEYTRUDA in the neoadjuvant phase, the median duration of exposure to KEYTRUDA 200 mg every 3 weeks was 1.4 months (range: 1 day to 2.7 months) and the median number of cycles of KEYTRUDA was 3 (range: 1 to 3) out of the planned 3 cycles in the neoadjuvant phase. For the 96 patients who received KEYTRUDA in the adjuvant phase, the median duration of exposure to KEYTRUDA 200 mg every 3 weeks was 8.5 months (range: 1 day to 12.9 months) and the median number of cycles of KEYTRUDA was 12 (range: 1 to 14) out of the planned 14 cycles in the adjuvant phase. Across the combined neoadjuvant and adjuvant phases (n=167), the median number of cycles of KEYTRUDA was 5 (range: 1, 17) out of the planned 17 cycles.
In KEYNOTE-905, the most common adverse reactions (≥20%) occurring in cisplatin-ineligible patients with MIBC treated with KEYTRUDA in combination with enfortumab vedotin (n =167) were rash (54%), pruritus (47%), fatigue (47%), peripheral neuropathy (39%), alopecia (35%), dysgeusia (35%), diarrhea (34%), constipation (28%), decreased appetite (28%), nausea (26%), urinary tract infection (24%), dry eye (21%), and weight loss (20%).
In the neoadjuvant phase of KEYNOTE-905, serious adverse reactions occurred in 27% (n=167) of patients; the most frequent (≥2%) were urinary tract infection (3.6%) and hematuria (2.4%). Fatal adverse reactions occurred in 1.2% of patients, including myasthenia gravis and toxic epidermal necrolysis (0.6% each). Additional fatal adverse reactions were reported in 2.7% of patients in the post-surgery phase before adjuvant treatment started, including sepsis and intestinal obstruction (1.4% each). Permanent discontinuation of KEYTRUDA due to an adverse reaction occurred in 15% of patients; the most frequent (>1%) were rash (2.4%, including generalized exfoliative dermatitis), increased alanine aminotransferase, increased aspartate aminotransferase, diarrhea, dysgeusia, and toxic epidermal necrolysis (1.2% each). Of the 167 patients in the KEYTRUDA in combination with enfortumab vedotin arm who received neoadjuvant treatment, 7 (4.2%) patients did not receive surgery due to adverse reactions. The adverse reactions that led to cancellation of surgery were acute myocardial infarction, bile duct cancer, colon cancer, respiratory distress, urinary tract infection, and two deaths due to myasthenia gravis and toxic epidermal necrolysis (0.6% each).
Of the 146 patients who received neoadjuvant treatment with KEYTRUDA in combination with enfortumab vedotin and underwent radical cystectomy, 6 (4.1%) patients experienced delay of surgery (defined as time from last neoadjuvant treatment to surgery exceeding 8 weeks) due to adverse reactions.
In the adjuvant phase of KEYNOTE-905, serious adverse reactions occurred in 43% (n=100); the most frequent (≥2%) were urinary tract infection (8%); acute kidney injury and pyelonephritis (5% each); urosepsis (4%); and hypokalemia, intestinal obstruction, and sepsis (2% each). Fatal adverse reactions occurred in 7% of patients, including urosepsis, intracranial hemorrhage, death, myocardial infarction, multiple organ dysfunction syndrome, and pseudomonal pneumonia (1% each). Permanent discontinuation of KEYTRUDA due to an adverse reaction occurred in 28% of patients; the most frequent (>1%) were diarrhea (5%), peripheral neuropathy, acute kidney injury, and pneumonitis (2% each).
About KEYTRUDA® (pembrolizumab) injection, 100 mg
KEYTRUDA is an anti-programmed death receptor-1 (PD-1) therapy that works by increasing the ability of the body’s immune system to help detect and fight tumor cells. KEYTRUDA is a humanized monoclonal antibody that blocks the interaction between PD-1 and its ligands, PD- L1 and PD-L2, thereby activating T lymphocytes which may affect both tumor cells and healthy cells.
Merck has the industry’s largest immuno-oncology clinical research program. There are currently more than 1,600 trials studying KEYTRUDA across a wide variety of cancers and treatment settings. The KEYTRUDA clinical program seeks to understand the role of KEYTRUDA across cancers and the factors that may predict a patient’s likelihood of benefitting from treatment with KEYTRUDA, including exploring several different biomarkers.
About KEYTRUDA QLEX™ (pembrolizumab and berahyaluronidase alfa-pmph) injection for subcutaneous use
KEYTRUDA QLEX is a fixed-combination drug product of pembrolizumab and berahyaluronidase alfa. Pembrolizumab is a programmed death receptor-1 (PD-1) blocking antibody and berahyaluronidase alfa enhances dispersion and permeability to enable subcutaneous administration of pembrolizumab. KEYTRUDA QLEX is administered as a subcutaneous injection into the thigh or abdomen, avoiding the 5 cm area around the navel, over one minute every three weeks (2.4 mL) or over two minutes every six weeks (4.8 mL).
Selected KEYTRUDA® (pembrolizumab) and KEYTRUDA QLEX™ (pembrolizumab and berahyaluronidase alfa-pmph) Indications in the U.S.
Urothelial Cancer
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with enfortumab vedotin, for the treatment of adult patients with locally advanced or metastatic urothelial cancer.
KEYTRUDA and KEYTRUDA QLEX, as single agents, are each indicated for the treatment of adult patients with locally advanced or metastatic urothelial carcinoma:
- who are not eligible for any platinum-containing chemotherapy, or
- who have disease progression during or following platinum-containing chemotherapy or within 12 months of neoadjuvant or adjuvant treatment with platinum-containing chemotherapy.
KEYTRUDA and KEYTRUDA QLEX in combination with enfortumab vedotin, as neoadjuvant treatment and then continued after cystectomy as adjuvant treatment, are each indicated for the treatment of adult patients with muscle invasive bladder cancer (MIBC) who are ineligible for cisplatin-containing chemotherapy.
KEYTRUDA and KEYTRUDA QLEX, as single agents, are each indicated for the treatment of adult patients with Bacillus Calmette-Guerin (BCG)-unresponsive, high-risk, non-muscle invasive bladder cancer (NMIBC) with carcinoma in situ (CIS) with or without papillary tumors who are ineligible for or have elected not to undergo cystectomy.
See additional selected KEYTRUDA and KEYTRUDA QLEX indications in the U.S. after the Selected Important Safety Information.
Selected Important Safety Information for KEYTRUDA and KEYTRUDA QLEX
Contraindications
KEYTRUDA QLEX is contraindicated in patients with known hypersensitivity to berahyaluronidase alfa, hyaluronidase or to any of its excipients.
Severe and Fatal Immune-Mediated Adverse Reactions
KEYTRUDA and KEYTRUDA QLEX are monoclonal antibodies that belong to a class of drugs that bind to either the programmed death receptor-1 (PD-1) or the programmed death ligand 1 (PD-L1), blocking the PD-1/PD-L1 pathway, thereby removing inhibition of the immune response, potentially breaking peripheral tolerance and inducing immune-mediated adverse reactions. Immune-mediated adverse reactions, which may be severe or fatal, can occur in any organ system or tissue, can affect more than one body system simultaneously, and can occur at any time after starting treatment or after discontinuation of treatment. Important immune-mediated adverse reactions listed here may not include all possible severe and fatal immune-mediated adverse reactions.
Monitor patients closely for symptoms and signs that may be clinical manifestations of underlying immune-mediated adverse reactions. Early identification and management are essential to ensure safe use of anti–PD-1/PD-L1 treatments. Evaluate liver enzymes, creatinine, and thyroid function at baseline and periodically during treatment. For patients with TNBC treated with KEYTRUDA or KEYTRUDA QLEX in the neoadjuvant setting, monitor blood cortisol at baseline, prior to surgery, and as clinically indicated. In cases of suspected immune-mediated adverse reactions, initiate appropriate workup to exclude alternative etiologies, including infection. Institute medical management promptly, including specialty consultation as appropriate.
Withhold or permanently discontinue KEYTRUDA and KEYTRUDA QLEX depending on severity of the immune-mediated adverse reaction. In general, if KEYTRUDA and KEYTRUDA QLEX require interruption or discontinuation, administer systemic corticosteroid therapy (1 to 2 mg/kg/day prednisone or equivalent) until improvement to Grade 1 or less. Upon improvement to Grade 1 or less, initiate corticosteroid taper and continue to taper over at least 1 month. Consider administration of other systemic immunosuppressants in patients whose adverse reactions are not controlled with corticosteroid therapy.
Immune-Mediated Pneumonitis
KEYTRUDA and KEYTRUDA QLEX can cause immune-mediated pneumonitis. The incidence is higher in patients who have received prior thoracic radiation. Immune-mediated pneumonitis occurred in 3.4% (94/2799) of patients receiving KEYTRUDA, including fatal (0.1%), Grade 4 (0.3%), Grade 3 (0.9%), and Grade 2 (1.3%) reactions. Systemic corticosteroids were required in 67% (63/94) of patients. Pneumonitis led to permanent discontinuation of KEYTRUDA in 1.3% (36) and withholding in 0.9% (26) of patients. All patients who were withheld reinitiated KEYTRUDA after symptom improvement; of these, 23% had recurrence. Pneumonitis resolved in 59% of the 94 patients. Immune-mediated pneumonitis occurred in 5% (13/251) of patients receiving KEYTRUDA QLEX in combination with chemotherapy, including fatal (0.4%), Grade 3 (2%), and Grade 2 (1.2%) adverse reactions.
Pneumonitis occurred in 7% (41/580) of adult patients with resected NSCLC who received KEYTRUDA as a single agent for adjuvant treatment of NSCLC, including fatal (0.2%), Grade 4 (0.3%), and Grade 3 (1%) adverse reactions. Patients received high-dose corticosteroids for a median duration of 10 days (range: 1 day to 2.3 months). Pneumonitis led to discontinuation of KEYTRUDA in 26 (4.5%) of patients. Of the patients who developed pneumonitis, 54% interrupted KEYTRUDA, 63% discontinued KEYTRUDA, and 71% had resolution.
Immune-Mediated Colitis
KEYTRUDA and KEYTRUDA QLEX can cause immune-mediated colitis, which may present with diarrhea. Cytomegalovirus infection/reactivation has been reported in patients with corticosteroid-refractory immune-mediated colitis. In cases of corticosteroid-refractory colitis, consider repeating infectious workup to exclude alternative etiologies.
Immune-mediated colitis occurred in 1.7% (48/2799) of patients receiving KEYTRUDA, including Grade 4 (<0.1%), Grade 3 (1.1%), and Grade 2 (0.4%) reactions. Systemic corticosteroids were required in 69% (33/48); additional immunosuppressant therapy was required in 4.2% of patients. Colitis led to permanent discontinuation of KEYTRUDA in 0.5% (15) and withholding in 0.5% (13) of patients. All patients who were withheld reinitiated KEYTRUDA after symptom improvement; of these, 23% had recurrence. Colitis resolved in 85% of the 48 patients. Immune-mediated colitis occurred in 1.2% (3/251) of patients receiving KEYTRUDA QLEX in combination with chemotherapy, including Grade 3 (0.8%) and Grade 2 (0.4%) adverse reactions.
Hepatotoxicity and Immune-Mediated Hepatitis
KEYTRUDA and KEYTRUDA QLEX can cause immune-mediated hepatitis. Immune-mediated hepatitis occurred in 0.7% (19/2799) of patients receiving KEYTRUDA, including Grade 4 (<0.1%), Grade 3 (0.4%), and Grade 2 (0.1%) reactions. Systemic corticosteroids were required in 68% (13/19) of patients; additional immunosuppressant therapy was required in 11% of patients. Hepatitis led to permanent discontinuation of KEYTRUDA in 0.2% (6) and withholding in 0.3% (9) of patients. All patients who were withheld reinitiated KEYTRUDA after symptom improvement; of these, none had recurrence. Hepatitis resolved in 79% of the 19 patients. Immune-mediated hepatitis occurred in 0.4% (1/251) of patients receiving KEYTRUDA QLEX in combination with chemotherapy, including Grade 2 (0.4%) adverse reactions.
KEYTRUDA With Axitinib or KEYTRUDA QLEX With Axitinib
KEYTRUDA and KEYTRUDA QLEX, when either is used in combination with axitinib, can cause hepatic toxicity. Monitor liver enzymes before initiation of and periodically throughout treatment. Consider monitoring more frequently as compared to when the drugs are administered as single agents. For elevated liver enzymes, interrupt KEYTRUDA and axitinib or KEYTRUDA QLEX and axitinib, and consider administering corticosteroids as needed.
With the combination of KEYTRUDA and axitinib, Grades 3 and 4 increased alanine aminotransferase (ALT) (20%) and increased aspartate aminotransferase (AST) (13%) were seen at a higher frequency compared to KEYTRUDA alone. Fifty-nine percent of the patients with increased ALT received systemic corticosteroids. In patients with ALT ≥3 times upper limit of normal (ULN) (Grades 2-4, n=116), ALT resolved to Grades 0-1 in 94%. Among the 92 patients who were rechallenged with either KEYTRUDA (n=3) or axitinib (n=34) administered as a single agent or with both (n=55), recurrence of ALT ≥3 times ULN was observed in 1 patient receiving KEYTRUDA, 16 patients receiving axitinib, and 24 patients receiving both. All patients with a recurrence of ALT ≥3 ULN subsequently recovered from the event.
