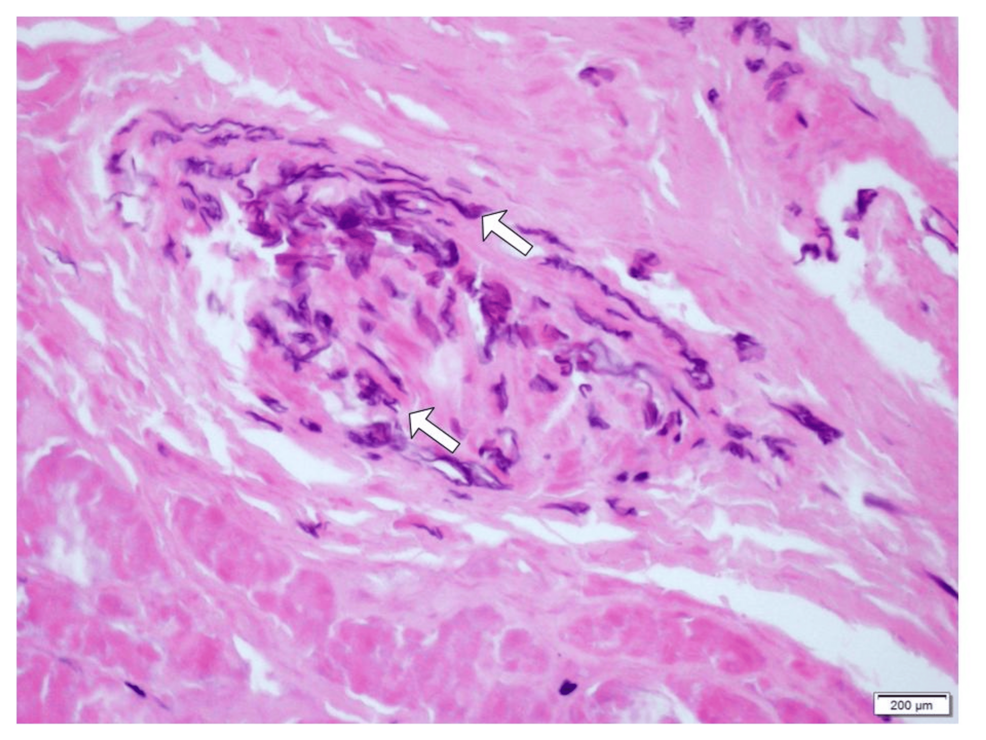
The U.S. Department of Health and Human Services (HHS) announced a label change for menopausal hormone therapies (MHT) or hormone replacement therapies (HRT) following an FDA request. The agency demanded the removal of broad “black box”…
Category: 6. Health
-
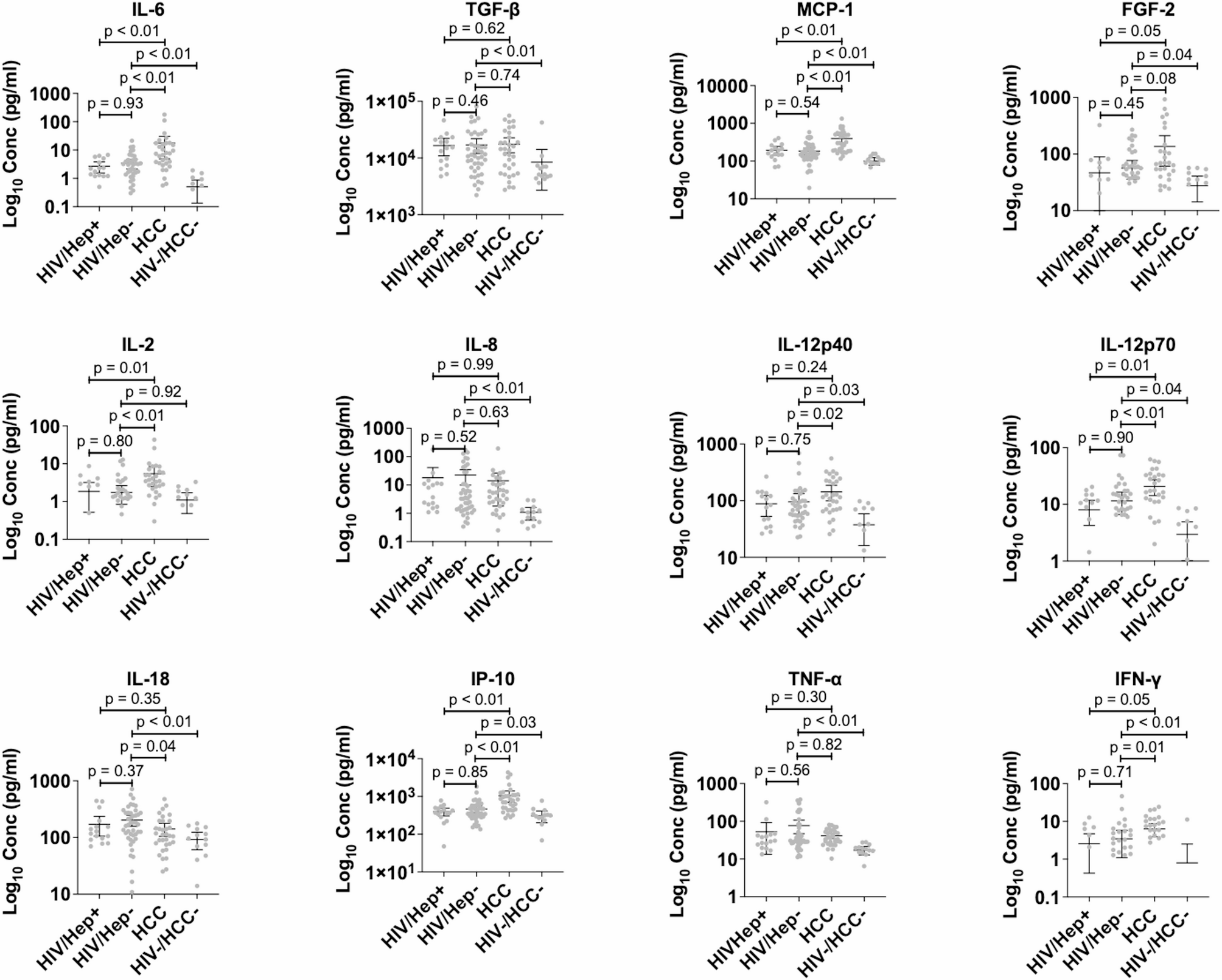
Concordance of cancer-associated cytokines and mitochondrial DNA deletions in individuals with hepatocellular carcinoma and people living with HIV in Ghana | BMC Gastroenterology
Bower M, Palmieri C, Stebbing J. AIDS associated malignancies. Update Cancer Ther. 2006;1(2):221–34.
Franceschi S, Lise M, Clifford GM, Rickenbach M, Levi F, Maspoli M, et al. Changing patterns…
Continue Reading
-
Just a moment…
Just a moment… This request seems a bit unusual, so we need to confirm that you’re human. Please press and hold the button until it turns completely green. Thank you for your cooperation!