Immune-Mediated Endocrinopathies
Adrenal Insufficiency
KEYTRUDA and KEYTRUDA QLEX can cause primary or secondary adrenal insufficiency. For Grade 2 or higher, initiate symptomatic treatment, including hormone replacement as clinically indicated. Withhold KEYTRUDA and KEYTRUDA QLEX depending on severity. Adrenal insufficiency occurred in 0.8% (22/2799) of patients receiving KEYTRUDA, including Grade 4 (<0.1%), Grade 3 (0.3%), and Grade 2 (0.3%) reactions. Systemic corticosteroids were required in 77% (17/22) of patients; of these, the majority remained on systemic corticosteroids. Adrenal insufficiency led to permanent discontinuation of KEYTRUDA in <0.1% (1) and withholding in 0.3% (8) of patients. All patients who were withheld reinitiated KEYTRUDA after symptom improvement. Adrenal insufficiency occurred in 2% (5/251) of patients receiving KEYTRUDA QLEX in combination with chemotherapy, including Grade 3 (0.4%) and Grade 2 (0.8%) adverse reactions.
Hypophysitis
KEYTRUDA and KEYTRUDA QLEX can cause immune-mediated hypophysitis. Hypophysitis can present with acute symptoms associated with mass effect such as headache, photophobia, or visual field defects. Hypophysitis can cause hypopituitarism. Initiate hormone replacement as indicated. Withhold or permanently discontinue KEYTRUDA and KEYTRUDA QLEX depending on severity. Hypophysitis occurred in 0.6% (17/2799) of patients receiving KEYTRUDA,
including Grade 4 (<0.1%), Grade 3 (0.3%), and Grade 2 (0.2%) reactions. Systemic corticosteroids were required in 94% (16/17) of patients; of these, the majority remained on systemic corticosteroids. Hypophysitis led to permanent discontinuation of KEYTRUDA in 0.1% (4) and withholding in 0.3% (7) of patients. All patients who were withheld reinitiated KEYTRUDA after symptom improvement.
Thyroid Disorders
KEYTRUDA and KEYTRUDA QLEX can cause immune-mediated thyroid disorders. Thyroiditis can present with or without endocrinopathy. Hypothyroidism can follow hyperthyroidism. Initiate hormone replacement for hypothyroidism or institute medical management of hyperthyroidism as clinically indicated. Withhold or permanently discontinue KEYTRUDA and KEYTRUDA QLEX depending on severity.
Thyroiditis occurred in 0.6% (16/2799) of patients receiving KEYTRUDA, including Grade 2 (0.3%). None discontinued, but KEYTRUDA was withheld in <0.1% (1) of patients.
Hyperthyroidism occurred in 3.4% (96/2799) of patients receiving KEYTRUDA, including Grade 3 (0.1%) and Grade 2 (0.8%). It led to permanent discontinuation of KEYTRUDA in <0.1% (2) and withholding in 0.3% (7) of patients. All patients who were withheld reinitiated KEYTRUDA after symptom improvement. Hypothyroidism occurred in 8% (237/2799) of patients receiving KEYTRUDA, including Grade 3 (0.1%) and Grade 2 (6.2%). It led to permanent discontinuation of KEYTRUDA in <0.1% (1) and withholding in 0.5% (14) of patients. All patients who were withheld reinitiated KEYTRUDA after symptom improvement. The majority of patients with hypothyroidism required long-term thyroid hormone replacement. The incidence of new or worsening hypothyroidism was higher in 1185 patients with HNSCC, occurring in 16% of patients receiving KEYTRUDA as a single agent or in combination with platinum and FU, including Grade 3 (0.3%) hypothyroidism. The incidence of new or worsening hyperthyroidism was higher in 580 patients with resected NSCLC, occurring in 11% of patients receiving KEYTRUDA as a single agent as adjuvant treatment, including Grade 3 (0.2%) hyperthyroidism. The incidence of new or worsening hypothyroidism was higher in 580 patients with resected NSCLC, occurring in 22% of patients receiving KEYTRUDA as a single agent as adjuvant treatment (KEYNOTE-091), including Grade 3 (0.3%) hypothyroidism.
Thyroiditis occurred in 0.4% (1/251) of patients receiving KEYTRUDA QLEX in combination with chemotherapy, including Grade 2 (0.4%). Hyperthyroidism occurred in 8% (20/251) of patients receiving KEYTRUDA QLEX in combination with chemotherapy, including Grade 2 (3.2%). Hypothyroidism occurred in 14% (35/251) of patients receiving KEYTRUDA QLEX in combination with chemotherapy, including Grade 2 (11%).
Type 1 Diabetes Mellitus (DM), Which Can Present With Diabetic Ketoacidosis
Monitor patients for hyperglycemia or other signs and symptoms of diabetes. Initiate treatment with insulin as clinically indicated. Withhold KEYTRUDA and KEYTRUDA QLEX depending on severity. Type 1 DM occurred in 0.2% (6/2799) of patients receiving KEYTRUDA. It led to permanent discontinuation in <0.1% (1) and withholding of KEYTRUDA in <0.1% (1) of patients. All patients who were withheld reinitiated KEYTRUDA after symptom improvement. Type 1 DM occurred in 0.4% (1/251) of patients receiving KEYTRUDA QLEX in combination with chemotherapy.
Immune-Mediated Nephritis With Renal Dysfunction
KEYTRUDA and KEYTRUDA QLEX can cause immune-mediated nephritis.
Immune-mediated nephritis occurred in 0.3% (9/2799) of patients receiving KEYTRUDA, including Grade 4 (<0.1%), Grade 3 (0.1%), and Grade 2 (0.1%) reactions. Systemic corticosteroids were required in 89% (8/9) of patients. Nephritis led to permanent discontinuation of KEYTRUDA in 0.1% (3) and withholding in 0.1% (3) of patients. All patients who were withheld reinitiated KEYTRUDA after symptom improvement; of these, none had recurrence. Nephritis resolved in 56% of the 9 patients.
Immune-Mediated Dermatologic Adverse Reactions
KEYTRUDA and KEYTRUDA QLEX can cause immune-mediated rash or dermatitis. Exfoliative dermatitis, including Stevens-Johnson syndrome, drug rash with eosinophilia and systemic symptoms, and toxic epidermal necrolysis, has occurred with anti–PD-1/PD-L1 treatments. Topical emollients and/or topical corticosteroids may be adequate to treat mild to moderate nonexfoliative rashes. Withhold or permanently discontinue KEYTRUDA and KEYTRUDA QLEX depending on severity.
Immune-mediated dermatologic adverse reactions occurred in 1.4% (38/2799) of patients receiving KEYTRUDA, including Grade 3 (1%) and Grade 2 (0.1%) reactions. Systemic corticosteroids were required in 40% (15/38) of patients. These reactions led to permanent discontinuation in 0.1% (2) and withholding of KEYTRUDA in 0.6% (16) of patients. All patients who were withheld reinitiated KEYTRUDA after symptom improvement; of these, 6% had recurrence. The reactions resolved in 79% of the 38 patients. Immune-mediated dermatologic adverse reactions occurred in 1.6% (4/251) of patients receiving KEYTRUDA QLEX in combination with chemotherapy, including Grade 4 (0.8%) and Grade 3 (0.8%) adverse reactions.
Other Immune-Mediated Adverse Reactions
The following clinically significant immune-mediated adverse reactions occurred at an incidence of <1% (unless otherwise noted) in patients who received KEYTRUDA, KEYTRUDA QLEX, or were reported with the use of other anti–PD-1/PD-L1 treatments. Severe or fatal cases have been reported for some of these adverse reactions. Cardiac/Vascular: Myocarditis, pericarditis, vasculitis; Nervous System: Meningitis, encephalitis, myelitis and demyelination, myasthenic syndrome/myasthenia gravis (including exacerbation), Guillain-Barré syndrome, nerve paresis, autoimmune neuropathy; Ocular: Uveitis, iritis and other ocular inflammatory toxicities can occur. Some cases can be associated with retinal detachment. Various grades of visual impairment, including blindness, can occur. If uveitis occurs in combination with other immune-mediated adverse reactions, consider a Vogt-Koyanagi-Harada-like syndrome, as this may require treatment with systemic steroids to reduce the risk of permanent vision loss; Gastrointestinal: Pancreatitis, to include increases in serum amylase and lipase levels, gastritis (2.8%), duodenitis; Musculoskeletal and Connective Tissue: Myositis/polymyositis, rhabdomyolysis (and associated sequelae, including renal failure), arthritis (1.5%), polymyalgia rheumatica; Endocrine: Hypoparathyroidism; Hematologic/Immune: Hemolytic anemia, aplastic anemia, hemophagocytic lymphohistiocytosis, systemic inflammatory response syndrome, histiocytic necrotizing lymphadenitis (Kikuchi lymphadenitis), sarcoidosis, immune thrombocytopenic purpura, solid organ transplant rejection, other transplant (including corneal graft) rejection.
Hypersensitivity and Infusion- or Administration-Related Reactions
KEYTRUDA and KEYTRUDA QLEX can cause severe or life-threatening administration-related reactions, including hypersensitivity and anaphylaxis. With KEYTRUDA and KEYTRUDA QLEX, monitor for signs and symptoms of infusion- and administration-related systemic reactions including rigors, chills, wheezing, pruritus, flushing, rash, hypotension, hypoxemia, and fever. Infusion-related reactions have been reported in 0.2% of 2799 patients receiving KEYTRUDA. Interrupt or slow the rate of infusion for Grade 1 or Grade 2 reactions. For Grade 3 or Grade 4 reactions, stop infusion and permanently discontinue KEYTRUDA. Hypersensitivity and administration related systemic reactions occurred in 3.2% (8/251) of patients receiving KEYTRUDA QLEX in combination with platinum doublet chemotherapy, including Grade 2 (2.8%). Interrupt injection (if not already fully administered) and resume if symptoms resolve for mild or moderate systemic reactions. For severe or life-threatening systemic reactions, stop injection and permanently discontinue KEYTRUDA QLEX.
Complications of Allogeneic Hematopoietic Stem Cell Transplantation (HSCT)
Fatal and other serious complications can occur in patients who receive allogeneic HSCT before or after anti–PD-1/PD-L1 treatments. Transplant-related complications include hyperacute graft-versus-host disease (GVHD), acute and chronic GVHD, hepatic veno-occlusive disease after reduced intensity conditioning, and steroid-requiring febrile syndrome (without an identified infectious cause). These complications may occur despite intervening therapy between anti–PD-1/PD-L1 treatments and allogeneic HSCT. Follow patients closely for evidence of these complications and intervene promptly. Consider the benefit vs risks of using anti–PD-1/PD-L1 treatments prior to or after an allogeneic HSCT.
Increased Mortality in Patients With Multiple Myeloma
In trials in patients with multiple myeloma, the addition of KEYTRUDA to a thalidomide analogue plus dexamethasone resulted in increased mortality. Treatment of these patients with an anti–PD-1/PD-L1 treatment in this combination is not recommended outside of controlled trials.
Embryofetal Toxicity
Based on their mechanism of action, KEYTRUDA and KEYTRUDA QLEX can each cause fetal harm when administered to a pregnant woman. Advise women of this potential risk. In females of reproductive potential, verify pregnancy status prior to initiating KEYTRUDA or KEYTRUDA QLEX and advise them to use effective contraception during treatment and for 4 months after the last dose.
Adverse Reactions
In study MK-3475A-D77, when KEYTRUDA QLEX was administered with chemotherapy in metastatic non–small cell lung cancer (NSCLC), serious adverse reactions occurred in 39% of patients. Serious adverse reactions in ≥1% of patients who received KEYTRUDA QLEX were pneumonia (10%), thrombocytopenia (4%), febrile neutropenia (4%), neutropenia (2.8%), musculoskeletal pain (2%), pneumonitis (2%), diarrhea (1.6%), rash (1.2%), respiratory failure (1.2%), and anemia (1.2%). Fatal adverse reactions occurred in 10% of patients including pneumonia (3.2%), neutropenic sepsis (2%), death not otherwise specified (1.6%), respiratory failure (1.2%), parotitis (0.4%), pneumonitis (0.4%), pneumothorax (0.4%), pulmonary embolism (0.4%), neutropenic colitis (0.4%), and seizure (0.4%). KEYTRUDA QLEX was permanently discontinued due to an adverse reaction in 16% of 251 patients. Adverse reactions which resulted in permanent discontinuation of KEYTRUDA QLEX in ≥2% of patients included pneumonia and pneumonitis. Dosage interruptions of KEYTRUDA QLEX due to an adverse reaction occurred in 45% of patients. Adverse reactions which required dosage interruption in ≥2% of patients included neutropenia, anemia, thrombocytopenia, pneumonia, rash, and increased aspartate aminotransferase. The most common adverse reactions (≥20%) were nausea (25%), fatigue (25%), and musculoskeletal pain (21%).
In KEYNOTE-006, KEYTRUDA was discontinued due to adverse reactions in 9% of 555 patients with advanced melanoma; adverse reactions leading to permanent discontinuation in more than one patient were colitis (1.4%), autoimmune hepatitis (0.7%), allergic reaction (0.4%), polyneuropathy (0.4%), and cardiac failure (0.4%). The most common adverse reactions (≥20%) with KEYTRUDA were fatigue (28%), diarrhea (26%), rash (24%), and nausea (21%).
In KEYNOTE-054, when KEYTRUDA was administered as a single agent to patients with stage III melanoma, KEYTRUDA was permanently discontinued due to adverse reactions in 14% of 509 patients; the most common (≥1%) were pneumonitis (1.4%), colitis (1.2%), and diarrhea (1%). Serious adverse reactions occurred in 25% of patients receiving KEYTRUDA. The most common adverse reaction (≥20%) with KEYTRUDA was diarrhea (28%).
In KEYNOTE-716, when KEYTRUDA was administered as a single agent to patients with stage IIB or IIC melanoma, adverse reactions occurring in patients with stage IIB or IIC melanoma were similar to those occurring in 1011 patients with stage III melanoma from KEYNOTE-054.
In KEYNOTE-189, when KEYTRUDA was administered with pemetrexed and platinum chemotherapy in metastatic nonsquamous NSCLC, KEYTRUDA was discontinued due to adverse reactions in 20% of 405 patients. The most common adverse reactions resulting in permanent discontinuation of KEYTRUDA were pneumonitis (3%) and acute kidney injury (2%). The most common adverse reactions (≥20%) with KEYTRUDA were nausea (56%), fatigue (56%), constipation (35%), diarrhea (31%), decreased appetite (28%), rash (25%), vomiting (24%), cough (21%), dyspnea (21%), and pyrexia (20%).
In KEYNOTE-407, when KEYTRUDA was administered with carboplatin and either paclitaxel or paclitaxel protein-bound in metastatic squamous NSCLC, KEYTRUDA was discontinued due to adverse reactions in 15% of 101 patients. The most frequent serious adverse reactions reported in at least 2% of patients were febrile neutropenia, pneumonia, and urinary tract infection. Adverse reactions observed in KEYNOTE-407 were similar to those observed in KEYNOTE-189 with the exception that increased incidences of alopecia (47% vs 36%) and peripheral neuropathy (31% vs 25%) were observed in the KEYTRUDA and chemotherapy arm compared to the placebo and chemotherapy arm in KEYNOTE-407.
In KEYNOTE-042, KEYTRUDA was discontinued due to adverse reactions in 19% of 636 patients with advanced NSCLC; the most common were pneumonitis (3%), death due to unknown cause (1.6%), and pneumonia (1.4%). The most frequent serious adverse reactions reported in at least 2% of patients were pneumonia (7%), pneumonitis (3.9%), pulmonary embolism (2.4%), and pleural effusion (2.2%). The most common adverse reaction (≥20%) was fatigue (25%).
In KEYNOTE-010, KEYTRUDA monotherapy was discontinued due to adverse reactions in 8% of 682 patients with metastatic NSCLC; the most common was pneumonitis (1.8%). The most common adverse reactions (≥20%) were decreased appetite (25%), fatigue (25%), dyspnea (23%), and nausea (20%).
In KEYNOTE-671, adverse reactions occurring in patients with resectable NSCLC receiving KEYTRUDA in combination with platinum-containing chemotherapy, given as neoadjuvant treatment and continued as single-agent adjuvant treatment, were generally similar to those occurring in patients in other clinical trials across tumor types receiving KEYTRUDA in combination with chemotherapy.
The most common adverse reactions (reported in ≥20%) in patients receiving KEYTRUDA in combination with chemotherapy or chemoradiotherapy were fatigue/asthenia, nausea, constipation, diarrhea, decreased appetite, rash, vomiting, cough, dyspnea, pyrexia, alopecia, peripheral neuropathy, mucosal inflammation, stomatitis, headache, weight loss, abdominal pain, arthralgia, myalgia, insomnia, palmar-plantar erythrodysesthesia, urinary tract infection, and hypothyroidism, radiation skin injury, dysphagia, dry mouth, and musculoskeletal pain.
In the neoadjuvant phase of KEYNOTE-671, when KEYTRUDA was administered in combination with platinum-containing chemotherapy as neoadjuvant treatment, serious adverse reactions occurred in 34% of 396 patients. The most frequent (≥2%) serious adverse reactions were pneumonia (4.8%), venous thromboembolism (3.3%), and anemia (2%). Fatal adverse reactions occurred in 1.3% of patients, including death due to unknown cause (0.8%), sepsis (0.3%), and immune-mediated lung disease (0.3%). Permanent discontinuation of any study drug due to an adverse reaction occurred in 18% of patients who received KEYTRUDA in combination with platinum-containing chemotherapy; the most frequent adverse reactions (≥1%) that led to permanent discontinuation of any study drug were acute kidney injury (1.8%), interstitial lung disease (1.8%), anemia (1.5%), neutropenia (1.5%), and pneumonia (1.3%).
Of the KEYTRUDA-treated patients who received neoadjuvant treatment, 6% of 396 patients did not receive surgery due to adverse reactions. The most frequent (≥1%) adverse reaction that led to cancellation of surgery in the KEYTRUDA arm was interstitial lung disease (1%).
In the adjuvant phase of KEYNOTE-671, when KEYTRUDA was administered as a single agent as adjuvant treatment, serious adverse reactions occurred in 14% of 290 patients. The most frequent serious adverse reaction was pneumonia (3.4%). One fatal adverse reaction of pulmonary hemorrhage occurred. Permanent discontinuation of KEYTRUDA due to an adverse reaction occurred in 12% of patients who received KEYTRUDA as a single agent, given as adjuvant treatment; the most frequent adverse reactions (≥1%) that led to permanent discontinuation of KEYTRUDA were diarrhea (1.7%), interstitial lung disease (1.4%), increased aspartate aminotransferase (1%), and musculoskeletal pain (1%).
Adverse reactions observed in KEYNOTE-091 were generally similar to those occurring in other patients with NSCLC receiving KEYTRUDA as a single agent, with the exception of hypothyroidism (22%), hyperthyroidism (11%), and pneumonitis (7%). Two fatal adverse reactions of myocarditis occurred.
Adverse reactions observed in KEYNOTE-483 were generally similar to those occurring in other patients receiving KEYTRUDA in combination with pemetrexed and platinum chemotherapy.
In KEYNOTE-689, the most common adverse reactions (≥20%) in patients receiving KEYTRUDA were stomatitis (48%), radiation skin injury (40%), weight loss (36%), fatigue (33%), dysphagia (29%), constipation (27%), hypothyroidism (26%), nausea (24%), rash (22%), dry mouth (22%), diarrhea (22%), and musculoskeletal pain (22%).
In the neoadjuvant phase of KEYNOTE-689, of the 361 patients who received at least one dose of single agent KEYTRUDA, 11% experienced serious adverse reactions. Serious adverse reactions that occurred in more than one patient were pneumonia (1.4%), tumor hemorrhage (0.8%), dysphagia (0.6%), immune-mediated hepatitis (0.6%), cellulitis (0.6%), and dyspnea (0.6%). Fatal adverse reactions occurred in 1.1% of patients, including respiratory failure, clostridium infection, septic shock, and myocardial infarction (one patient each). Permanent discontinuation of KEYTRUDA due to an adverse reaction occurred in 2.8% of patients who received KEYTRUDA as neoadjuvant treatment. The most frequent adverse reaction which resulted in permanent discontinuation of neoadjuvant KEYTRUDA in more than one patient was arthralgia (0.6%).
Of the 361 patients who received KEYTRUDA as neoadjuvant treatment, 11% did not receive surgery. Surgical cancellation on the KEYTRUDA arm was due to disease progression in 4%, patient decision in 3%, adverse reactions in 1.4%, physician’s decision in 1.1%, unresectable tumor in 0.6%, loss of follow-up in 0.3%, and use of non-study anti-cancer therapy in 0.3%.
Of the 323 KEYTRUDA-treated patients who received surgery following the neoadjuvant phase, 1.2% experienced delay of surgery (defined as on-study surgery occurring ≥9 weeks after initiation of neoadjuvant KEYTRUDA) due to adverse reactions, and 2.8% did not receive adjuvant treatment due to adverse reactions.
In the adjuvant phase of KEYNOTE-689, of the 255 patients who received at least one dose of KEYTRUDA, 38% experienced serious adverse reactions. The most frequent serious adverse reactions reported in ≥1% of KEYTRUDA-treated patients were pneumonia (2.7%), pyrexia (2.4%), stomatitis (2.4%), acute kidney injury (2.0%), pneumonitis (1.6%), COVID-19 (1.2%), death not otherwise specified (1.2%), diarrhea (1.2%), dysphagia (1.2%), gastrostomy tube site complication (1.2%), and immune-mediated hepatitis (1.2%). Fatal adverse reactions occurred in 5% of patients, including death not otherwise specified (1.2%), acute renal failure (0.4%), hypercalcemia (0.4%), pulmonary hemorrhage (0.4%), dysphagia/malnutrition (0.4%), mesenteric thrombosis (0.4%), sepsis (0.4%), pneumonia (0.4%), COVID-19 (0.4%), respiratory failure (0.4%), cardiovascular disorder (0.4%), and gastrointestinal hemorrhage (0.4%). Permanent discontinuation of adjuvant KEYTRUDA due to an adverse reaction occurred in 17% of patients. The most frequent (≥1%) adverse reactions that led to permanent discontinuation of adjuvant KEYTRUDA were pneumonitis, colitis, immune-mediated hepatitis, and death not otherwise specified.
In KEYNOTE-048, KEYTRUDA monotherapy was discontinued due to adverse events in 12% of 300 patients with HNSCC; the most common adverse reactions leading to permanent discontinuation were sepsis (1.7%) and pneumonia (1.3%). The most common adverse reactions (≥20%) were fatigue (33%), constipation (20%), and rash (20%).
In KEYNOTE-048, when KEYTRUDA was administered in combination with platinum (cisplatin or carboplatin) and FU chemotherapy, KEYTRUDA was discontinued due to adverse reactions in 16% of 276 patients with HNSCC. The most common adverse reactions resulting in permanent discontinuation of KEYTRUDA were pneumonia (2.5%), pneumonitis (1.8%), and septic shock (1.4%). The most common adverse reactions (≥20%) were nausea (51%), fatigue (49%), constipation (37%), vomiting (32%), mucosal inflammation (31%), diarrhea (29%), decreased appetite (29%), stomatitis (26%), and cough (22%).
In KEYNOTE-012, KEYTRUDA was discontinued due to adverse reactions in 17% of 192 patients with HNSCC. Serious adverse reactions occurred in 45% of patients. The most frequent serious adverse reactions reported in at least 2% of patients were pneumonia, dyspnea, confusional state, vomiting, pleural effusion, and respiratory failure. The most common adverse reactions (≥20%) were fatigue, decreased appetite, and dyspnea. Adverse reactions occurring in patients with HNSCC were generally similar to those occurring in patients with melanoma or NSCLC who received KEYTRUDA as a monotherapy, with the exception of increased incidences of facial edema and new or worsening hypothyroidism.
In KEYNOTE-A39, when KEYTRUDA was administered in combination with enfortumab vedotin to patients with locally advanced or metastatic urothelial cancer (n=440), fatal adverse reactions occurred in 3.9% of patients, including acute respiratory failure (0.7%), pneumonia (0.5%), and pneumonitis/ILD (0.2%). Serious adverse reactions occurred in 50% of patients receiving KEYTRUDA in combination with enfortumab vedotin; the serious adverse reactions in ≥2% of patients were rash (6%), acute kidney injury (5%), pneumonitis/ILD (4.5%), urinary tract infection (3.6%), diarrhea (3.2%), pneumonia (2.3%), pyrexia (2%), and hyperglycemia (2%). Permanent discontinuation of KEYTRUDA occurred in 27% of patients. The most common adverse reactions (≥2%) resulting in permanent discontinuation of KEYTRUDA were pneumonitis/ILD (4.8%) and rash (3.4%). The most common adverse reactions (≥20%) occurring in patients treated with KEYTRUDA in combination with enfortumab vedotin were rash (68%), peripheral neuropathy (67%), fatigue (51%), pruritus (41%), diarrhea (38%), alopecia (35%), weight loss (33%), decreased appetite (33%), nausea (26%), constipation (26%), dry eye (24%), dysgeusia (21%), and urinary tract infection (21%).
In KEYNOTE-052, KEYTRUDA was discontinued due to adverse reactions in 11% of 370 patients with locally advanced or metastatic urothelial carcinoma. Serious adverse reactions occurred in 42% of patients; those ≥2% were urinary tract infection, hematuria, acute kidney injury, pneumonia, and urosepsis. The most common adverse reactions (≥20%) were fatigue (38%), musculoskeletal pain (24%), decreased appetite (22%), constipation (21%), rash (21%), and diarrhea (20%).
In KEYNOTE-045, KEYTRUDA was discontinued due to adverse reactions in 8% of 266 patients with locally advanced or metastatic urothelial carcinoma. The most common adverse reaction resulting in permanent discontinuation of KEYTRUDA was pneumonitis (1.9%). Serious adverse reactions occurred in 39% of KEYTRUDA-treated patients; those ≥2% were urinary tract infection, pneumonia, anemia, and pneumonitis. The most common adverse reactions (≥20%) in patients who received KEYTRUDA were fatigue (38%), musculoskeletal pain (32%), pruritus (23%), decreased appetite (21%), nausea (21%), and rash (20%).
In KEYNOTE-905, the most common adverse reactions (≥20%) occurring in cisplatin-ineligible patients with MIBC treated with KEYTRUDA in combination with enfortumab vedotin (n =167) were rash (54%), pruritus (47%), fatigue (47%), peripheral neuropathy (39%), alopecia (35%), dysgeusia (35%), diarrhea (34%), constipation (28%), decreased appetite (28%), nausea (26%), urinary tract infection (24%), dry eye (21%), and weight loss (20%).