Continue Reading
-

Association between sodium–chloride difference at ICU admission and 30-day mortality: a retrospective cohort study of critically ill adults | BMC Anesthesiology
In this study, we investigated the prognostic value of the SCD in a population of critically ill patients admitted to the ICU. Our findings demonstrated a non-linear relationship between SCD values and 30-day mortality, with an elevated risk of…
Continue Reading
-
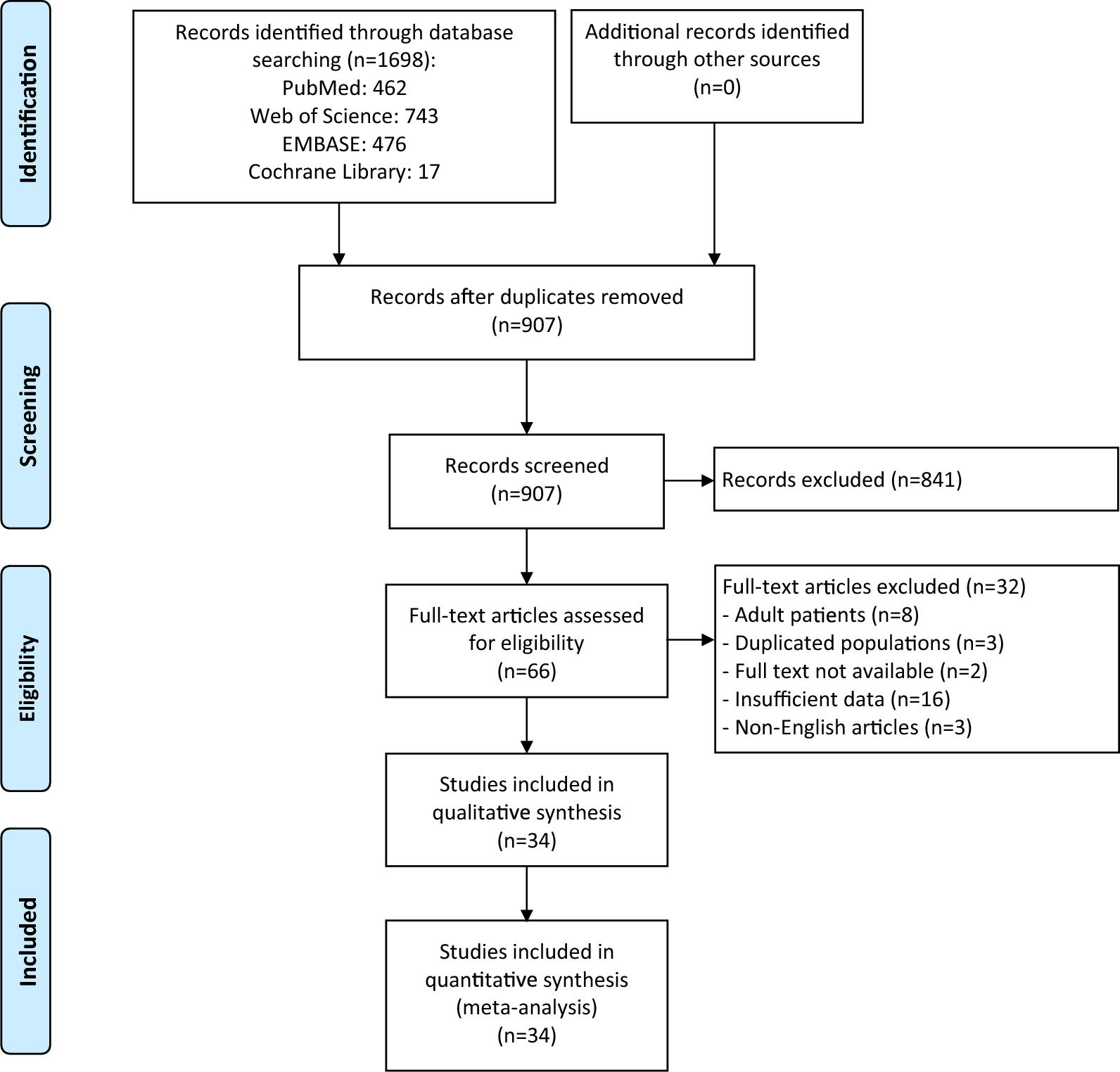
Risk factors for avascular necrosis in pediatric femoral neck fractures: a systematic review and meta-analysis | Journal of Orthopaedic Surgery and Research
Baseline characteristics of studies included in the meta-analysis