In the neoadjuvant phase of KEYNOTE-905, serious adverse reactions occurred in 27% (n=167) of patients; the most frequent (≥2%) were urinary tract infection (3.6%) and hematuria (2.4%). Fatal adverse reactions occurred in 1.2% of patients, including myasthenia gravis and toxic epidermal necrolysis (0.6% each). Additional fatal adverse reactions were reported in 2.7% of patients in the post-surgery phase before adjuvant treatment started, including sepsis and intestinal obstruction (1.4% each). Permanent discontinuation of KEYTRUDA due to an adverse reaction occurred in 15% of patients; the most frequent (>1%) were rash (2.4%, including generalized exfoliative dermatitis), increased alanine aminotransferase, increased aspartate aminotransferase, diarrhea, dysgeusia, and toxic epidermal necrolysis (1.2% each). Of the 167 patients in the KEYTRUDA in combination with enfortumab vedotin arm who received neoadjuvant treatment, 7 (4.2%) patients did not receive surgery due to adverse reactions. The adverse reactions that led to cancellation of surgery were acute myocardial infarction, bile duct cancer, colon cancer, respiratory distress, urinary tract infection, and two deaths due to myasthenia gravis and toxic epidermal necrolysis (0.6% each).
Of the 146 patients who received neoadjuvant treatment with KEYTRUDA in combination with enfortumab vedotin and underwent radical cystectomy, 6 (4.1%) patients experienced delay of surgery (defined as time from last neoadjuvant treatment to surgery exceeding 8 weeks) due to adverse reactions.
In the adjuvant phase of KEYNOTE-905, serious adverse reactions occurred in 43% (n=100); the most frequent (≥2%) were urinary tract infection (8%); acute kidney injury and pyelonephritis (5% each); urosepsis (4%); and hypokalemia, intestinal obstruction, and sepsis (2% each). Fatal adverse reactions occurred in 7% of patients, including urosepsis, intracranial hemorrhage, death, myocardial infarction, multiple organ dysfunction syndrome, and pseudomonal pneumonia (1% each). Permanent discontinuation of KEYTRUDA due to an adverse reaction occurred in 28% of patients; the most frequent (>1%) were diarrhea (5%), peripheral neuropathy, acute kidney injury, and pneumonitis (2% each).
In KEYNOTE-057, KEYTRUDA was discontinued due to adverse reactions in 11% of 148 patients with high-risk NMIBC. The most common adverse reaction resulting in permanent discontinuation of KEYTRUDA was pneumonitis (1.4%). Serious adverse reactions occurred in 28% of patients; those ≥2% were pneumonia (3%), cardiac ischemia (2%), colitis (2%), pulmonary embolism (2%), sepsis (2%), and urinary tract infection (2%). The most common adverse reactions (≥20%) were fatigue (29%), diarrhea (24%), and rash (24%).
Adverse reactions occurring in patients with MSI-H or dMMR CRC were similar to those occurring in patients with melanoma or NSCLC who received KEYTRUDA as a monotherapy.
In KEYNOTE-158 and KEYNOTE-164, adverse reactions occurring in patients with MSI-H or dMMR cancer were similar to those occurring in patients with other solid tumors who received KEYTRUDA as a single agent.
In KEYNOTE-811, fatal adverse reactions occurred in 3 patients who received KEYTRUDA in combination with trastuzumab and CAPOX (capecitabine plus oxaliplatin) or FP (5-FU plus cisplatin) and included pneumonitis in 2 patients and hepatitis in 1 patient. KEYTRUDA was discontinued due to adverse reactions in 13% of 350 patients with locally advanced unresectable or metastatic HER2-positive gastric or GEJ adenocarcinoma. Adverse reactions resulting in permanent discontinuation of KEYTRUDA in ≥1% of patients were pneumonitis (2.0%) and pneumonia (1.1%). In the KEYTRUDA arm vs placebo, there was a difference of ≥5% incidence between patients treated with KEYTRUDA vs standard of care for diarrhea (53% vs 47%), rash (35% vs 28%), hypothyroidism (11% vs 5%), and pneumonia (11% vs 5%).
In KEYNOTE-859, when KEYTRUDA was administered in combination with fluoropyrimidine- and platinum-containing chemotherapy, serious adverse reactions occurred in 45% of 785 patients. Serious adverse reactions in >2% of patients included pneumonia (4.1%), diarrhea (3.9%), hemorrhage (3.9%), and vomiting (2.4%). Fatal adverse reactions occurred in 8% of patients who received KEYTRUDA, including infection (2.3%) and thromboembolism (1.3%). KEYTRUDA was permanently discontinued due to adverse reactions in 15% of patients. The most common adverse reactions resulting in permanent discontinuation of KEYTRUDA (≥1%) were infections (1.8%) and diarrhea (1.0%). The most common adverse reactions (reported in ≥20%) in patients receiving KEYTRUDA in combination with chemotherapy were peripheral neuropathy (47%), nausea (46%), fatigue (40%), diarrhea (36%), vomiting (34%), decreased appetite (29%), abdominal pain (26%), palmar-plantar erythrodysesthesia syndrome (25%), constipation (22%), and weight loss (20%).
In KEYNOTE-590, when KEYTRUDA was administered with cisplatin and fluorouracil to patients with metastatic or locally advanced esophageal or GEJ (tumors with epicenter 1 to 5 centimeters above the GEJ) carcinoma who were not candidates for surgical resection or definitive chemoradiation, KEYTRUDA was discontinued due to adverse reactions in 15% of 370 patients. The most common adverse reactions resulting in permanent discontinuation of KEYTRUDA (≥1%) were pneumonitis (1.6%), acute kidney injury (1.1%), and pneumonia (1.1%). The most common adverse reactions (≥20%) with KEYTRUDA in combination with chemotherapy were nausea (67%), fatigue (57%), decreased appetite (44%), constipation (40%), diarrhea (36%), vomiting (34%), stomatitis (27%), and weight loss (24%).
Adverse reactions occurring in patients with esophageal cancer who received KEYTRUDA as a monotherapy were similar to those occurring in patients with melanoma or NSCLC who received KEYTRUDA as a monotherapy.
In KEYNOTE-A18, when KEYTRUDA was administered with CRT (cisplatin plus external beam radiation therapy [EBRT] followed by brachytherapy [BT]) to patients with FIGO 2014 Stage III-IVA cervical cancer, fatal adverse reactions occurred in 1.4% of 294 patients, including 1 case each (0.3%) of large intestinal perforation, urosepsis, sepsis, and vaginal hemorrhage. Serious adverse reactions occurred in 34% of patients; those ≥1% included urinary tract infection (3.1%), urosepsis (1.4%), and sepsis (1%). KEYTRUDA was discontinued for adverse reactions in 9% of patients. The most common adverse reaction (≥1%) resulting in permanent discontinuation was diarrhea (1%). For patients treated with KEYTRUDA in combination with CRT, the most common adverse reactions (≥10%) were nausea (56%), diarrhea (51%), urinary tract infection (35%), vomiting (34%), fatigue (28%), hypothyroidism (23%), constipation (20%), weight loss (19%), decreased appetite (18%), pyrexia (14%), abdominal pain and hyperthyroidism (13% each), dysuria and rash (12% each), back and pelvic pain (11% each), and COVID-19 (10%).
In KEYNOTE-826, when KEYTRUDA was administered in combination with paclitaxel and cisplatin or paclitaxel and carboplatin, with or without bevacizumab (n=307), to patients with persistent, recurrent, or first-line metastatic cervical cancer regardless of tumor PD-L1 expression who had not been treated with chemotherapy except when used concurrently as a radio-sensitizing agent, fatal adverse reactions occurred in 4.6% of patients, including 3 cases of hemorrhage, 2 cases each of sepsis and due to unknown causes, and 1 case each of acute myocardial infarction, autoimmune encephalitis, cardiac arrest, cerebrovascular accident, femur fracture with perioperative pulmonary embolus, intestinal perforation, and pelvic infection. Serious adverse reactions occurred in 50% of patients receiving KEYTRUDA in combination with chemotherapy with or without bevacizumab; those ≥3% were febrile neutropenia (6.8%), urinary tract infection (5.2%), anemia (4.6%), and acute kidney injury and sepsis (3.3% each).
KEYTRUDA was discontinued in 15% of patients due to adverse reactions. The most common adverse reaction resulting in permanent discontinuation (≥1%) was colitis (1%).
For patients treated with KEYTRUDA, chemotherapy, and bevacizumab (n=196), the most common adverse reactions (≥20%) were peripheral neuropathy (62%), alopecia (58%), anemia (55%), fatigue/asthenia (53%), nausea and neutropenia (41% each), diarrhea (39%), hypertension and thrombocytopenia (35% each), constipation and arthralgia (31% each), vomiting (30%), urinary tract infection (27%), rash (26%), leukopenia (24%), hypothyroidism (22%), and decreased appetite (21%).
For patients treated with KEYTRUDA in combination with chemotherapy with or without bevacizumab, the most common adverse reactions (≥20%) were peripheral neuropathy (58%), alopecia (56%), fatigue (47%), nausea (40%), diarrhea (36%), constipation (28%), arthralgia (27%), vomiting (26%), hypertension and urinary tract infection (24% each), and rash (22%).
In KEYNOTE-158, KEYTRUDA was discontinued due to adverse reactions in 8% of 98 patients with previously treated recurrent or metastatic cervical cancer. Serious adverse reactions occurred in 39% of patients receiving KEYTRUDA; the most frequent included anemia (7%), fistula, hemorrhage, and infections [except urinary tract infections] (4.1% each). The most common adverse reactions (≥20%) were fatigue (43%), musculoskeletal pain (27%), diarrhea (23%), pain and abdominal pain (22% each), and decreased appetite (21%).
In KEYNOTE-394, KEYTRUDA was discontinued due to adverse reactions in 13% of 299 patients with previously treated hepatocellular carcinoma. The most common adverse reaction resulting in permanent discontinuation of KEYTRUDA was ascites (2.3%). The most common adverse reactions in patients receiving KEYTRUDA (≥10%) were pyrexia (18%), rash (18%), diarrhea (16%), decreased appetite (15%), pruritus (12%), upper respiratory tract infection (11%), cough (11%), and hypothyroidism (10%).
In KEYNOTE-966, when KEYTRUDA was administered in combination with gemcitabine and cisplatin, KEYTRUDA was discontinued for adverse reactions in 15% of 529 patients with locally advanced unresectable or metastatic biliary tract cancer. The most common adverse reaction resulting in permanent discontinuation of KEYTRUDA (≥1%) was pneumonitis (1.3%). Adverse reactions leading to the interruption of KEYTRUDA occurred in 55% of patients. The most common adverse reactions or laboratory abnormalities leading to interruption of KEYTRUDA (≥2%) were decreased neutrophil count (18%), decreased platelet count (10%), anemia (6%), decreased white blood cell count (4%), pyrexia (3.8%), fatigue (3.0%), cholangitis (2.8%), increased ALT (2.6%), increased AST (2.5%), and biliary obstruction (2.3%).
In KEYNOTE-017 and KEYNOTE-913, adverse reactions occurring in patients with MCC (n=105) were generally similar to those occurring in patients with melanoma or NSCLC who received KEYTRUDA as a single agent.
In KEYNOTE-426, when KEYTRUDA was administered in combination with axitinib, fatal adverse reactions occurred in 3.3% of 429 patients. Serious adverse reactions occurred in 40% of patients, the most frequent (≥1%) were hepatotoxicity (7%), diarrhea (4.2%), acute kidney injury (2.3%), dehydration (1%), and pneumonitis (1%). Permanent discontinuation due to an adverse reaction occurred in 31% of patients; KEYTRUDA only (13%), axitinib only (13%), and the combination (8%); the most common were hepatotoxicity (13%), diarrhea/colitis (1.9%), acute kidney injury (1.6%), and cerebrovascular accident (1.2%). The most common adverse reactions (≥20%) were diarrhea (56%), fatigue/asthenia (52%), hypertension (48%), hepatotoxicity (39%), hypothyroidism (35%), decreased appetite (30%), palmar-plantar erythrodysesthesia (28%), nausea (28%), stomatitis/mucosal inflammation (27%), dysphonia (25%), rash (25%), cough (21%), and constipation (21%).
In KEYNOTE-564, when KEYTRUDA was administered as a single agent for the adjuvant treatment of renal cell carcinoma, serious adverse reactions occurred in 20% of patients receiving KEYTRUDA; the serious adverse reactions (≥1%) were acute kidney injury, adrenal insufficiency, pneumonia, colitis, and diabetic ketoacidosis (1% each). Fatal adverse reactions occurred in 0.2% including 1 case of pneumonia. Discontinuation of KEYTRUDA due to adverse reactions occurred in 21% of 488 patients; the most common (≥1%) were increased ALT (1.6%), colitis (1%), and adrenal insufficiency (1%). The most common adverse reactions (≥20%) were musculoskeletal pain (41%), fatigue (40%), rash (30%), diarrhea (27%), pruritus (23%), and hypothyroidism (21%).
In KEYNOTE-868, when KEYTRUDA was administered in combination with chemotherapy (paclitaxel and carboplatin) to patients with advanced or recurrent endometrial carcinoma (n=382), serious adverse reactions occurred in 35% of patients receiving KEYTRUDA in combination with chemotherapy, compared to 19% of patients receiving placebo in combination with chemotherapy (n=377). Fatal adverse reactions occurred in 1.6% of patients receiving KEYTRUDA in combination with chemotherapy, including COVID-19 (0.5%) and cardiac arrest (0.3%). KEYTRUDA was discontinued for an adverse reaction in 14% of patients. Adverse reactions occurring in patients treated with KEYTRUDA and chemotherapy were generally similar to those observed with KEYTRUDA alone or chemotherapy alone, with the exception of rash (33% all Grades; 2.9% Grades 3-4).