The comprehensive literature search identified 1698 articles, of which 907 unique article remained after removing duplicates (Fig. 1). Following title and abstract screening, 841…
Continue Reading
-

Genetic testing trifecta predicts risk of sudden cardiac death and arrhythmia: For Journalists
- Novel study used whole genome sequencing to combine monogenetic and polygenetic testing, which are often siloed in research and practice
- More physicians should order genetic testing but much…
Continue Reading
-
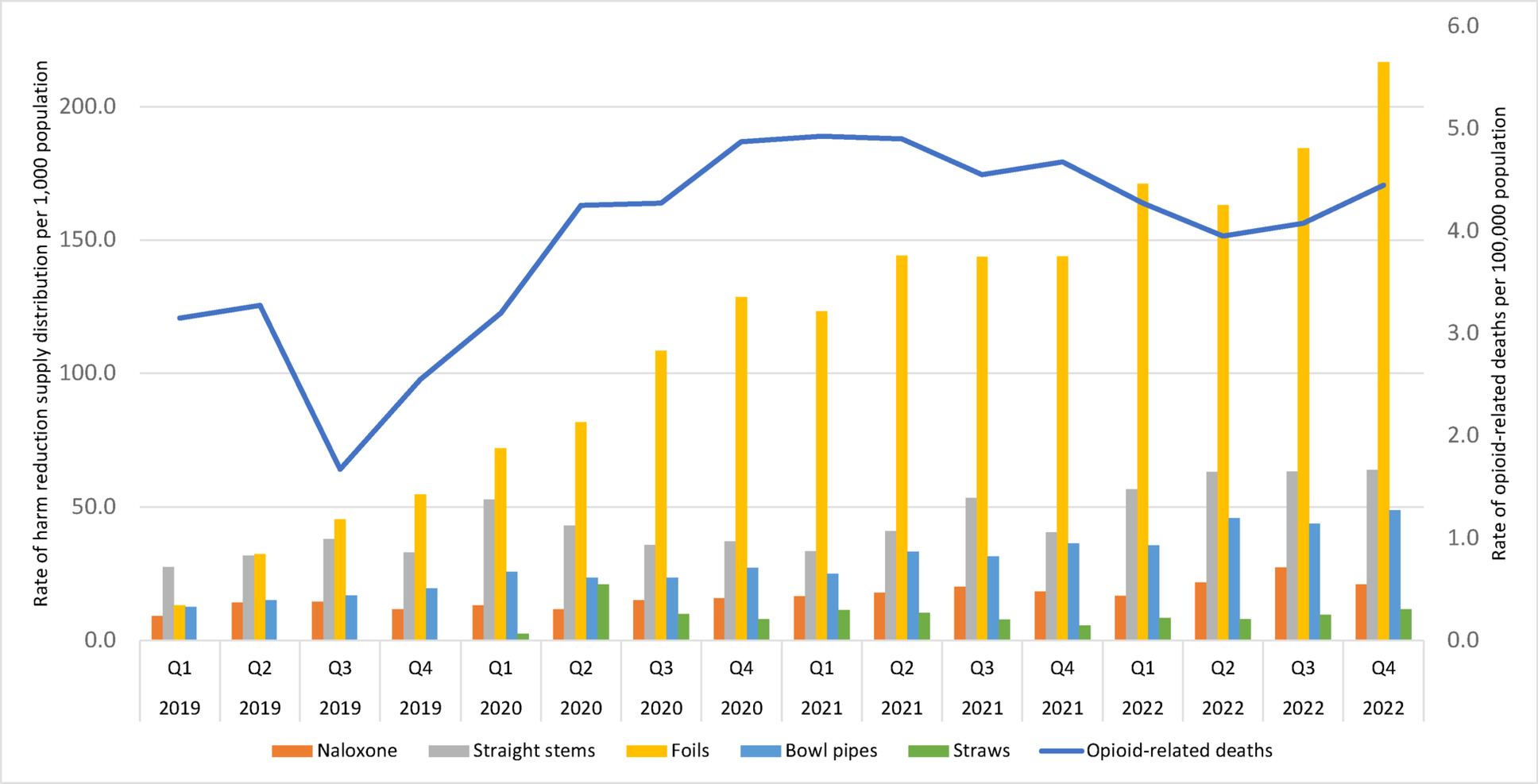
Exploring disparities: a regional analysis of harm reduction supply distribution and opioid-related deaths across Ontario’s Public Health Units | Harm Reduction Journal