Adverse reactions occurring in patients with MSI-H or dMMR endometrial carcinoma who received KEYTRUDA as a single agent were similar to those occurring in patients with melanoma or NSCLC who received KEYTRUDA as a single agent.
Adverse reactions occurring in patients with recurrent or metastatic cSCC or locally advanced cSCC were similar to those occurring in patients with melanoma or NSCLC who received KEYTRUDA as a monotherapy.
In KEYNOTE-522, when KEYTRUDA was administered with neoadjuvant chemotherapy (carboplatin and paclitaxel followed by doxorubicin or epirubicin and cyclophosphamide) followed by surgery and continued adjuvant treatment with KEYTRUDA as a single agent (n=778) to patients with newly diagnosed, previously untreated, high-risk early-stage TNBC, fatal adverse reactions occurred in 0.9% of patients, including 1 each of adrenal crisis, autoimmune encephalitis, hepatitis, pneumonia, pneumonitis, pulmonary embolism, and sepsis in association with multiple organ dysfunction syndrome and myocardial infarction. Serious adverse reactions occurred in 44% of patients receiving KEYTRUDA; those ≥2% were febrile neutropenia (15%), pyrexia (3.7%), anemia (2.6%), and neutropenia (2.2%). KEYTRUDA was discontinued in 20% of patients due to adverse reactions. The most common reactions (≥1%) resulting in permanent discontinuation were increased ALT (2.7%), increased AST (1.5%), and rash (1%). The most common adverse reactions (≥20%) in patients receiving KEYTRUDA were fatigue (70%), nausea (67%), alopecia (61%), rash (52%), constipation (42%), diarrhea and peripheral neuropathy (41% each), stomatitis (34%), vomiting (31%), headache (30%), arthralgia (29%), pyrexia (28%), cough (26%), abdominal pain (24%), decreased appetite (23%), insomnia (21%), and myalgia (20%).
In KEYNOTE-355, when KEYTRUDA and chemotherapy (paclitaxel, paclitaxel protein-bound, or gemcitabine and carboplatin) were administered to patients with locally recurrent unresectable or metastatic TNBC who had not been previously treated with chemotherapy in the metastatic setting (n=596), fatal adverse reactions occurred in 2.5% of patients, including cardio-respiratory arrest (0.7%) and septic shock (0.3%). Serious adverse reactions occurred in 30% of patients receiving KEYTRUDA in combination with chemotherapy; the serious reactions in ≥2% were pneumonia (2.9%), anemia (2.2%), and thrombocytopenia (2%). KEYTRUDA was discontinued in 11% of patients due to adverse reactions. The most common reactions resulting in permanent discontinuation (≥1%) were increased ALT (2.2%), increased AST (1.5%), and pneumonitis (1.2%). The most common adverse reactions (≥20%) in patients receiving KEYTRUDA in combination with chemotherapy were fatigue (48%), nausea (44%), alopecia (34%), diarrhea and constipation (28% each), vomiting and rash (26% each), cough (23%), decreased appetite (21%), and headache (20%).
Lactation
Because of the potential for serious adverse reactions in breastfed children, advise women not to breastfeed during treatment and for 4 months after the last dose.
Pediatric Use
In KEYNOTE-051, 173 pediatric patients (65 pediatric patients aged 6 months to younger than 12 years and 108 pediatric patients aged 12 years to 17 years) were administered KEYTRUDA 2 mg/kg every 3 weeks. The median duration of exposure was 2.1 months (range: 1 day to 25 months).
The safety and effectiveness of KEYTRUDA QLEX for the treatment of pediatric patients 12 years and older who weigh greater than 40 kg have been established for:
- Stage IIB, IIC, or III melanoma following complete resection
- Unresectable or metastatic microsatellite instability-high (MSI-H) or mismatch repair deficient (dMMR) solid tumors
- Recurrent locally advanced or metastatic Merkel cell carcinoma
Use of KEYTRUDA QLEX in pediatric patients for these indications is supported by evidence from adequate and well-controlled studies of KEYTRUDA in adults and additional pharmacokinetic and safety data for KEYTRUDA in pediatric patients 12 years and older. Pembrolizumab exposures in pediatric patients 12 years and older who weigh greater than 40 kg are predicted to be within range of those observed in adults at the same dosage.
The safety and effectiveness of KEYTRUDA as a single agent have been established in pediatric patients with melanoma (stage IIB, IIC, or III melanoma following complete resection in pediatric patients 12 and older), MCC, and MSI-H or dMMR cancer.
Use of KEYTRUDA in pediatric patients for these indications is supported by evidence from adequate and well-controlled studies in adults with additional pharmacokinetic and safety data in pediatric patients.
The safety and effectiveness of KEYTRUDA QLEX have not been established in pediatric patients younger than 12 years of age for the treatment of melanoma, MCC, and MSI-H or dMMR cancer.
The safety and effectiveness of KEYTRUDA and KEYTRUDA QLEX have not been established in pediatric patients for other approved indications shown.
Adverse reactions that occurred at a ≥10% higher rate in pediatric patients when compared to adults were pyrexia (33%), leukopenia (30%), vomiting (29%), neutropenia (28%), headache (25%), abdominal pain (23%), thrombocytopenia (22%), Grade 3 anemia (17%), decreased lymphocyte count (13%), and decreased white blood cell count (11%).
Geriatric Use
Of the 564 patients with locally advanced or metastatic urothelial cancer treated with KEYTRUDA in combination with enfortumab vedotin, 44% (n=247) were 65-74 years and 26% (n=144) were 75 years or older. No overall differences in effectiveness were observed between patients 65 years of age or older and younger patients. Patients 75 years of age or older treated with KEYTRUDA in combination with enfortumab vedotin experienced a higher incidence of fatal adverse reactions than younger patients. The incidence of fatal adverse reactions was 4% in patients younger than 75 and 7% in patients 75 years or older.
Of the 167 patients with MIBC treated with KEYTRUDA in combination with enfortumab vedotin, 37% (n=61) were 65-74 years and 46% (n=77) were 75 years or older. Patients 75 years of age or older treated with KEYTRUDA in combination with enfortumab vedotin experienced a higher incidence of fatal adverse reactions than younger patients. The incidence of fatal adverse reactions was 4% in patients younger than 75 and 12% in patients 75 years or older.
Additional Selected KEYTRUDA and KEYTRUDA QLEX Indications in the U.S.
Melanoma
KEYTRUDA and KEYTRUDA QLEX are each indicated for the treatment of adult patients with unresectable or metastatic melanoma.
KEYTRUDA and KEYTRUDA QLEX are each indicated for the adjuvant treatment of adult and pediatric patients 12 years and older with stage IIB, IIC, or III melanoma following complete resection.
Non-Small Cell Lung Cancer
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with pemetrexed and platinum chemotherapy, for the first-line treatment of adult patients with metastatic nonsquamous non–small cell lung cancer (NSCLC), with no EGFR or ALK genomic tumor aberrations.
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with carboplatin and either paclitaxel or paclitaxel protein-bound, for the first-line treatment of adult patients with metastatic squamous NSCLC.
KEYTRUDA and KEYTRUDA QLEX, as single agents, are each indicated for the first-line treatment of adult patients with NSCLC expressing PD-L1 [tumor proportion score (TPS) ≥1%] as determined by an FDA-approved test, with no EGFR or ALK genomic tumor aberrations, and is:
- stage III where patients are not candidates for surgical resection or definitive chemoradiation, or
- metastatic.
KEYTRUDA and KEYTRUDA QLEX, as single agents, are each indicated for the treatment of adult patients with metastatic NSCLC whose tumors express PD-L1 (TPS ≥1%) as determined by an FDA-approved test, with disease progression on or after platinum-containing chemotherapy. Patients with EGFR or ALK genomic tumor aberrations should have disease progression on FDA-approved therapy for these aberrations prior to receiving KEYTRUDA or KEYTRUDA QLEX.
KEYTRUDA and KEYTRUDA QLEX are each indicated for the treatment of adult patients with resectable (tumors ≥4 cm or node positive) NSCLC in combination with platinum-containing chemotherapy as neoadjuvant treatment, and then continued as a single agent as adjuvant treatment after surgery.
KEYTRUDA and KEYTRUDA QLEX, as single agents, are each indicated as adjuvant treatment following resection and platinum-based chemotherapy for adult patients with stage IB (T2a ≥4 cm), II, or IIIA NSCLC.
Malignant Pleural Mesothelioma
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with pemetrexed and platinum chemotherapy, for the first-line treatment of adult patients with unresectable advanced or metastatic malignant pleural mesothelioma (MPM).
Head and Neck Squamous Cell Cancer
KEYTRUDA and KEYTRUDA QLEX are each indicated for the treatment of adult patients with resectable locally advanced head and neck squamous cell carcinoma (HNSCC) whose tumors express PD-L1 [Combined Positive Score (CPS) ≥1] as determined by an FDA-approved test, as a single agent as neoadjuvant treatment, continued as adjuvant treatment in combination with radiotherapy (RT) with or without cisplatin and then as a single agent.
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with platinum and fluorouracil (FU), for the first-line treatment of adult patients with metastatic or with unresectable, recurrent head and neck squamous cell carcinoma (HNSCC).
KEYTRUDA and KEYTRUDA QLEX, as single agents, are each indicated for the first-line treatment of adult patients with metastatic or with unresectable, recurrent HNSCC whose tumors express PD-L1 [Combined Positive Score (CPS) ≥1] as determined by an FDA-approved test.
KEYTRUDA and KEYTRUDA QLEX, as single agents, are each indicated for the treatment of adult patients with recurrent or metastatic head and neck squamous cell carcinoma (HNSCC) with disease progression on or after platinum-containing chemotherapy.
Microsatellite Instability-High or Mismatch Repair Deficient Cancer
KEYTRUDA and KEYTRUDA QLEX are each indicated for the treatment of adult patients with unresectable or metastatic microsatellite instability-high (MSI-H) or mismatch repair deficient (dMMR) solid tumors, as determined by an FDA-approved test, that have progressed following prior treatment and who have no satisfactory alternative treatment options. For this indication, KEYTRUDA also is indicated for the treatment of pediatric patients, and KEYTRUDA QLEX also is indicated for the treatment of pediatric patients 12 years and older.
Microsatellite Instability-High or Mismatch Repair Deficient Colorectal Cancer
KEYTRUDA and KEYTRUDA QLEX are each indicated for the treatment of adult patients with unresectable or metastatic MSI-H or dMMR colorectal cancer (CRC) as determined by an FDA-approved test.
Gastric Cancer
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with trastuzumab, fluoropyrimidine- and platinum-containing chemotherapy, for the first-line treatment of adults with locally advanced unresectable or metastatic HER2-positive gastric or gastroesophageal junction (GEJ) adenocarcinoma whose tumors express PD-L1 (CPS ≥1) as determined by an FDA-approved test.
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with fluoropyrimidine- and platinum-containing chemotherapy, for the first-line treatment of adults with locally advanced unresectable or metastatic HER2-negative gastric or gastroesophageal junction (GEJ) adenocarcinoma whose tumors express PD-L1 (CPS ≥1) as determined by an FDA-approved test.
Esophageal Cancer
KEYTRUDA and KEYTRUDA QLEX are each indicated for the treatment of adult patients with locally advanced or metastatic esophageal or gastroesophageal junction (GEJ) (tumors with epicenter 1 to 5 centimeters above the GEJ) carcinoma that is not amenable to surgical resection or definitive chemoradiation either:
- in combination with platinum- and fluoropyrimidine-based chemotherapy for patients with tumors that express PD-L1 (CPS ≥1), or
- as a single agent after one or more prior lines of systemic therapy for patients with tumors of squamous cell histology that express PD-L1 (CPS ≥10) as determined by an FDA-approved test.
Cervical Cancer
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with chemoradiotherapy (CRT), for the treatment of adult patients with locally advanced cervical cancer involving the lower third of the vagina, with or without extension to pelvic sidewall, or hydronephrosis/non-functioning kidney, or spread to adjacent pelvic organs (FIGO 2014 III-IVA).
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with chemotherapy, with or without bevacizumab, for the treatment of adult patients with persistent, recurrent, or metastatic cervical cancer whose tumors express PD-L1 (CPS ≥1) as determined by an FDA-approved test.
KEYTRUDA and KEYTRUDA QLEX, as single agents, are each indicated for the treatment of adult patients with recurrent or metastatic cervical cancer with disease progression on or after chemotherapy whose tumors express PD-L1 (CPS ≥1) as determined by an FDA-approved test.
Hepatocellular Carcinoma
KEYTRUDA and KEYTRUDA QLEX are each indicated for the treatment of adult patients with hepatocellular carcinoma (HCC) secondary to hepatitis B who have received prior systemic therapy other than a PD-1/PD-L1–containing regimen.
Biliary Tract Cancer
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with gemcitabine and cisplatin, for the treatment of adult patients with locally advanced unresectable or metastatic biliary tract cancer (BTC).
Merkel Cell Carcinoma
KEYTRUDA and KEYTRUDA QLEX are each indicated for the treatment of adult patients with recurrent locally advanced or metastatic Merkel cell carcinoma (MCC). For this indication, KEYTRUDA also is indicated for the treatment of pediatric patients, and KEYTRUDA QLEX also is indicated for the treatment of pediatric patients 12 years and older.
Renal Cell Carcinoma
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with axitinib, for the first-line treatment of adult patients with advanced renal cell carcinoma (RCC).