Over a three-year period, the distribution rates of harm reduction supplies increased dramatically across Ontario, in parallel with growing rates of opioid-related deaths. We observed substantial variation across PHUs in rates of opioid-related…
Continue Reading
-
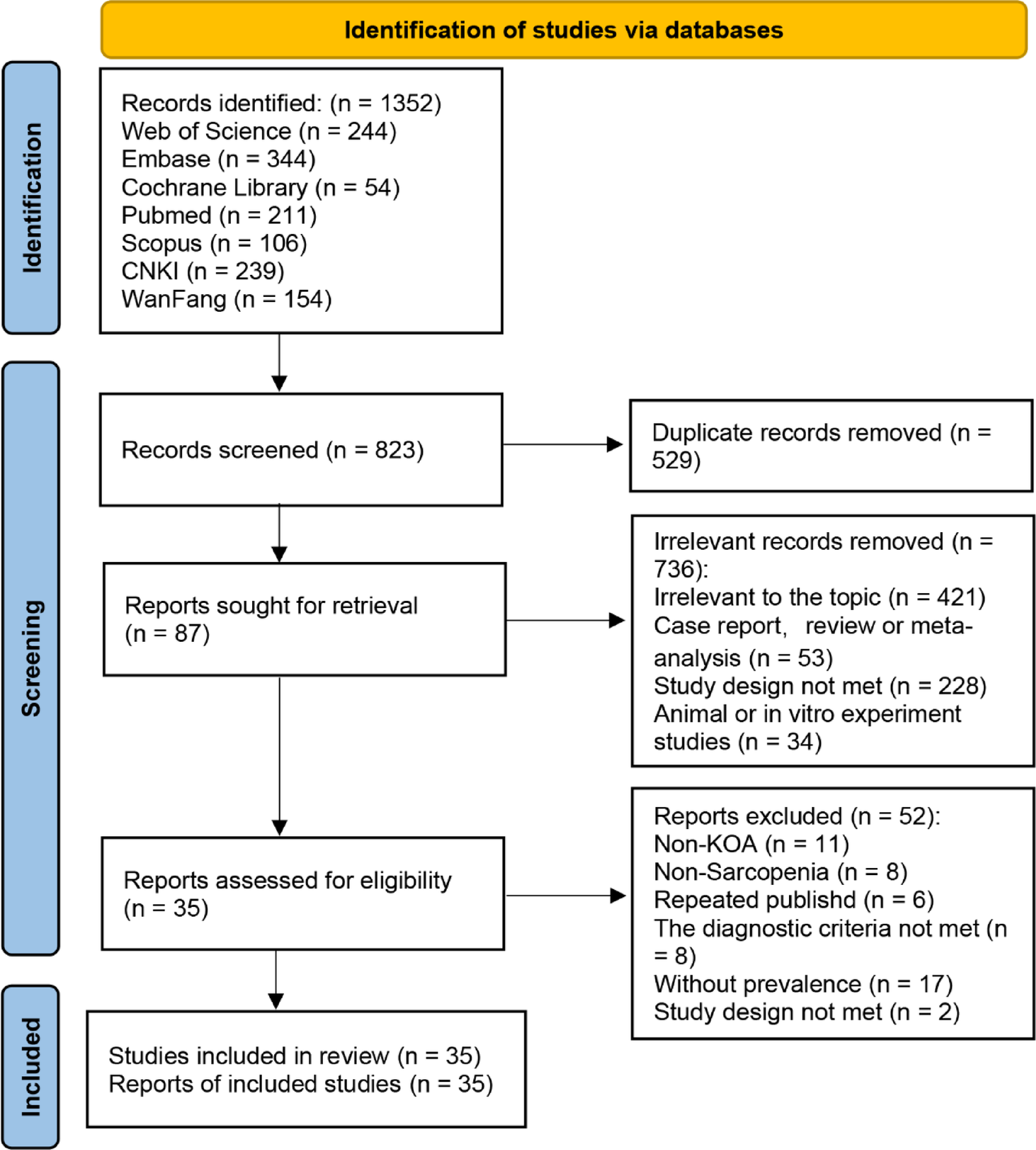
High prevalence and multifactorial risks of sarcopenia in knee osteoarthritis: a systematic review and meta-analysis | Journal of Orthopaedic Surgery and Research
Chen TX, Zhang ZL, Zhu YQ, et al. Bibliometric analysis of the relationship between osteoarthritis and osteoporosis: a global perspective on current research trends and hotspots. Asian J Surg. 2024;47(11):4973–4.