KEYTRUDA and KEYTRUDA QLEX are each indicated for the adjuvant treatment of adult patients with renal cell carcinoma (RCC) at intermediate high or high risk of recurrence following nephrectomy, or following nephrectomy and resection of metastatic lesions.
Endometrial Carcinoma
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with carboplatin and paclitaxel, followed by KEYTRUDA or KEYTRUDA QLEX as a single agent, for the treatment of adult patients with primary advanced or recurrent endometrial carcinoma.
KEYTRUDA and KEYTRUDA QLEX, as a single agent, are each indicated for the treatment of adult patients with advanced endometrial carcinoma that is MSI-H or dMMR, as determined by an FDA-approved test, who have disease progression following prior systemic therapy in any setting and are not candidates for curative surgery or radiation.
Cutaneous Squamous Cell Carcinoma
KEYTRUDA and KEYTRUDA QLEX are each indicated for the treatment of adult patients with recurrent or metastatic cutaneous squamous cell carcinoma (cSCC) or locally advanced cSCC that is not curable by surgery or radiation.
Triple-Negative Breast Cancer
KEYTRUDA and KEYTRUDA QLEX are each indicated for the treatment of adult patients with high-risk early-stage triple-negative breast cancer (TNBC) in combination with chemotherapy as neoadjuvant treatment, and then each continued as a single agent as adjuvant treatment after surgery.
KEYTRUDA and KEYTRUDA QLEX are each indicated, in combination with chemotherapy, for the treatment of adult patients with locally recurrent unresectable or metastatic triple-negative breast cancer (TNBC) whose tumors express PD-L1 (CPS ≥10) as determined by an FDA-approved test.
About the Merck Access Program for KEYTRUDA
At Merck, we are committed to supporting accessibility to our cancer medicines. Merck provides multiple programs to help appropriate patients who are prescribed KEYTRUDA have access to our anti-PD-1 therapy. The Merck Access Program provides reimbursement support for patients receiving KEYTRUDA, including information to help with out-of-pocket costs and co-pay assistance for eligible patients. More information is available by calling 855-257-3932 or visiting www.merckaccessprogram-keytruda.com/.
About Merck’s Patient Support Program for KEYTRUDA
Merck is committed to helping provide patients and their caregivers support throughout their treatment with KEYTRUDA. The KEY+YOU Patient Support Program provides a range of resources and support. For further information and to sign up, eligible patients may call 85-KEYTRUDA (855-398-7832) or visit www.keytruda.com/.
Merck’s focus on cancer
Every day, we follow the science as we work to discover innovations that can help patients, no matter what stage of cancer they have. As a leading oncology company, we are pursuing research where scientific opportunity and medical need converge, underpinned by our diverse pipeline of more than 25 novel mechanisms. With one of the largest clinical development programs across more than 30 tumor types, we strive to advance breakthrough science that will shape the future of oncology. By addressing barriers to clinical trial participation, screening and treatment, we work with urgency to reduce disparities and help ensure patients have access to high-quality cancer care. Our unwavering commitment is what will bring us closer to our goal of bringing life to more patients with cancer. For more information, visit https://www.merck.com/research/oncology/.
About Merck
At Merck, known as MSD outside of the United States and Canada, we are unified around our purpose: We use the power of leading-edge science to save and improve lives around the world. For more than 130 years, we have brought hope to humanity through the development of important medicines and vaccines. We aspire to be the premier research-intensive biopharmaceutical company in the world – and today, we are at the forefront of research to deliver innovative health solutions that advance the prevention and treatment of diseases in people and animals. We foster a diverse and inclusive global workforce and operate responsibly every day to enable a safe, sustainable and healthy future for all people and communities. For more information, visit www.merck.com and connect with us on X (formerly Twitter), Facebook, Instagram, YouTube and LinkedIn.
Forward-Looking Statement of Merck & Co., Inc., Rahway, N.J., USA
This news release of Merck & Co., Inc., Rahway, N.J., USA (the “company”) includes “forward-looking statements” within the meaning of the safe harbor provisions of the U.S. Private Securities Litigation Reform Act of 1995. These statements are based upon the current beliefs and expectations of the company’s management and are subject to significant risks and uncertainties. There can be no guarantees with respect to pipeline candidates that the candidates will receive the necessary regulatory approvals or that they will prove to be commercially successful. If underlying assumptions prove inaccurate or risks or uncertainties materialize, actual results may differ materially from those set forth in the forward-looking statements.
Risks and uncertainties include but are not limited to, general industry conditions and competition; general economic factors, including interest rate and currency exchange rate fluctuations; the impact of pharmaceutical industry regulation and health care legislation in the United States and internationally; global trends toward health care cost containment; technological advances, new products and patents attained by competitors; challenges inherent in new product development, including obtaining regulatory approval; the company’s ability to accurately predict future market conditions; manufacturing difficulties or delays; financial instability of international economies and sovereign risk; dependence on the effectiveness of the company’s patents and other protections for innovation products; and the exposure to litigation, including patent litigation, and/or regulatory actions.
The company undertakes no obligation to publicly update any forward-looking statement, whether as a result of new information, future events or otherwise. Additional factors that could cause results to differ materially from those described in the forward-looking statements can be found in the company’s Annual Report on Form 10-K for the year ended December 31, 2024 and the company’s other filings with the Securities and Exchange Commission (SEC) available at the SEC’s Internet site (www.sec.gov).
Please see Prescribing Information for KEYTRUDA (pembrolizumab) at https://www.merck.com/product/usa/pi_circulars/k/keytruda/keytruda_pi.pdf and Medication Guide for KEYTRUDA at https://www.merck.com/product/usa/pi_circulars/k/keytruda/keytruda_mg.pdf.
Please see Prescribing Information for KEYTRUDA QLEX (pembrolizumab and berahyaluronidase alfa-pmph) at https://www.merck.com/product/usa/pi_circulars/k/keytruda_qlex/keytruda_qlex_pi.pdf and Medication Guide for KEYTRUDA QLEX at https://www.merck.com/product/usa/pi_circulars/k/keytruda_qlex/keytruda_qlex_mg.pdf
Source: Merck & Co., Inc., Rahway, NJ, USA
Continue Reading
-

Journal of Medical Internet Research
Introduction
Digital health technologies (DHTs), encompassing a wide array of tools from mHealth apps and telemedicine to artificial intelligence, hold transformative potential for health care worldwide [,]. By expanding access to care, enhancing patient engagement, and improving the efficiency of diagnostic and treatment pathways, these technologies offer significant opportunities to build more accessible, affordable, and equitable health systems [-]. The World Health Organization defines digital health as “the field of knowledge and practice associated with the development and use of digital technologies to improve health.” [] This broad concept includes not only established eHealth domains but also emerging areas such as big data analytics and the Internet of Things, reflecting its integral role in modern health care.
However, the benefits of digital health are not universally realized and are not distributed equally []. Factors such as digital literacy, access to devices and internet, socioeconomic status, cultural relevance, and community context influence who benefits from digital health solutions [,]. In fact, digital literacy and internet connectivity have been termed “super social determinants of health” because of their foundational influence on all other determinants of health in the digital age []. The rapid digitization of health care may widen health disparities if solutions are not developed with these determinants in mind []. Growing evidence suggests that the digital transformation in health care may exacerbate existing health inequities, creating new barriers for marginalized populations including persons with disabilities, patients of racial or ethnic minority groups, those with limited language proficiency, and people with low socioeconomic status [-].
Previous research on the digital divide and health care access for vulnerable groups has illuminated various forms of exclusion, such as the inaccessibility of health websites and mobile apps, often due to a lack of distinguishable button features, inaccessible content, or the absence of assistive technology integration [,]. For individuals with blindness specifically, existing literature frequently points to significant challenges in interacting with visually-oriented digital environments []. Crucially, much of this prior research tends to homogenize the experiences of vulnerable populations [], overlooking the nuanced realities and varying adaptive capacities within specific subgroups. This oversight means that while broad challenges are identified, the potential for certain segments of vulnerable communities to navigate and even leverage digital tools remains underexplored.
Within this context, educated and digitally literate young adults with blindness represent a critically overlooked and underexplored subgroup. For the purpose of this study, we define our participant cohort as follows: “young adults” refers to individuals aged 18 to 30 years [], a generation broadly considered digitally native; “educated” refers to individuals who have received or are currently pursuing higher education (including associate’s, Bachelor’s, Master’s, or doctoral degrees); and “blindness” is defined according to the World Health Organization criteria of a presenting visual acuity of less than 3/60 in the better eye []. This cohort embodies a central paradox: they are a digitally native generation, often exhibiting a greater willingness and capacity to adopt new technologies and engage in digital transformation through exploratory learning. The proliferation of smartphones equipped with assistive features like screen readers and voice assistants theoretically holds significant promise for enhancing their independence. However, their entire digital experience is mediated by these assistive technologies, rendering them uniquely vulnerable to design and usability flaws in mainstream applications. The existing literature, by not adequately differentiating within the community with blindness, fails to capture the unique dynamic of empowerment and exclusion experienced by this specific subgroup. This study addresses the critical gap by proposing that a segment of high-literacy individuals with blindness, through personal effort and adaptive strategies, can indeed mitigate some impacts of the digital divide, a nuanced perspective often underestimated in studies that generalize vulnerabilities. Understanding this internal heterogeneity is paramount for developing genuinely effective and equitable digital health solutions.
China offers a uniquely relevant context for exploring these complex issues. It boasts one of the world’s largest internet user bases, exceeding 1.1 billion individuals as of 2024 [], with extensive access to a variety of internet-based services, including health care []. Concurrently, China is home to one of the largest populations with disabilities in the world, including nearly 10 million who are blind [], a significant proportion of whom are young. While some studies in China have identified health care barriers for visually impaired individuals, such as difficulties with registration, navigation, and understanding treatment processes [], the majority of empirical studies on digital health access have tended to focus on older adults or persons with disabilities in general. These studies offer valuable broad overviews but often do not provide in-depth insights into the specific experiences of educated young adults with blindness navigating both empowerment and exclusion in a rapidly digitizing health care system. The unique combination of a highly developed digital infrastructure and a large young population with blindness in China provides invaluable insights into how accessibility challenges persist and manifest even amid advanced technological environments, underscoring the urgency for inclusive design.
To address this gap, this qualitative study aims to comprehensively explore the lived experiences of educated and digitally literate young adults with blindness in China as they access health care services in the digital age. A qualitative methodology is uniquely suited to capture the rich, in-depth narratives of these interactions, uncovering the nuanced facilitators and barriers that quantitative methods might miss. This nuanced understanding of their lived experiences with the digital health ecosystem can inform policy developments and improve clinical practices in promoting digital health equity.
Methods
Study Design
We used a qualitative design to gain an in-depth understanding of how educated and digitally literate young adults with blindness navigate health care access with the assistance of DHTs. This approach was chosen to capture the rich, subjective lived experiences and perceptions of participants, offering deep insights into how they interpret their personal encounters, construct their realities, and attribute meaning to their experiences within a rapidly digitizing health care ecosystem []. A qualitative methodology is particularly appropriate for exploring complex social phenomena where individual perspectives are central to uncovering the underlying dynamics of empowerment and exclusion. This study adheres to the Consolidated Criteria for Reporting Qualitative Research (COREQ) guidelines () [].
Participants and Recruitment
Participants
This study focused on educated young adults with blindness who actively use smartphones and digital platforms to access health care services. Participants were selected based on the following inclusion and exclusion criteria ().
Textbox 1. Inclusion and exclusion criteria. Inclusion criteria
- Citizens and residents of China
- Mandarin speakers
- Young adults aged 16 to 36 years
- Higher education (associate’s degree, Bachelor’s degree, or higher)
- Capable of independently operating at least 1 digital device (eg, smartphone or computer)
- Individuals with blindness (presenting visual acuity worse than 3/60 in the better eye, based on World Health Organization standards [])
Exclusion criteria
- No experience seeking health care services within the past 2 years
- Unwilling to participate or unable to clearly articulate their experiences
- Failure to meet any of the defined inclusion criteria
Recruitment and Sample Size
A purposive snowball sampling approach was used to recruit participants. Initially, participants were selected from online communities and social media platforms serving people with blindness in China. Initial recruitment was facilitated by author CC (who is also a highly educated adult with blindness), who posted the study invitation in several WeChat groups dedicated to information exchange and community building among the population with blindness. Interested and eligible individuals were then contacted directly by the author for screening. Following their interview, initial participants were asked to refer peers in their network who also met the study criteria, thus generating the subsequent snowball sample.
A total of 12 participants were recruited for this study. In qualitative research, the sample size was determined by the principle of data saturation, not statistical generalizability. This approach is supported by findings from Guest et al [], which indicate that 12 interviews are often sufficient to reach thematic saturation in a relatively homogeneous sample. Our analysis showed a similar pattern: over 70% of themes were identified within the first 6 interviews, and the primary core themes were established by the 10th interview. To confirm saturation, 2 additional interviews were conducted, which yielded no new core themes. Therefore, the final sample of 12 participants was considered sufficient for a comprehensive analysis.
Data Collection
Semistructured interviews were conducted in Mandarin Chinese during September 2024 by 1 author (JZ), a female PhD student trained in qualitative research methods. The interviewer had no prior relationship with the participants, which helped minimize biases and address potential ethical concerns. All interviews were carried out remotely using the Tencent Meeting (Tencent Technology Co Ltd) videoconferencing platform. Tencent Meeting was selected due to the necessity for remote data collection during the COVID-19 outbreak and its status as a mainstream, accessible, and free online conferencing tool widely used in mainland China [,]. This ensured both the safety of participants and researchers and provided a familiar and convenient platform for our digitally literate participants with blindness. Before the interviews, participants were provided with detailed information about the study’s purpose, procedures, and the expected time commitment.
A topic guide with open-ended questions () was used during interviews to ensure comprehensive coverage of relevant topics and allow participants to freely elaborate on their experiences. Follow-up questions were posed as needed to clarify responses and gather more detailed information on participants’ perspectives. The interview questions were developed by reviewing the existing literature and absorbing expert opinions. To ensure validity, the guide was pretested by 2 educated adults with blindness (who were not included in the final sample) and revised based on their feedback. Participants were initially asked to share their personal background and how they became blind. Subsequently, they were prompted to describe their past and present experiences in accessing health care services, while the third part focused on the perceived benefits and challenges of using digital tools, including how such technologies empowered or hindered their access to health care. Follow-up questions were tailored to participants’ responses to encourage deeper elaboration. Finally, participants were invited to share any additional thoughts or address overlooked aspects before concluding the interview. The interviewer took field notes during the interviews to supplement the data and highlight key moments []. A total of 12 interviews were conducted, with durations ranging from 35 to 90 minutes (mean 55.0, SD 18.5). All interviews were audio-recorded with participants’ permission, transcribed verbatim, and checked by participants.
Ethical Considerations
This study received ethical approval from the Peking University Institutional Review Board (IRB00001052-22097). Due to the participants’ blindness, a verbal informed consent process was meticulously followed. Before each interview, participants were thoroughly informed about the study’s purpose, procedures, their right to withdraw at any time without penalty, the voluntary nature of their participation, and the measures taken to ensure confidentiality. Oral consent was obtained after ensuring that participants fully understood all aspects of the study, and this consent was audio-recorded as part of the interview. To protect the privacy and confidentiality of participants, strict measures were implemented. All data collected, including interview transcripts and audio recordings, were anonymized immediately upon transcription by removing direct identifiers such as names, specific locations, or any other potentially identifying information. Pseudonyms were assigned to participants to ensure their anonymity in all research outputs. All data were stored securely on password-protected university servers accessible only to the research team. Participants received compensation ranging from 60 to 100 RMB (US $8.40 to $14.00) for their time and participation. We confirm that no images or other materials that could identify individual participants are included in this paper or any supplementary materials. All procedures involving human subjects were conducted in accordance with the ethical standards of the institutional and national research committee and with the Helsinki Declaration.
Data Analysis
This study used thematic analysis, a flexible and powerful method for systematically generating robust findings by “identifying, analyzing, and reporting patterns (themes) within data” []. Following the inductive qualitative thematic analysis approach outlined by Braun and Clarke [,], our data analysis encompassed 3 phases: reading, coding, and theming, informed by practical thematic analysis guidelines [].
The reading phase commenced with the transcription of recorded interviews by 1 author (JZ), which were subsequently verified by the participants. The translated interview transcripts were then imported into the qualitative data analysis software MAXQDA 24 (VERBI GmbH) to facilitate the analytical process. During this phase, the researchers achieved extensive familiarization with the data through repeated readings.
The coding phase began with initial code development and involved a systematic and iterative process. One researcher (JZ) initiated the process by assigning descriptive codes line-by-line to segments of the interview transcripts using MAXQDA 24. These codes were generated inductively, emerging organically from a close reading of the text. They represented specific concepts, ideas, or experiences directly relevant to the study’s objectives, aiming to capture the richness of participants’ perspectives in their own words. To ensure academic rigor and reliability, a second researcher (CS) independently analyzed 30% of the uncoded interview transcripts, generating her own list of key themes without any influence from JZ. After this blind coding process, the codes were discussed and compared among all authors. Code definitions were refined, and a shared codebook was developed. This iterative process involved reviewing and revising codes, merging similar concepts, and resolving discrepancies, ultimately ensuring a comprehensive and aligned approach to the remaining data [].
The theming phase involved synthesizing these refined codes into broader, overarching themes that addressed the research questions [,]. Throughout the entire data analysis process, particular attention was paid to the concept of data saturation. Discussions regarding saturation began during the initial reading phase and continued iteratively throughout coding and theming to ensure that no new information was emerging and that the themes were well-developed and grounded in the data.
Results
Participants’ Characteristics
A total of 12 educated and digitally literate young participants with blindness were included in this qualitative study (). The average age was 25.4 (SD 2.2) years, more than half were female (7/12, 58%), and most experienced blindness from an early age (9/12, 75%; aged <6 y). Reflecting the inclusion criteria, all participants were currently pursuing or had completed higher education: 17% (2/12) held junior college degrees, while 83% (10/12) had completed or were pursuing Bachelor’s degrees or higher. In terms of occupation, 58% (7/12) were employed, with the remaining 42% (5/12) being students or unemployed. Half of the participants (6/12, 50%) resided in first-tier cities, with the remaining half evenly distributed between new first-tier or second-tier and third-tier or below cities (3/12, 25% each). The most common reasons for seeking health care were acute conditions and injury treatment (6/12, 50%), followed by chronic and skin conditions (4/12, 33%).
Table 1. Demographic information of educated young adults with blindness (N=12). Characteristics Value Age (y), mean (SD) 25.4 (2.2) Sex, n (%) Male 5 (42) Female 7 (58) Age of blindness onset (y), n (%) Congenital or early onset (0‐5) 9 (75) Acquired (>6) 3 (25) Education, n (%) Junior college 2 (17) Bachelor’s degree or higher (completed or in-progress) 10 (83) Occupation, n (%) Employed 7 (58) Students or unemployed 5 (42) Residence (city tier), n (%) First-tier 6 (50) New first-tier or second-tier 3 (25) Third-tier and below 3 (25) Primary health care visits, n (%) Acute conditions and injury treatment 6 (50) Chronic and skin conditions 4 (33) General check-ups 1 (8) Gynecological care 1 (8) Overarching Category: Experiences of Empowerment but Exclusion in Digital Health Care
Participants’ experiences navigating health care in the digital age were rich and multifaceted, consistently revealing a complex dynamic of both empowerment and exclusion. Our thematic analysis yielded 7 key themes, which are presented under 2 overarching categories: empowerment (reflecting how digital technologies enhance autonomy and access), and exclusion (highlighting persistent barriers and unmet potentials in digital health care; ).
Table 2. Overview of themes. Overarching category and theme Summary of key points identified Empowerment
Digital platforms empowering self-management and health care accessDHTs enabled participants to independently book appointments, reducing wait times and enhancing efficiency. These platforms also provided diverse and comprehensive health information, fostering self-advocacy and proactive health management. Digital platforms empowering for finding medical visit companions DHTs facilitated the discovery of medical companions, improving access to services and fostering a sense of independent navigation. This assistance provided both physical navigation and emotional support during hospital visits. Exclusion Inaccessible online appointment systems Online appointment systems often lacked inclusive booking options and featured cluttered interfaces not optimized for screen readers, limiting access for individuals with blindness despite the general shift to digital platforms. Inaccessible health care environments and information formats The absence of accessible interfaces on self-service machines (eg, for check-in, payment, and prescription pickup) and the lack of accessible formats for written materials (eg, laboratory reports) created significant barriers within hospital environments. Lack of provider competencies in respecting patient autonomy Provider assumptions of digital incompetence led to communication being directed at sighted companions, undermining patient autonomy and reinforcing stereotypes, despite patients’ digital literacy. Data privacy and security concerns The increased digitalization of health services heightened concerns over data breaches, making privacy harder to maintain. Complex interfaces and the use of voice-based assistive tools in public settings further complicated privacy management. Challenges related to the quality and consistency of online companion support While enabling, reliance on online platforms for companions introduced specific challenges related to the inconsistent quality and limited capabilities of support, often lacking emotional connection and accountability. aDHT: digital health technology.
Empowerment: Digital Technologies Fostering Access
Digital Platforms Empowering Self-Management and Health Care Access
All 12 participants in this study demonstrated a high level of digital engagement, routinely using smartphones and screen reader technology to overcome accessibility challenges in daily life, extending their digital practices into areas such as information seeking, learning, and social interaction. The most frequently used applications include WeChat, Rednote (xiaohongshu in Chinese), TikTok (Douyin in Chinese), Bilibili, and Xianyu, which are popular platforms in China for social networking, content sharing, and e-commerce. This digital proficiency directly translated into enhanced health care engagement.
Participants reported using digital platforms to access health care services and information, including managing appointments and consulting health-related content online. In participants’ views, digital platforms offer two key advantages: (1) they provide a wealth of diverse and comprehensive information, surpassing traditional word-of-mouth referrals; and (2) they enable users to access this information with temporal and spatial flexibility, offering greater convenience compared to time- and location-bound methods. This enhanced access to information did more than improve convenience; it facilitated a fundamental shift from passive reliance on others to proactive self-advocacy. Participants perceived this newfound ability to independently seek out and act on information as a powerful form of self-expression and a significant gain in personal freedom. For instance, one participant described how digital platforms enabled her to proactively seek mental health support tailored to her needs:
I posted on Rednote saying that I am blind and looking for a psychiatrist who does not discriminate against me, and I received several responses from supportive individuals. This made me feel that I no longer need constant attention from my parents or those around me, as I can proactively seek information and help online.
[Participant ZX, female, 22 years]For those with acquired vision loss (ie, vision loss that occurs after birth due to accidents, disease, or other environmental influences), the internet served as a crucial lifeline to rebuild life trajectories. As formal medical guidance on rehabilitation was often lacking, online patient communities and peer networks are usually the last resort of comfort:
Doctors usually just said, ‘there’s no treatment,’ and offered little else. It was other patients—people I met online or in hospitals—who told me about schools for the blind, massage training, or what assistive devices to get.
[Participant CT, male, 30]Compared to traditional hospital appointment scheduling that requires in-person visits, online appointment scheduling systems have greatly improved health care access by allowing patients to register remotely via hospital WeChat Official Accounts (inside WeChat). Real-time updates offer patients more control over scheduling, allowing them to easily find alternative hospitals with available appointments.
Now, all tertiary hospitals have fully implemented online appointment systems, which is more convenient for blind people like us who could frequently use smartphones. I always make appointments through the hospital’s WeChat Official Account before seeing a doctor.
[Participant ML, female, 27 years]Digital Platforms Empowering for Finding Medical Visit Companions
Hospital visits without assistance posed significant challenges for individuals with blindness, sometimes leading to delays in seeking necessary health care. For people with blindness without family or friends nearby, digital platforms offer a potential solution by connecting them with volunteer networks or organizations providing paid medical visit companions (MVCs). All participants reported benefits when receiving assistance from MVCs, as the presence of a companion alleviated anxieties and provided a sense of security throughout their hospital journey.
In the past, I would often delay medical visits because I felt overwhelmed by the hospital environment and often leave the hospital feeling that I had not addressed all my concerns, simply because I was too anxious to ask questions. When I was in Hangzhou, I began using Xianyu around one year ago to find companions. Over the past year, I have used this service a few times to arrange for someone to accompany me during medical appointments. I searched for keywords like ‘medical visit companions services’ and found options where individuals offered accompaniment services. They took me from home to the hospital and back, with charges from 30 to 80 yuan per hour. Having someone with me allows me to ask the right questions and make sure my issues are resolved.
[Participant RL, male, 26 years]These insights highlight the empowering role that MVCs play in fostering both physical navigation and emotional support, making it easier for individuals with blindness to take charge of their health care. Through the combination of technological access and personal support, participants can be more engaged with their health care providers, which significantly improves health care seeking experience and their health outcomes.
Exclusion: Persistent Barriers and Unmet Potentials in Digital Health Care
Inaccessible Online Appointment Systems
A significant challenge reported by participants was how the shift to digital platforms, while offering convenience, simultaneously erected new and formidable barriers. This dual reality was aptly summarized by a participant who noted:
Online registration/payment has made things more convenient, but there’s still a lot that’s not working.
[Participant HY, female, 24 years]This gap was particularly evident where digital platforms, despite offering convenience, featured designs that created new exclusionary hurdles. For instance, many hospital WeChat Official Accounts, while the primary channel for online appointments, presented cluttered interfaces with complex layouts and images not optimized for screen readers. This poor usability hindered navigation and undermined informed decision-making, as 1 participant explained:
Each hospital has its own WeChat Official Account, and they differ from one another. The interface is complex, and the buttons are not designed with focus settings. This inaccessibility prevents me from accessing relevant information, thereby impacting my healthcare decision-making.
[Participant CY, female, 24 years]Inaccessible Health Care Environments and Information Formats
Participants reported that complex hospital environments remain highly challenging to navigate. Standardized accessibility features—such as Braille indicators in elevators, poorly designed tactile paths, and the lack of auditory cues in key areas—are commonly not available yet. More critically, the increasing digitalization within hospitals often introduced new barriers or failed to mitigate existing physical ones.
For example, written materials such as laboratory reports, discharge records, and prescriptions are printed on paper without accessible formats like Braille or large print, making it difficult to understand and hindering patients with blindness from accessing vital information about their diagnosis and treatment. One participant expressed frustration:
Even when I get my laboratory report and discharge record, they’re just regular paper printouts with no way for me to read them independently. I feel like I’m missing out on important information, and it’s frustrating.
[Participant NX, female, 24 years]Moreover, hospitals are increasingly relying on touchscreen-based self-service machines for tasks like registration, payment, and report retrieval, which are often inaccessible to people with blindness due to the lack of screen reader compatibility. A participant reflected on this challenge:
These machines have no screen reader compatibility, so I always need someone to briefly help me retrieve my reports.