…
Continue Reading
-
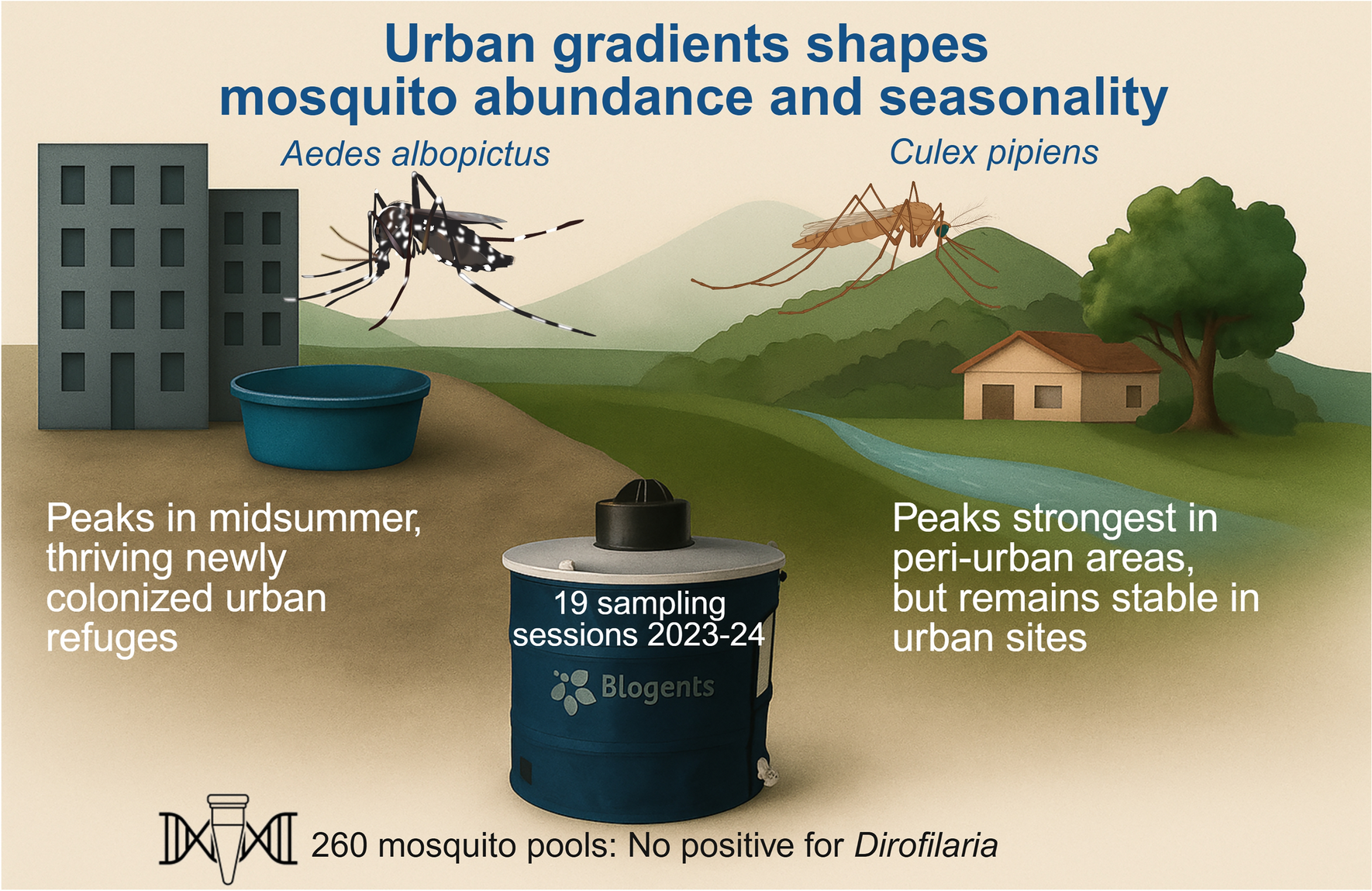
Mosquitoes and the city: effects of urbanization on Aedes albopictus and Culex pipiens captures in southern Spain | Parasites & Vectors
Lowe S, Browne M, Boudjelas S, De Poorter M. 100 of the world’s worst invasive alien species. A selection from the global invasive species database. The invasive species specialist group (ISSG), 12 p; 2000.
Continue Reading