[Participant ZY, male, 26 years]Lack of Provider Competencies in Respecting Patients’ Autonomy
Many participants indicated the lack of provider competencies in respecting their autonomy, the challenge that gained particular salience within the increasingly digitized health care landscape. Specifically, a pervasive issue identified was the default assumption among many health care providers that patients with blindness lack digital literacy or the ability to independently engage with digital platforms. In an age where digital tools are designed to empower patients with greater access to information and enhanced self-management capabilities, the lack of corresponding adaptation or improvement in provider communication creates a jarring and disempowering contrast. Consequently, while most health care providers display positive attitudes, they often lack the necessary skills to effectively engage with patients who are blind. This knowledge gap can lead to communication barriers, undermining the autonomy that technology aims to support. In extreme cases, some health care staff seem to view patients with blindness as objects of curiosity rather than patients in need of medical care. A participant summed up such experiences:
Sometimes doctors ask irrelevant questions, like ‘Can you talk?’ or ‘Can you hear?’ as if they are observing an unfamiliar species instead of treating a patient. These kinds of questions only reinforce the communication barriers and make me feel like I’m not being taken seriously as a person in need of medical care, but rather as an object of curiosity.
[Participant RL, male, 26 years]This lack of provider competencies is also reflected in the fact that health care providers often address the sighted companion instead of the patient with blindness during visits, despite the patient’s digital literacy and capacity for self-advocacy. Participants reported frequent occurrences where providers directed questions and communication to the companion, assuming they were unable to independently communicate or make decisions. One participant noted:
Whenever I have a companion, the doctor naturally chooses to speak to them instead of me. Even after repeatedly reminding the doctors that I am the patient and should be the one answering questions, they still act as if I am incapable of engaging in a normal conversation. It’s frustrating and undermines my autonomy.
[Participant ML, female, 27 years]Data Privacy and Security Concerns
In the digital age, concerns regarding data privacy and information security are exacerbated for individuals with blindness, who often rely on assistive technologies and other forms of support in accessing health care. These vulnerabilities are not limited to physical interactions with medical staff but extend to broader digital infrastructures, including health platforms, mobile apps, and the public environments where these technologies are used.
Participants consistently expressed difficulties in independently navigating privacy settings or understanding consent-related information embedded within digital health applications. Complex interfaces, inaccessible terms of service, and a lack of screen reader-compatible designs hinder the ability of these individuals to make informed choices. As a participant noted:
Sometimes I just agree to everything because I can’t really read the privacy policy with the screen reader. The text layout is all over the place, and I’m not even sure what I’m consenting to.
[Participant WQ, female, 27 years]Moreover, the use of voice-based assistive tools in public or semipublic settings presents distinct privacy risks. Given that these tools often verbalize sensitive health information, individuals in proximity may inadvertently overhear confidential data. This issue is further complicated by the involvement of MVCs, who assist with tasks such as navigating digital platforms, completing forms, or managing payments. While such assistance is often essential, it can inadvertently compromise the individuals’ sense of privacy and control. As 1 participant expressed:
Having a companion can be helpful, but sometimes I still prefer to visit alone because there are certain things I don’t want others to know. Even if I ask the volunteer to keep the information confidential and not disclose it, I still don’t feel comfortable because they have to help with payments and other tasks, and I end up feeling like I have no privacy.
[Participant CT, male, 30 years]Challenges Related to the Quality and Consistency of Online Companion Support
While digital platforms offered new avenues for finding companions, this also introduced specific challenges related to the quality and consistency of support. Participants expressed concerns about the inconsistent experience and limited capabilities among MVCs, particularly regarding mobility assistance and understanding patient needs. Digital platforms often facilitated one-time interactions that lacked emotional connection and accountability, leading to varied and sometimes unreliable support:
That volunteer is in such a rush to finish his task and go home that he barely listens to what I need. There were times when I had to repeat myself multiple times just to get basic assistance.
[Participant YN, female, 27 years]In summary, the findings highlight a complex and often contradictory landscape for educated and digitally literate young people with blindness accessing health care in the digital age. While digital platforms offer significant opportunities for empowerment in areas like appointment booking and companion support, these benefits are consistently counterbalanced by pervasive challenges such as inaccessible interfaces, systemic gaps in provider competence, and exacerbated privacy concerns. This dual reality of simultaneous empowerment and exclusion underscores the heterogeneous nature of the digital divide within vulnerable populations.
Discussion
Principal Findings
To the best of our knowledge, this qualitative study is the first to specifically explore the health care experiences of educated and digitally literate young people with blindness in China within the context of the rapidly evolving digital health landscape. Our findings reveal an “empowered but excluded” dynamic, a paradox that vividly illustrates the lived reality of young people with blindness as a digitally native yet vulnerable generation. On one hand, participants demonstrated that DHTs and online platforms served as valuable tools, empowering them in self-managing their health conditions, proactively accessing health care information, and efficiently finding MVCs. On the other hand, this potential for digital empowerment and enhanced independence was significantly undermined by persistent and systemic barriers. These included reduced offline access to essential services, inaccessible digital and physical health care interfaces, a pervasive lack of provider competencies in respecting patients’ autonomy within a digital context, and heightened concerns regarding data privacy and security exacerbated by digital interactions.
Comparison With Prior Work: Empowerment
Our findings corroborate existing literature on the empowering potential of DHTs for individuals with visual impairments. Participants’ ability to effectively use online platforms for appointment booking and to access a wealth of diverse and comprehensive health information aligns with previous research highlighting improved self-management and enhanced health literacy through digital tools [-]. The increased autonomy and freedom participants reported, stemming from their capacity to proactively seek information and support, resonates with the broader discourse on patient empowerment in the digital age [-]. This study extends these insights by specifically demonstrating how educated individuals with blindness, through their active engagement with screen reader technology and other digital tools, convert these opportunities into tangible benefits, challenging simplistic narratives of universal exclusion. The use of online patient communities and peer networks to fill gaps in formal medical guidance, particularly for those with acquired vision loss, further underscores the internet’s role as a crucial lifeline and a source of social support.
A distinctive contribution of this study is the exploration of digital platforms for finding MVCs. While the importance of companions for individuals with blindness in navigating health care is well-documented [], the use of online platforms (such as Xianyu in China) to locate and coordinate such support represents an innovative, user-driven adaptation. This strategy allows for greater independence in arranging assistance, improving the overall health care–seeking experience, an area previously underexplored in digital health literature.
Comparison With Prior Work: Exclusion
Despite the empowering potential of DHTs, our participants’ experiences reveal a profound exclusion shaped by persistent technological disaffordances, provider interactions that often disregard patient autonomy, and digital privacy concerns, which collectively hinder their independent and equitable health care engagement. Our findings align with prior research showing that many digital health platforms remain largely inaccessible to users with blindness and low vision [,]. This inaccessibility manifests in specific barriers, including websites that fail to meet accessibility standards, visual-centric data displays, and complex interfaces that do not accommodate screen readers or alternative input methods [-]. These limitations are not just technical oversights but reflect a broader systemic neglect of the needs of people with disabilities in the design and development process.
Furthermore, our study highlights how the interaction between digital and nondigital environments can amplify existing inequalities. Beyond technological inaccessibility, participants frequently encountered health care providers who failed to recognize and respect their autonomy. This finding is consistent with previous research which shows that health care providers may hold stereotypes or paternalistic assumptions about persons who are blind, leading to exclusionary communication practices and undermining patient-centered care [,]. Our study adds to this discourse by illustrating how relational autonomy—a framework that emphasizes the importance of direct, respectful communication and the clinician-patient relationship as central to support patients’ identities and capabilities [-]. When providers fail to engage patients with blindness as active participants in their care, it not only erodes trust but also reinforces structural inequities [,].
Finally, our findings align with previous research showing that digital privacy poses unique challenges for users with blindness, extending beyond standard concerns about data breaches. When using visual assistance technologies or sharing sensitive data, they may be unable to independently verify what information is being disclosed [,]. This complexity of privacy for users with blindness is tightly interwoven with issues of accessibility, autonomy, and trust. Our study’s contribution lies in showing the compounded effect of these factors on young individuals with blindness in China, revealing that digital empowerment is fragile and easily overridden by systematic barriers within the health care environment.
Implications for Practice and Policy
To address the systematic barriers identified in this study and improve the health care experiences of young people with blindness, we propose the following feasible policy and practical implications.
First, developers and policymakers must enforce adherence to established accessibility standards. For web-based platforms, this includes the Web Content Accessibility Guidelines []. However, as health care services increasingly migrate to mobile apps, it is equally critical to incorporate mobile-specific accessibility guidelines, such as Apple’s Human Interface Guidelines for accessibility []. Research shows that compliance is often partial; therefore, involving users with disabilities directly in a co-design process is critical for identifying specific needs, such as intuitive navigation, accessible onboarding, and the use of clear language [].
Second, medical education and professional training must be enhanced. Evidence shows that structured communication skills training improves health care professionals’ self-efficacy and performance, leading to more effective and empathetic patient interactions. To address the biases reported by our participants, these training programs must include strategies to help providers recognize and mitigate unconscious bias related to disability, incorporating the perspectives of marginalized patient groups into the training design [-].
Thirdly, robust and accessible privacy controls are needed. Individuals with blindness require privacy information and controls that are both accessible and understandable, emphasizing the need for clear, multi-modal communication and cross-platform compatibility in privacy tools. The development and implementation of accessible authentication methods, such as Braille passwords or universally usable verification tools, should be prioritized.
Finally, it is crucial to empower young individuals with blindness by building their capacity for self-determination. Organizations led by and for individuals with blindness play a pivotal role in this process by equipping them with self-advocacy and daily living skills []. In the Chinese context, while organizations like the China Disabled Persons’ Federation provide foundational services [], nongovernmental organizations such as the Golden Cane, the Beijing Hongdandan Cultural Service Center, and the One Plus One Disability Charity Group are vital in promoting rights advocacy and independent living skills [-]. A notable gap remains in dedicated health care navigation training programs that integrate digital literacy for e-health services. Closing this gap is essential to ensure young blind individuals in China can fully leverage digital health advancements.
Strengths, Limitations, and Future Research
This study’s primary strength lies in its novel contribution to understanding the health care experiences of a previously overlooked subgroup: young, educated individuals with blindness in China. By focusing on this specific demographic, our research offers three key contributions. First, it challenges the homogeneous view of vulnerable groups by demonstrating that high-literacy individuals possess unique capabilities and face distinct challenges within the digital ecosystem. Second, it introduces and evidences the “empowered but excluded” paradox, providing a nuanced theoretical framework that moves beyond a simple narrative of digital exclusion. It shows that empowerment and exclusion are not mutually exclusive but coexist, shaped by the interplay between individual agency and systemic barriers. Third, this framework helps distinguish which challenges can be mitigated through individual effort and digital literacy versus those that require fundamental changes in policy, technology design, and clinical practice. The qualitative depth provides rich, contextualized insights that explain how and why these dynamics manifest, laying the groundwork for tailored interventions.
This study has several limitations. As a qualitative study, the findings are based on a small sample of 12 educated young individuals with blindness in China and may not be generalizable to other age groups, cultural contexts, or countries with different health care and digital infrastructures. The recruitment strategy may have introduced selection bias, potentially attracting participants with more pronounced positive or negative experiences with DHTs. Furthermore, participant recall bias might have influenced their accounts of past health care experiences. Despite these limitations, this study offers rich, contextualized insights into the lived experiences of a typically underrepresented group in digital health research. Future research should explore these issues with larger, more diverse samples, potentially using quantitative or mixed-methods approaches to assess the prevalence of the themes identified and to evaluate the effectiveness of interventions aimed at improving health care accessibility and autonomy for people with blindness in the digital age. Comparative studies across different socioeconomic and cultural settings would also be beneficial.
Conclusions
This study explored how educated young adults with blindness in China navigate health care in the digital age, revealing an “empowered but excluded” dynamic. The potential for digital empowerment and enhanced independence, though present, is consistently curtailed by systematic barriers including inaccessible technologies, provider practices that limit patient autonomy, and privacy vulnerabilities. To bridge this gap, our findings underscore the necessity of a multifaceted approach: enhancing technological accessibility through robust standards adherence and inclusive co-design processes; improving health care provider competencies in patient-centered care via targeted training; and empowering young individuals with blindness by building their capacity for self-determination. Implementing these integrated strategies is vital for realizing equitable health care access and true independence for this digitally native yet vulnerable generation.
The authors would like to express our sincere gratitude to all the participants for their courage and openness in sharing their experiences, and to the key informants for contributing their valuable perspectives.
This work was supported by the National Natural Science Foundation of China (grant number 72442021) and the University of Chinese Academy of Social Sciences Innovation Fund (grant number 2025-KY-077). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
The data supporting this study are available upon reasonable request from the corresponding author.
All authors contributed to the paper and approved the final submitted version.
None declared.
Edited by Alicia Stone, Amaryllis Mavragani; submitted 24.Jun.2025; peer-reviewed by Kabelo Leonard Mauco, Soyoung Choi; final revised version received 22.Oct.2025; accepted 23.Oct.2025; published 21.Nov.2025.
© Junling Zhao, Can Su, Xiji Zhu, Cong Cai, Wei Liu, Xiaochen Ma. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 21.Nov.2025.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work, first published in the Journal of Medical Internet Research (ISSN 1438-8871), is properly cited. The complete bibliographic information, a link to the original publication on https://www.jmir.org/, as well as this copyright and license information must be included.
Continue Reading